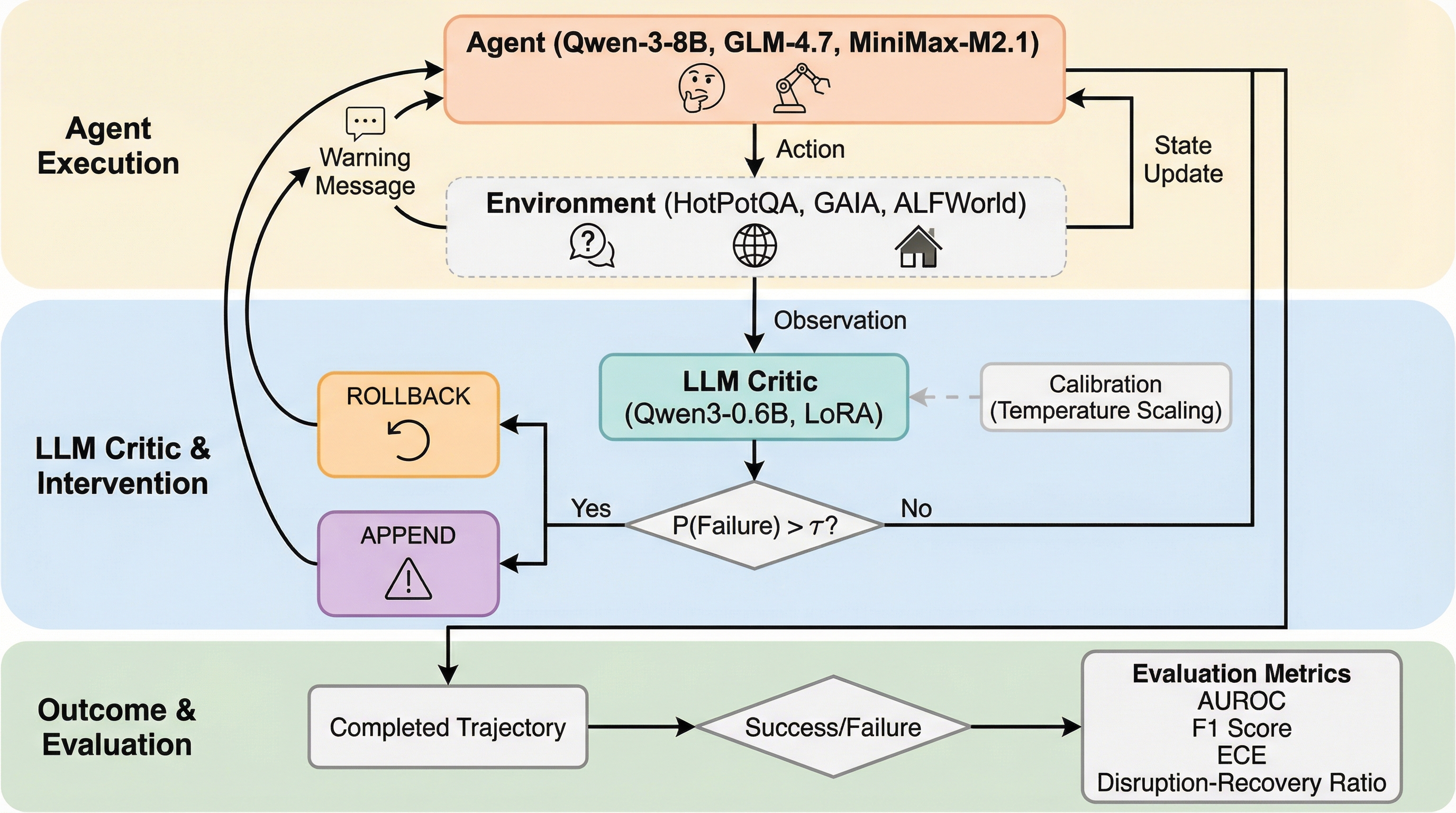
エージェントの失敗予測の精度は必ずしも効果的な失敗防止を意味しない
LLMエージェントの失敗を事前に検知する批判モデルは、たとえAUROC 0.94という極めて高い予測精度を持っていても、実際の運用時に介入を行うとエージェントの思考プロセスを破壊し、性能を大幅に低下させるリスクがあることが判明しました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
