DynSplit-KV:効率的な長文コンテキストLLM推論におけるKVキャッシュ圧縮のための動的意味分割
大規模言語モデルの長文推論において、従来の固定長や固定区切り文字によるKVキャッシュ分割は、文脈ごとの意味境界を無視するため最大55.1%もの大幅な精度低下を招くという深刻な課題がありましたが、本研究はこれを解決する動的分割手法を提案しました。
TL;DR(結論)
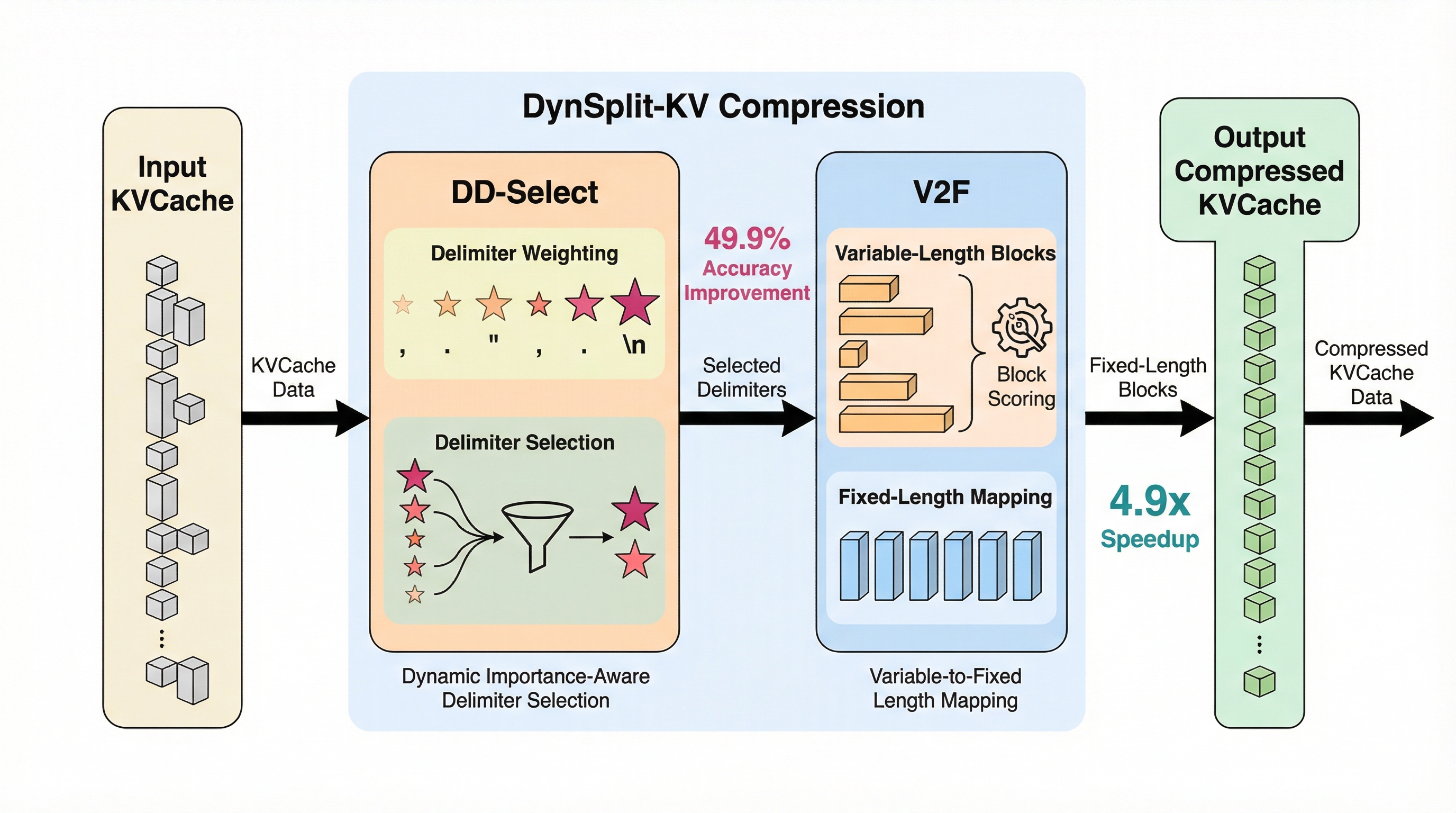
大規模言語モデルの長文推論において、従来の固定長や固定区切り文字によるKVキャッシュ分割は、文脈ごとの意味境界を無視するため最大55.1%もの大幅な精度低下を招くという深刻な課題がありましたが、本研究はこれを解決する動的分割手法を提案しました。 提案手法であるDynSplit-KVは、アテンションスコアを用いて区切り文字の重要度を動的に評価するDD-Selectと、可変長ブロックを固定長形式に変換して並列処理を可能にするV2F戦略を導入することで、意味的な一貫性と計算効率の両立を実現しています。 検証の結果、DynSplit-KVは既存手法を上回る最高精度を達成し、標準的な手法と比較して2.2倍の高速化と2.6倍のピークメモリ削減を実現しており、100万トークンを超える超長文処理の実用性を飛躍的に向上させることが報告されています。
なぜこの問題か
大規模言語モデル(LLM)が100万から1000万トークンという膨大なコンテキストを処理可能になった現代において、推論時の効率を妨げる最大のボトルネックはKVキャッシュ(Key-Valueキャッシュ)のメモリ消費量です。KVキャッシュは過去の計算結果を保存して冗長な計算を避けるために不可欠ですが、コンテキストが長くなるにつれてそのサイズが指数関数的に膨大になり、ハードウェアのメモリ制限を容易に超えてしまいます。例えば、Llama2-13Bモデルで128kのコンテキスト長を処理する場合、KVキャッシュだけで80GBのメモリを占有し、これはNVIDIA A100 GPUの全容量に相当します。このような状況では、KVキャッシュへのアクセスが推論全体の遅延の80%以上を占めることになり、スループットが著しく低下します。 このメモリボトルネックを解消するためにKVキャッシュの圧縮が不可欠ですが、既存の圧縮手法には大きな欠陥があります。現在の主流な手法は、固定の間隔でトークンを区切る「固定長分割」や、あらかじめ定義された句読点などの「固定区切り文字分割」といった、硬直的な分割戦略に依存しています。…
核心:何を提案したのか
本研究では、KVキャッシュの圧縮において意味内容に合わせて動的に分割を行う新手法「DynSplit-KV」を提案しました。この手法の核心は、静的なルールに縛られるのではなく、モデル自身のアテンション機構を利用して、その時々の文脈においてどこが意味的な区切りとして重要であるかを判断する点にあります。DynSplit-KVは、従来の圧縮手法が抱えていた「意味の不一致による精度低下」と「可変長処理による計算オーバーヘッド」という2つの主要な課題を同時に解決することを目指しています。 具体的には、2つの革新的な戦略を導入しています。第一の戦略は「DD-Select(動的重要度認識区切り文字選択戦略)」です。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related