自己ヒント言語モデルが強化学習を強化する
大規模言語モデルの強化学習において、難易度の高い問題で正解が全く得られず学習が停滞する「アドバンテージの崩壊」を解決するため、訓練時のみ「特権的なヒント」を導入する新手法「SAGE」が提案されました。
TL;DR(結論)
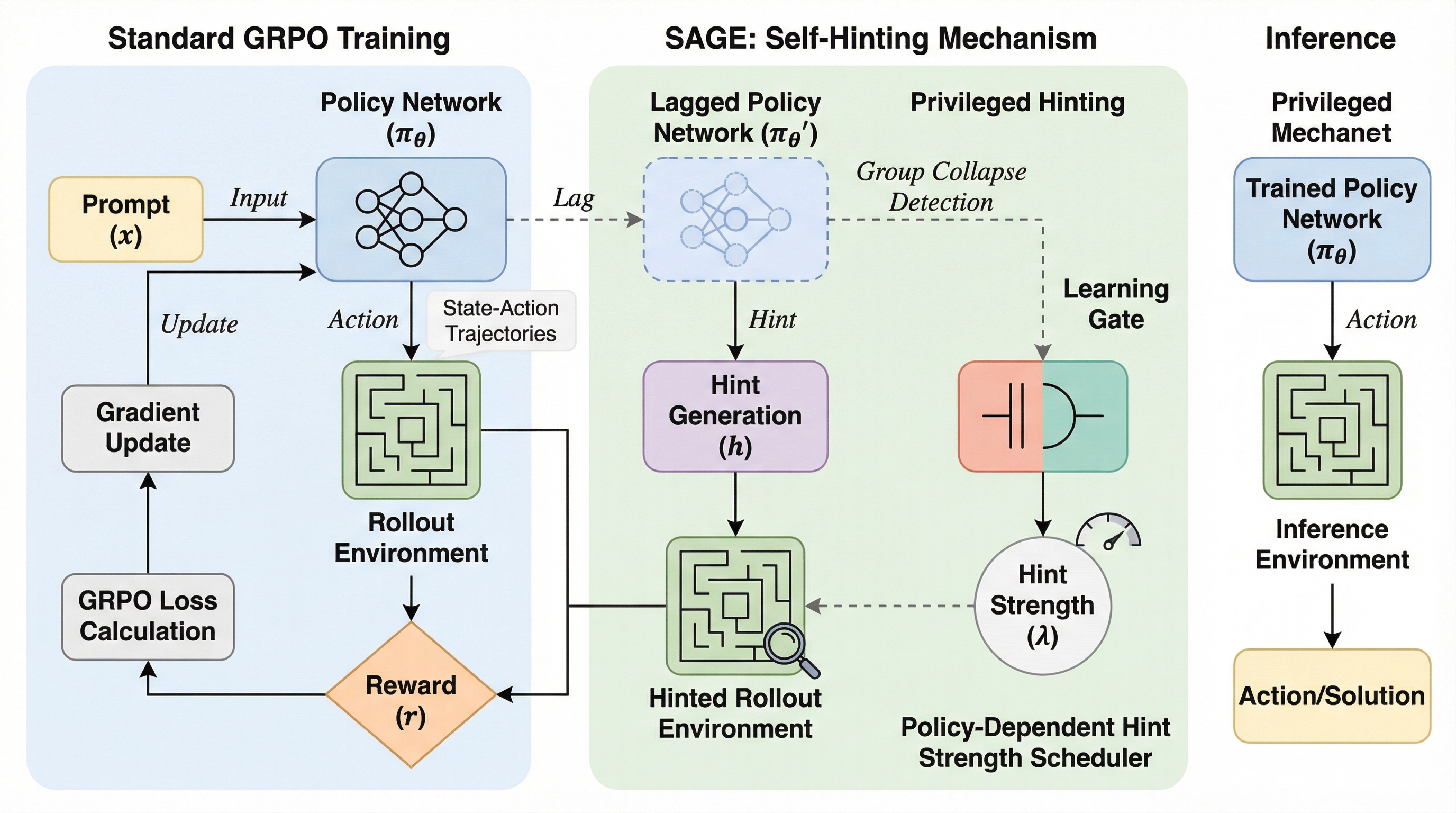
大規模言語モデルの強化学習において、難易度の高い問題で正解が全く得られず学習が停滞する「アドバンテージの崩壊」を解決するため、訓練時のみ「特権的なヒント」を導入する新手法「SAGE」が提案されました。 この手法は、正解データから生成した簡潔な計画などのヒントをモデル自身に生成させ、サンプリング時の正解率を意図的に調整することで、学習信号が消失する状態を回避しつつ、推論時にはヒントなしで高い性能を発揮させることを可能にします。 LlamaやQwenなどの主要な言語モデルを用いた実験では、数学や推論のベンチマークにおいて従来の手法を安定して上回り、特にモデルの成長に合わせてヒントを動的に更新する「オンライン自己ヒント」が、学習の停滞を打破する上で極めて効果的であることが示されました。
なぜこの問題か
大規模言語モデル(LLM)を特定のタスク、特に数学の解答やコードのユニットテストといった「正解が客観的に検証可能なタスク」に適合させる際、強化学習(RL)は非常に強力な手法となります。近年では、計算効率の高さからグループ相対方策最適化(GRPO)という手法が広く採用されています。しかし、この手法には「報酬の稀薄さ」に対して極めて脆弱であるという、実用上の大きな課題が存在します。GRPOの仕組みは、同じ入力プロンプトに対して複数の回答(ロールアウト)を生成し、そのグループ内での相対的な報酬の差を利用してモデルを更新するというものです。しかし、非常に難易度の高い問題に直面した場合、生成されたすべての回答が不正解(報酬がゼロ)になってしまうことが頻繁に起こります。 このようにグループ内のすべての回答が同じ報酬(すべてゼロ、あるいは稀にすべて正解)を受け取ると、相対的な優位性を示す「アドバンテージ」が計算上ゼロになり、モデルを更新するための学習信号が完全に消失してしまいます。本論文では、この現象を「アドバンテージの崩壊(Advantage Collapse)」と定義しています。…
核心:何を提案したのか
本論文が提案するのは、特権的な監視を伴う自己ヒント整列GRPO、通称「SAGE(Self-hint Aligned GRPO with Privileged Supervision)」という新しいフレームワークです。この手法の核心的なアイデアは、訓練時にのみ「ヒント」という追加情報をモデルに与えることで、サンプリングの分布を意図的に作り変え、正解が含まれる確率を最適化する点にあります。ここで用いられるヒントは、正解の軌跡(リファレンス・ソリューション)を「損失のある圧縮(Lossy Compression)」にかけたものです。具体的には、最終的な答えにたどり着くための簡潔な計画や、問題を解くためのステップごとの分解などがヒントとして機能します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related