LLMエージェントの失敗を事前に検知する批判モデルは、たとえAUROC 0.94という極めて高い予測精度を持っていても、実際の運用時に介入を行うとエージェントの思考プロセスを破壊し、性能を大幅に低下させるリスクがあることが判明しました。
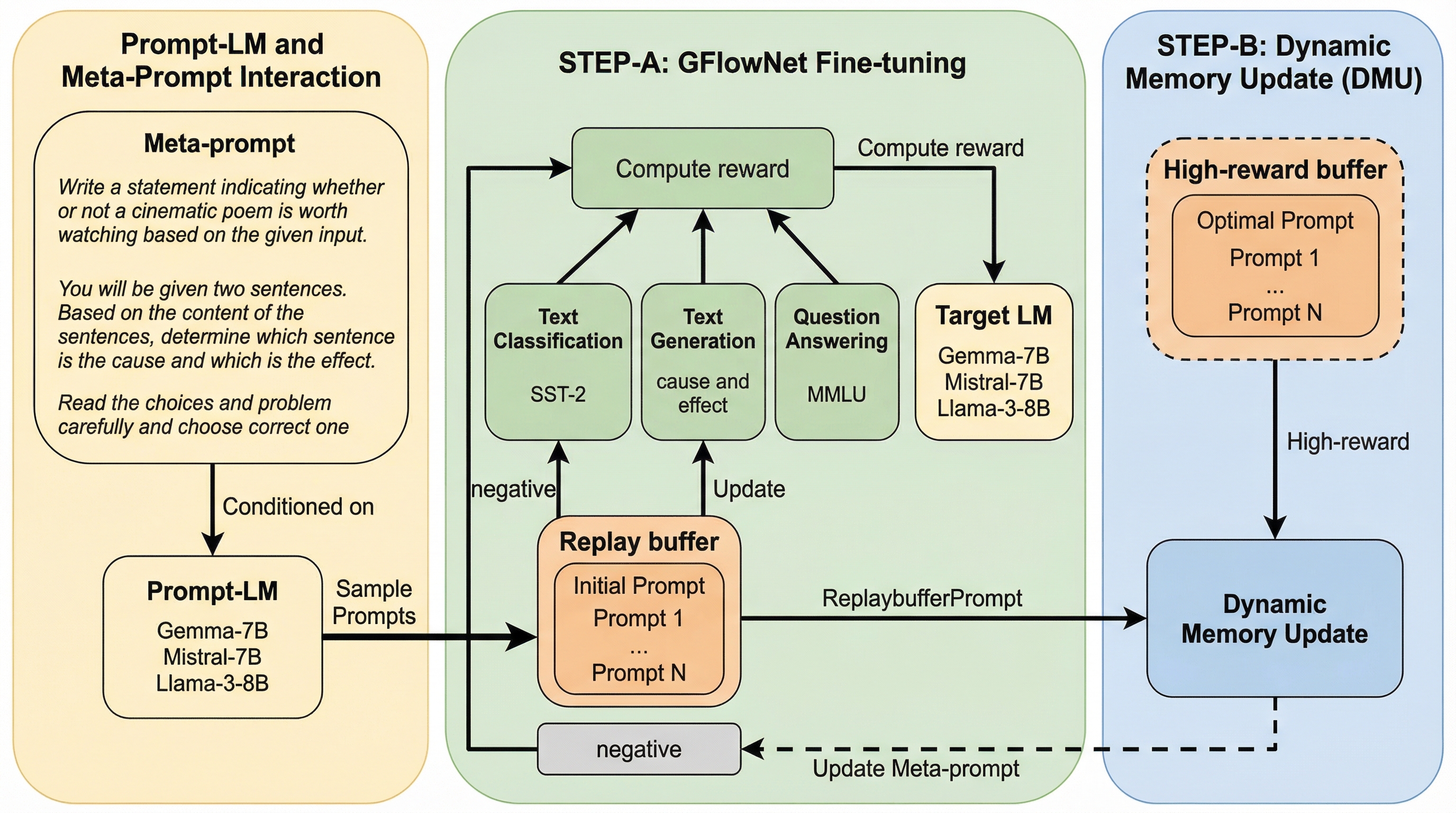
