MemCast:経験条件付き推論によるメモリ駆動型時系列予測
MemCastは、時系列予測を単なる数値回帰ではなく、過去の経験を条件とした推論タスクとして再定義し、大規模言語モデルに階層的な外部メモリを統合した新しいフレームワークである。 学習データから「歴史的パターン」「推論の知恵」「一般法則」の3層からなる構造化されたメモリを構築し、推論時にこれらを動的に参照・反映させることで、モデルの重みを再学習することなく高い精度と環境適応力を実現した。 電力価格、エネルギー発電量、河川流量などの多様な実データを用いた検証において、従来の統計手法や最新の深層学習モデルを一貫して上回る性能を示し、運用を通じた継続的な自己進化を可能にしている。
TL;DR(結論)
MemCastは、時系列予測を単なる数値回帰ではなく、過去の経験を条件とした推論タスクとして再定義し、大規模言語モデルに階層的な外部メモリを統合した新しいフレームワークである。 学習データから「歴史的パターン」「推論の知恵」「一般法則」の3層からなる構造化されたメモリを構築し、推論時にこれらを動的に参照・反映させることで、モデルの重みを再学習することなく高い精度と環境適応力を実現した。 電力価格、エネルギー発電量、河川流量などの多様な実データを用いた検証において、従来の統計手法や最新の深層学習モデルを一貫して上回る性能を示し、運用を通じた継続的な自己進化を可能にしている。
なぜこの問題か
時系列予測は、エネルギーの需給調整、金融取引、ヘルスケアのモニタリングなど、現代社会の多岐にわたる意思決定において極めて重要な役割を果たしている。近年、大規模言語モデル(LLM)の強力な推論能力をこの分野に応用する試みが進んでおり、一定の成果を上げている。しかし、既存のLLMベースの予測手法には、解決すべき二つの大きな限界が残されている。第一に、既存手法の多くは各予測タスクを独立した推論として扱っており、過去の予測プロセスから得られた貴重な知見を明示的に蓄積し、将来の予測に再利用する仕組みが欠けている。つまり、モデルが「経験から学ぶ」ことができず、過去の成功や失敗を次の予測に活かすことができない。 第二に、時系列データは時間の経過とともにその性質や分布が変化する「コンセプトドリフト」が発生しやすいが、既存モデルには継続的な進化プロセスが備わっていない。学習ベースの手法はモデルの重みを更新するために膨大な計算資源と時間を必要とし、学習不要の手法は各時点でのプロンプト操作に留まるため、長期的な精度の向上や環境への適応が見込めない。…
核心:何を提案したのか
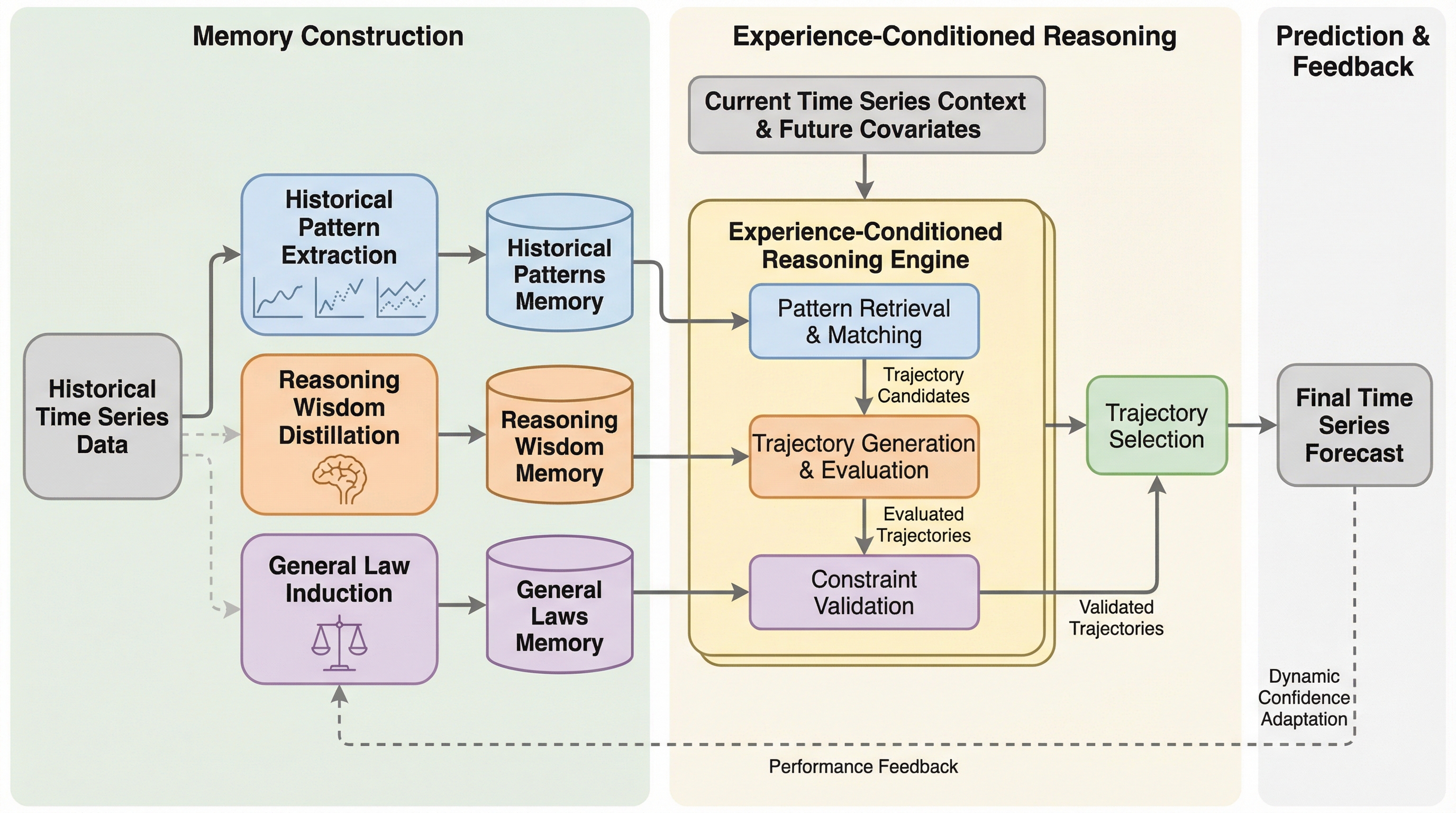
本研究の核心は、時系列予測を「経験条件付き推論タスク」として再定義し、それを実現するための「MemCast」と呼ばれる学習・メモリフレームワークを提案した点にある。このフレームワークの最大の特徴は、学習データから抽出した多角的な経験を「階層的メモリ」として整理し、推論の「条件」としてLLMに提供する点にある。このメモリは、単一の情報を格納するのではなく、役割の異なる3つの階層で構成されている。まず、具体的な過去の事例をテキスト形式で要約した「歴史的パターン」、次に、推論の成功や失敗のプロセスを蒸留して得られた「推論の知恵」、そして、データ全体に共通する物理的・統計的な制約をまとめた「一般法則」である。 これにより、LLMは自身の内部知識だけに頼るのではなく、外部に蓄積された具体的な成功体験や失敗の教訓を「カンニングペーパー」のように参照しながら、より文脈に即した高度な推論を行うことが可能になる。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related