量子化進化戦略:低精度のコストによる量子化LLMの高精度なファインチューニング
大規模言語モデル(LLM)のメモリ消費を抑えるポストトレーニング量子化(PTQ)モデルは、離散的かつ非微分的な性質から微調整が困難でしたが、本研究は信号処理のデルタ・シグマ変調に着想を得た「量子化進化戦略(QES)」を提案し、全パラメータの直接更新を可能にしました。
TL;DR(結論)
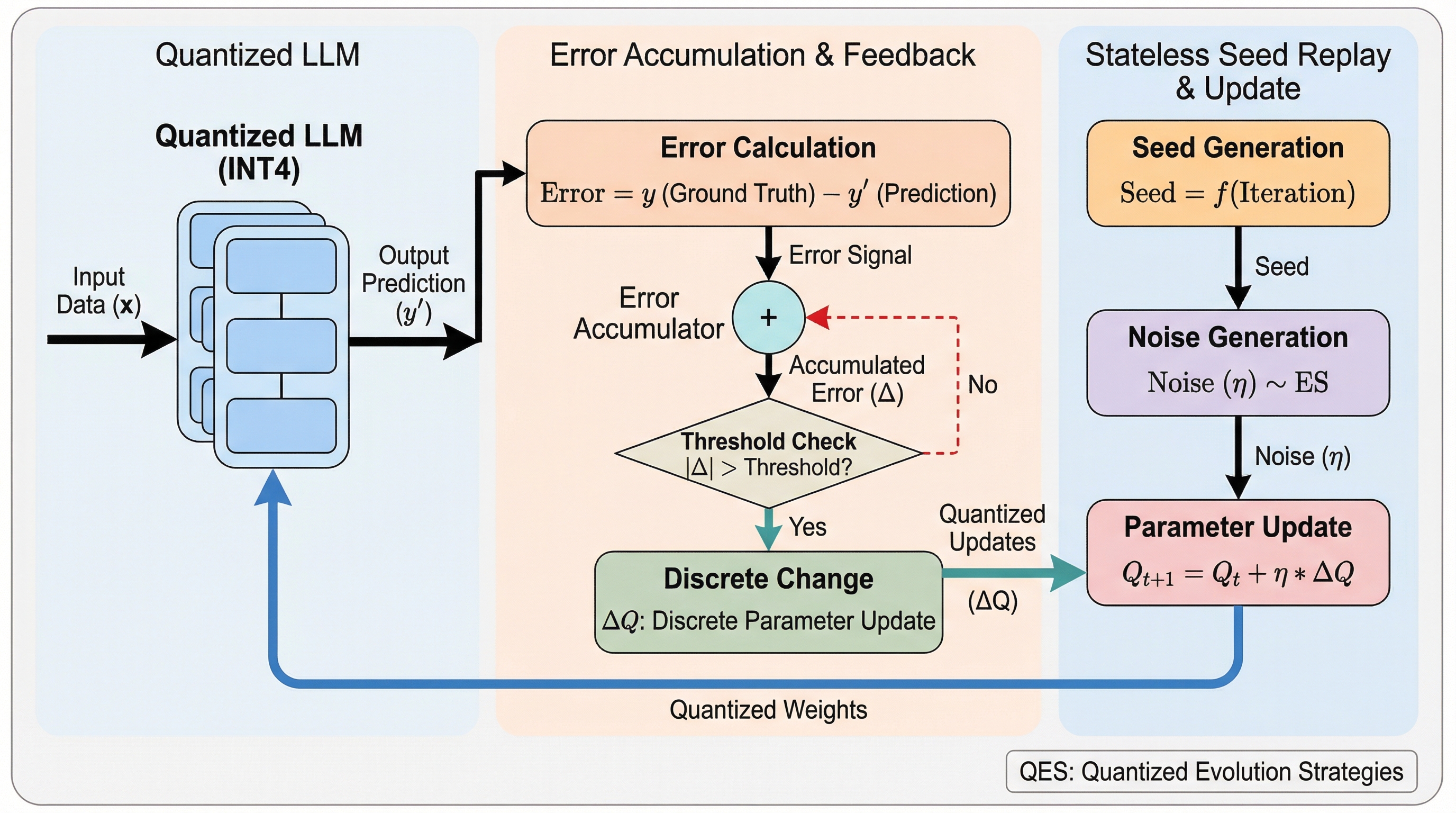
大規模言語モデル(LLM)のメモリ消費を抑えるポストトレーニング量子化(PTQ)モデルは、離散的かつ非微分的な性質から微調整が困難でしたが、本研究は信号処理のデルタ・シグマ変調に着想を得た「量子化進化戦略(QES)」を提案し、全パラメータの直接更新を可能にしました。 QESは、微小な勾配信号を切り捨てずに蓄積する「累積誤差フィードバック」と、過去の最適化状態を乱数のシードからオンザフライで再構築する「ステートレス・シードリプレイ」を組み合わせることで、推論時と同等の極めて低いメモリ消費量での学習を実現しています。 算術推論タスクを用いた検証では、既存の零次最適化手法であるQuZOを大幅に上回る正解率を記録し、特にINT4のような超低精度な量子化設定においても、ベースモデルの数倍に及ぶ劇的な性能向上を達成できることが実証されました。
なぜこの問題か
大規模言語モデル(LLM)のスケールアップは、数学的推論やコーディングといった複雑なタスクにおいて驚異的な能力をもたらしましたが、その実行には膨大な計算リソースとメモリが必要となります。このメモリのボトルネックを解消するために、重みを3ビットや4ビットに圧縮するポストトレーニング量子化(PTQ)が標準的な手法として普及しました。SmoothQuantやGPTQ、AWQといった技術により、消費者向けのハードウェアでも大規模なモデルの推論が可能になりましたが、量子化されたモデルは本質的に「静的」な存在であり、特定のタスクに合わせて後から微調整(ファインチューニング)を行うことが非常に困難であるという課題がありました。 従来のファインチューニング手法、特に強化学習(RL)を含む標準的なパラダイムは、誤差逆伝播(バックプロパゲーション)と高精度な重みに依存して勾配を計算します。しかし、量子化されたモデルのパラメータ空間は離散的で非微分的であるため、これらの手法を直接適用することはできません。…
核心:何を提案したのか
本論文は、量子化されたLLMの全パラメータを、推論時と同等のメモリコストで直接ファインチューニングするための新しい最適化パラダイム「量子化進化戦略(QES)」を提案しました。QESの核心は、信号処理の分野で古くから知られているデルタ・シグマ(ΔΣ)変調の原理を最適化プロセスに導入したことにあります。これにより、個々の更新ステップが粗い量子化の閾値を超えないほど微小な場合でも、その誤差を切り捨てずに蓄積し、次以降のステップに反映させることで、時間平均として高精度な最適化の軌跡を維持することが可能になります。 QESは主に2つの革新的なメカニズムで構成されています。第一に「累積誤差フィードバック(Accumulated Error Feedback)」です。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related