GFlowPOは、言語モデルのプロンプト探索を潜在的なプロンプトに対する事後分布推論の問題として定式化し、生成フローネットワーク(GFlowNet)を活用して効率的に最適化を行う新しい確率的フレームワークです。
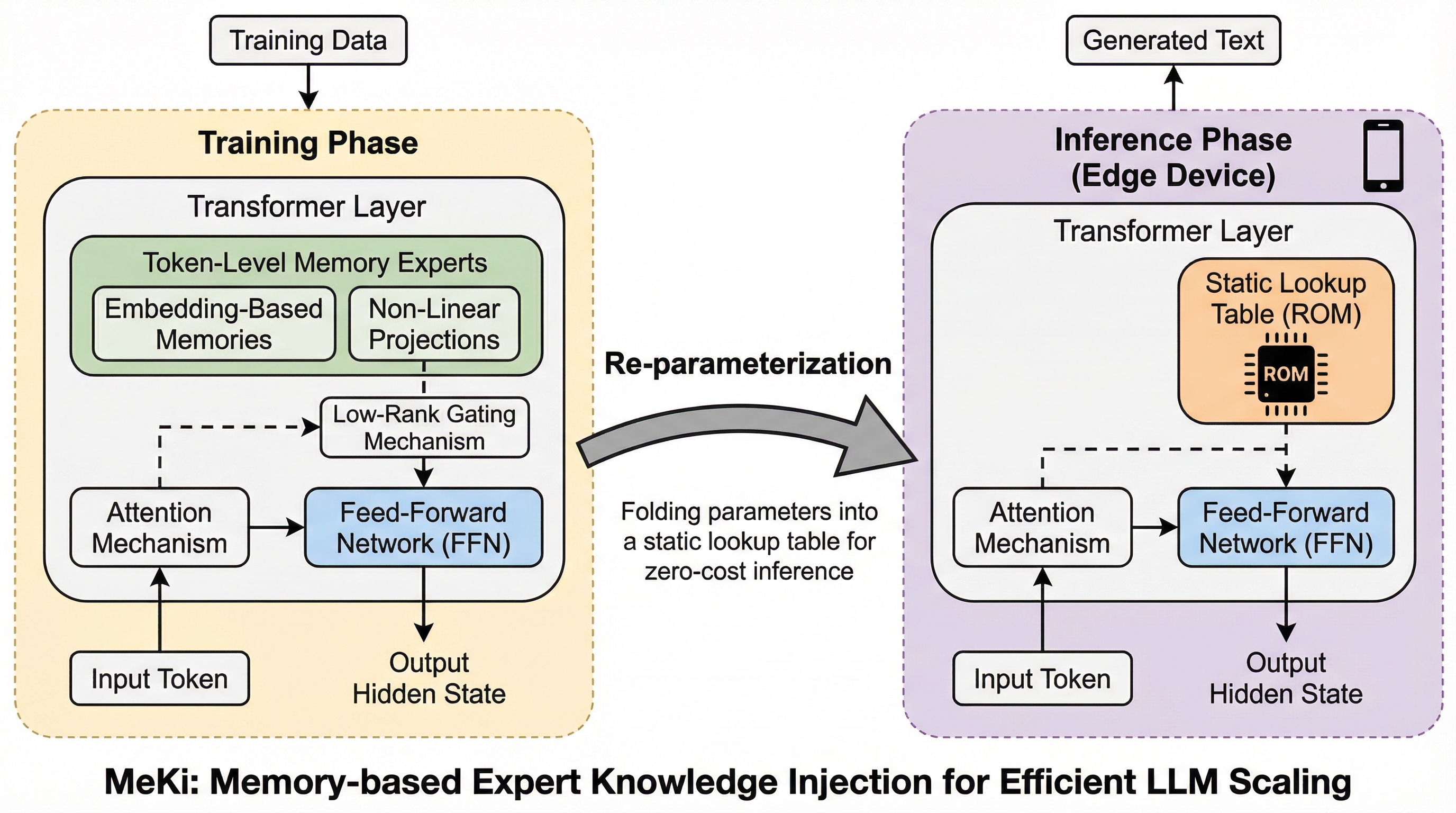
スマートフォンなどのエッジデバイスにおいて、計算量やメモリ消費を抑えつつモデルの能力を向上させるため、ストレージ(ROM)を活用して知識を注入する新しいアーキテクチャ「MeKi」が提案されました。
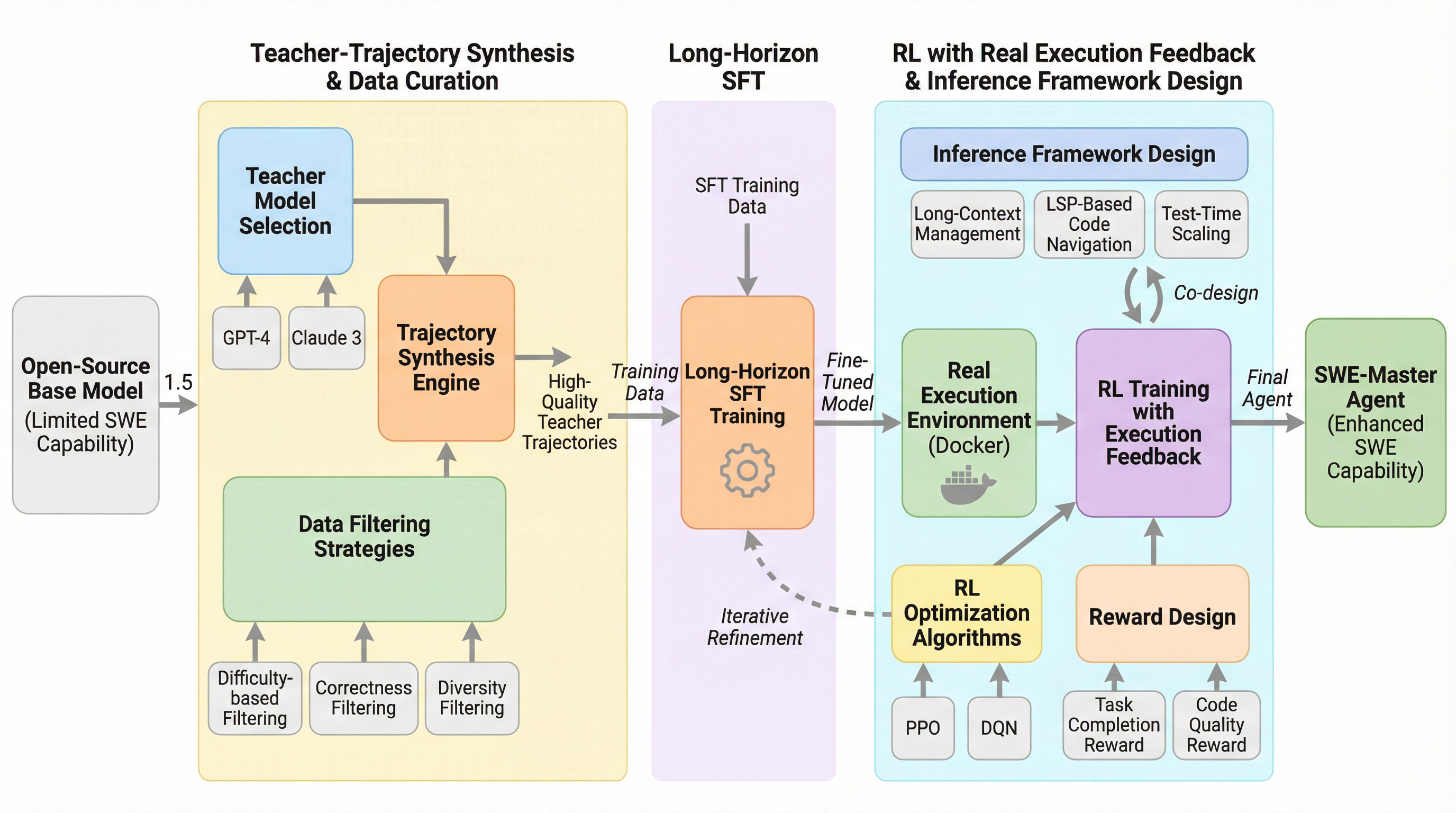
SWE-Masterは、ソフトウェアエンジニアリング(SWE)タスクを自律的に解決するエージェントを構築するための、完全に再現可能でオープンソース化されたポストトレーニングフレームワークである。
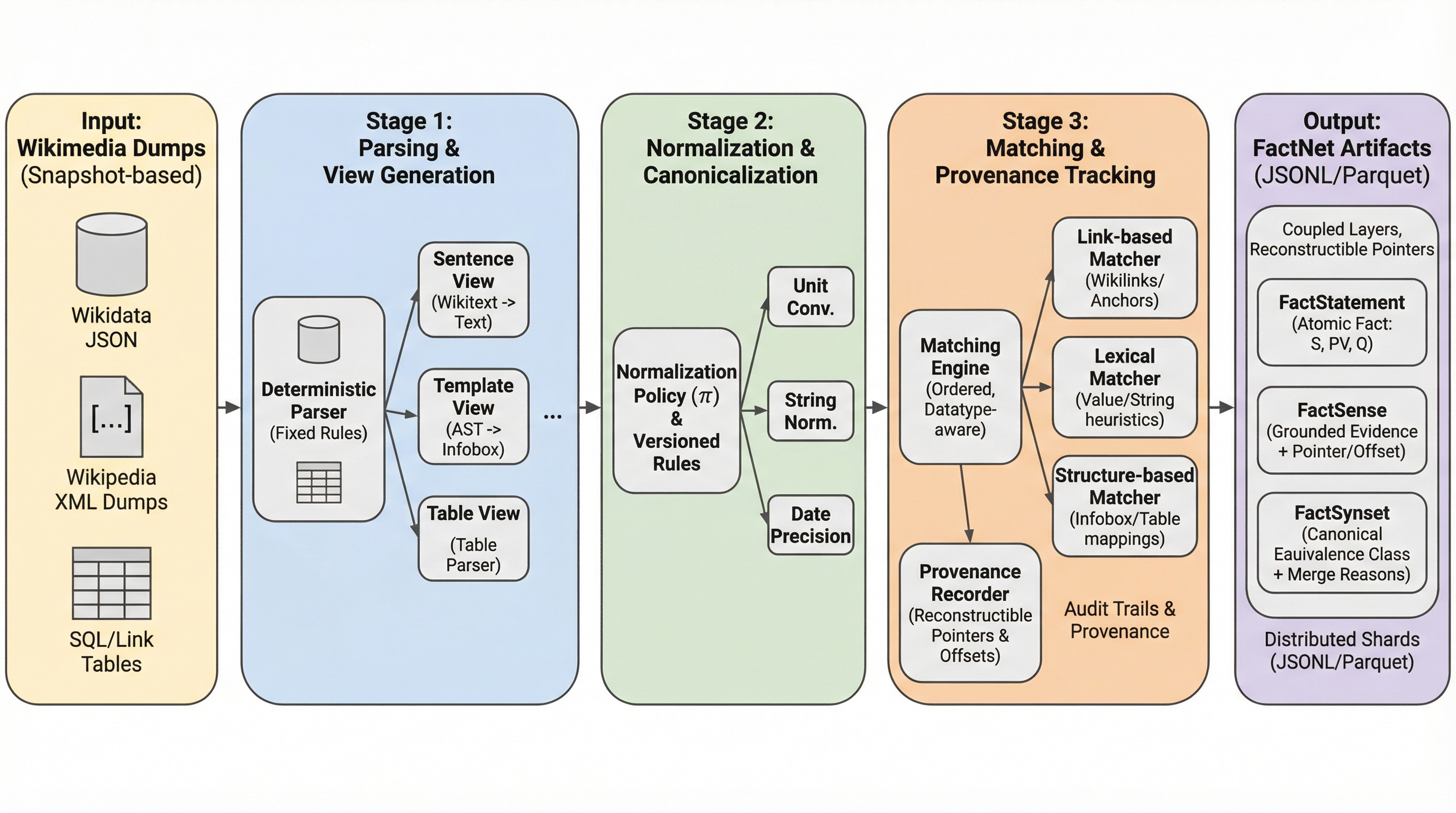
FactNetは、1.7億件の原子的な主張と316の言語版Wikipediaから抽出された30.1億件の証拠ポインタを統合した、世界最大規模の多言語ナレッジグラフであり、LLMのハルシネーション抑制に不可欠な追跡可能な根拠を提供する。
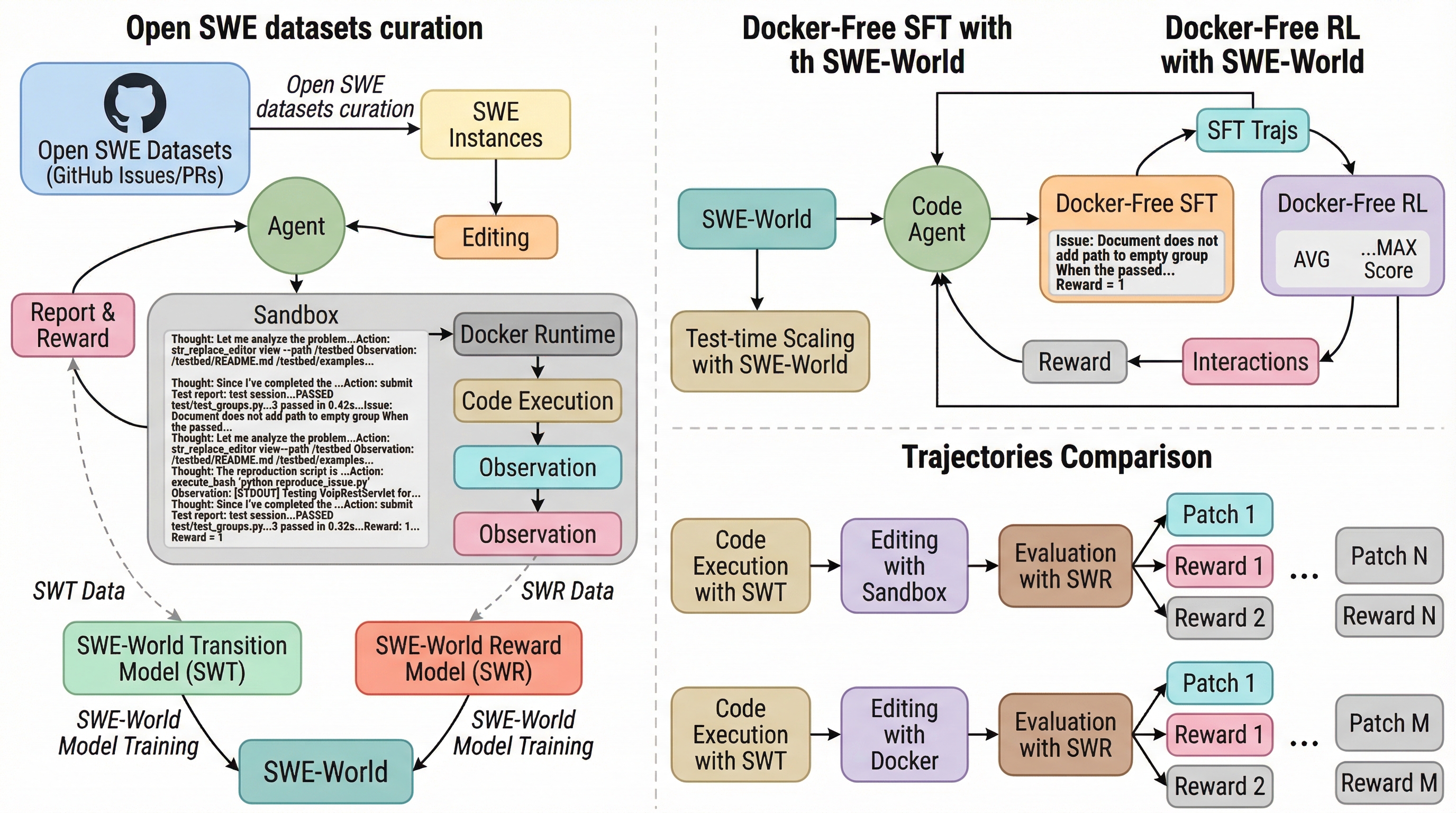
従来のソフトウェアエンジニアリングエージェントは、コード実行やテストのためにDockerなどの重いコンテナ環境に依存しており、環境構築の失敗や膨大な計算リソースの消費が、大規模な学習や評価を妨げる深刻なボトルネックとなっていました。
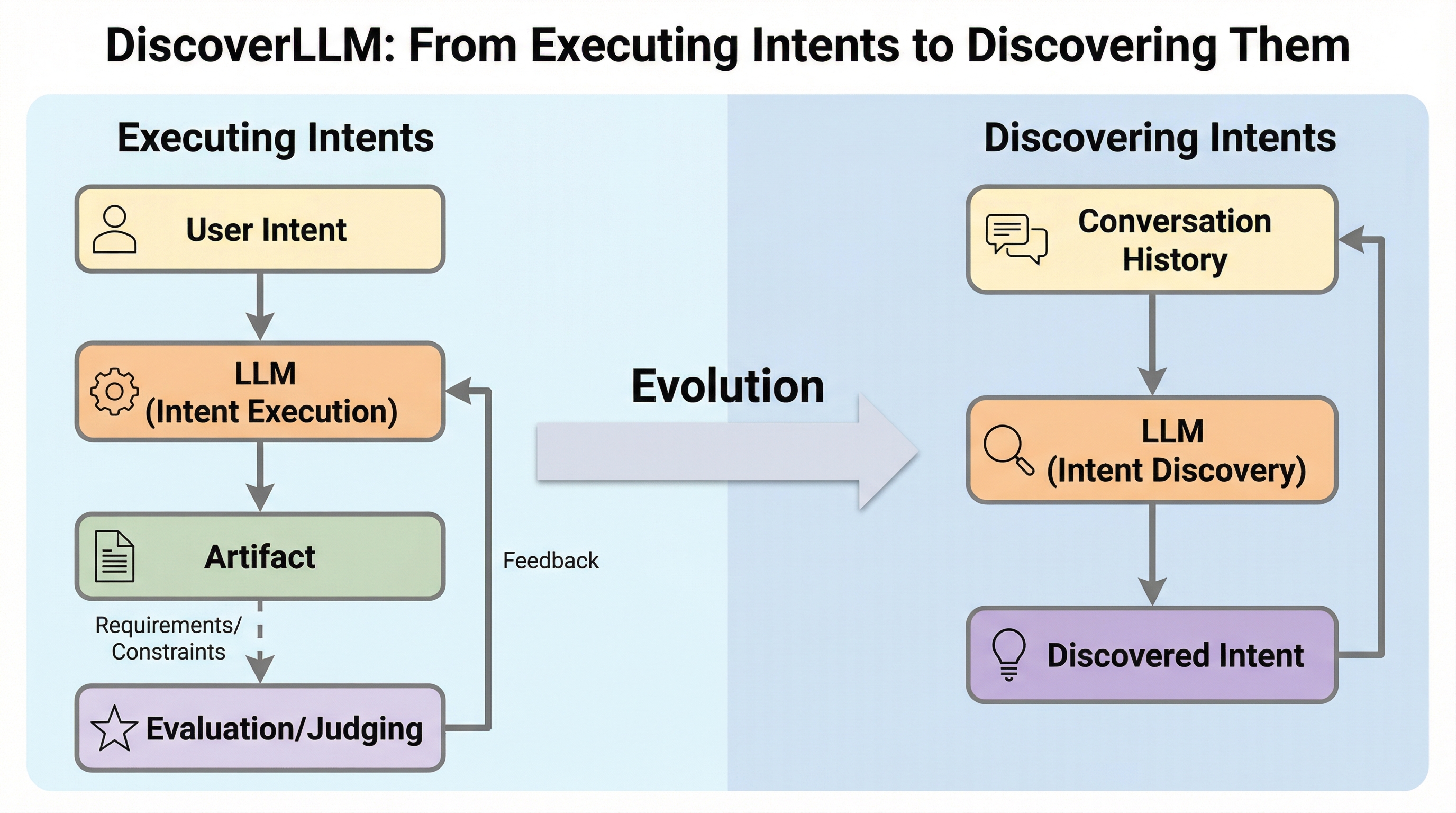
ユーザーが自身の望みを完全には言語化できていない「未形成の意図」を持つ状況において、従来の大規模言語モデルは具体的な質問を繰り返すだけであり、ユーザーが答えを持っていない場合には効果的に機能しないという課題がありました。
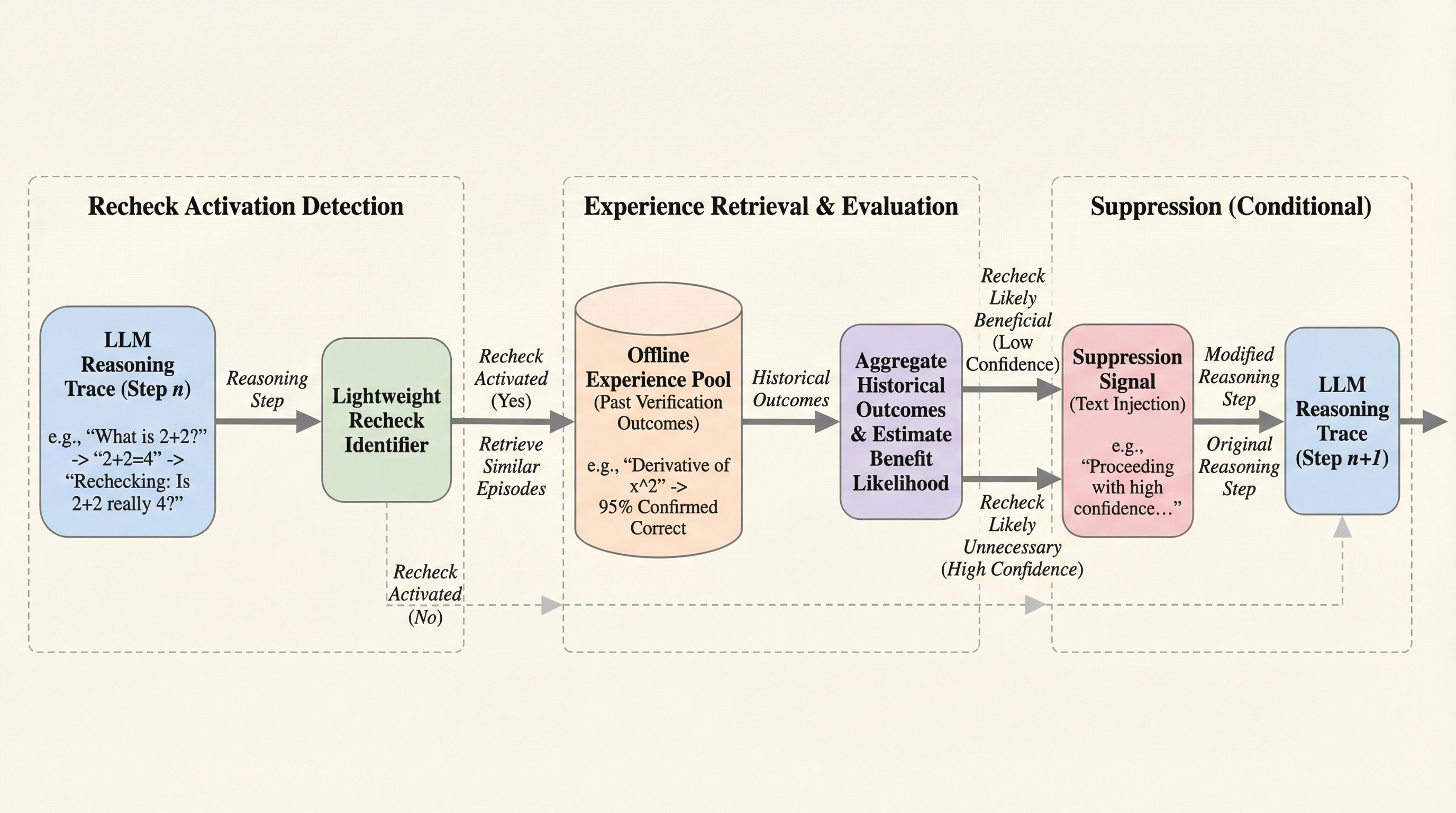
大規模推論モデル(LRM)の思考過程において、反省ステップの約4割から6割が中間結果の再確認(再チェック)であり、そのうち85%から95%という圧倒的多数が誤りを修正しない冗長なものであることが判明しました。
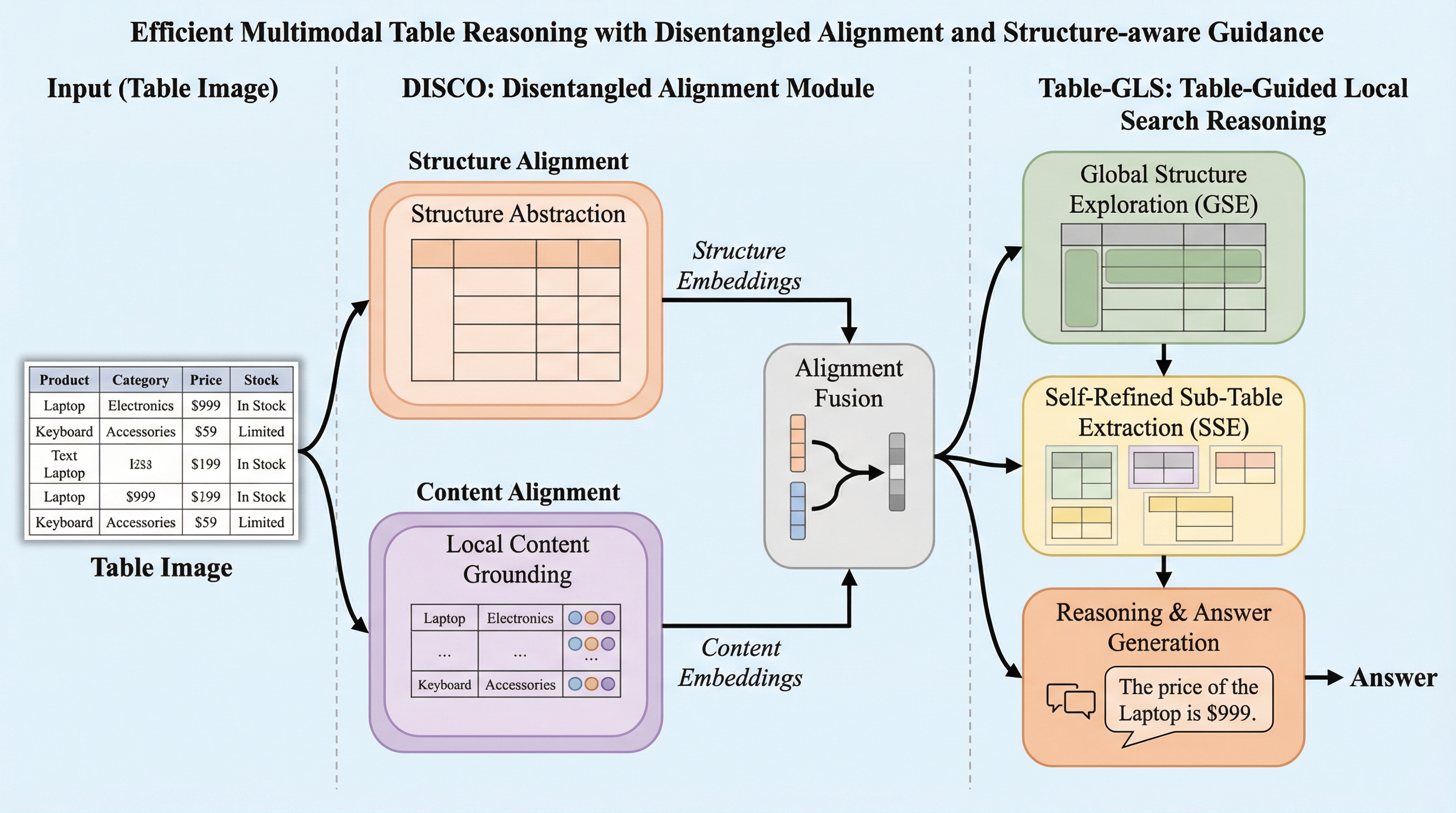
大型視覚言語モデル(LVLM)において、表の複雑なレイアウトと内容が密接に結合している問題を解決するため、構造(骨格)と内容(肉)を分離して学習させる「DISCO」アライメント手法を提案した。 外部ツールや膨大な推論用データに頼らず、表全体から必要な部分を段階的に特定して推論を行う「Table-GLS」フレームワークを導入し、未知の表構造に対しても高い汎用性と信頼性を実現した。 21種類のタスクを用いた検証の結果、わずか1万枚の画像による学習で、従来の大規模データを用いた手法を上回る性能を達成し、効率的かつ解釈可能なマルチモーダル表推論が可能であることを示した。
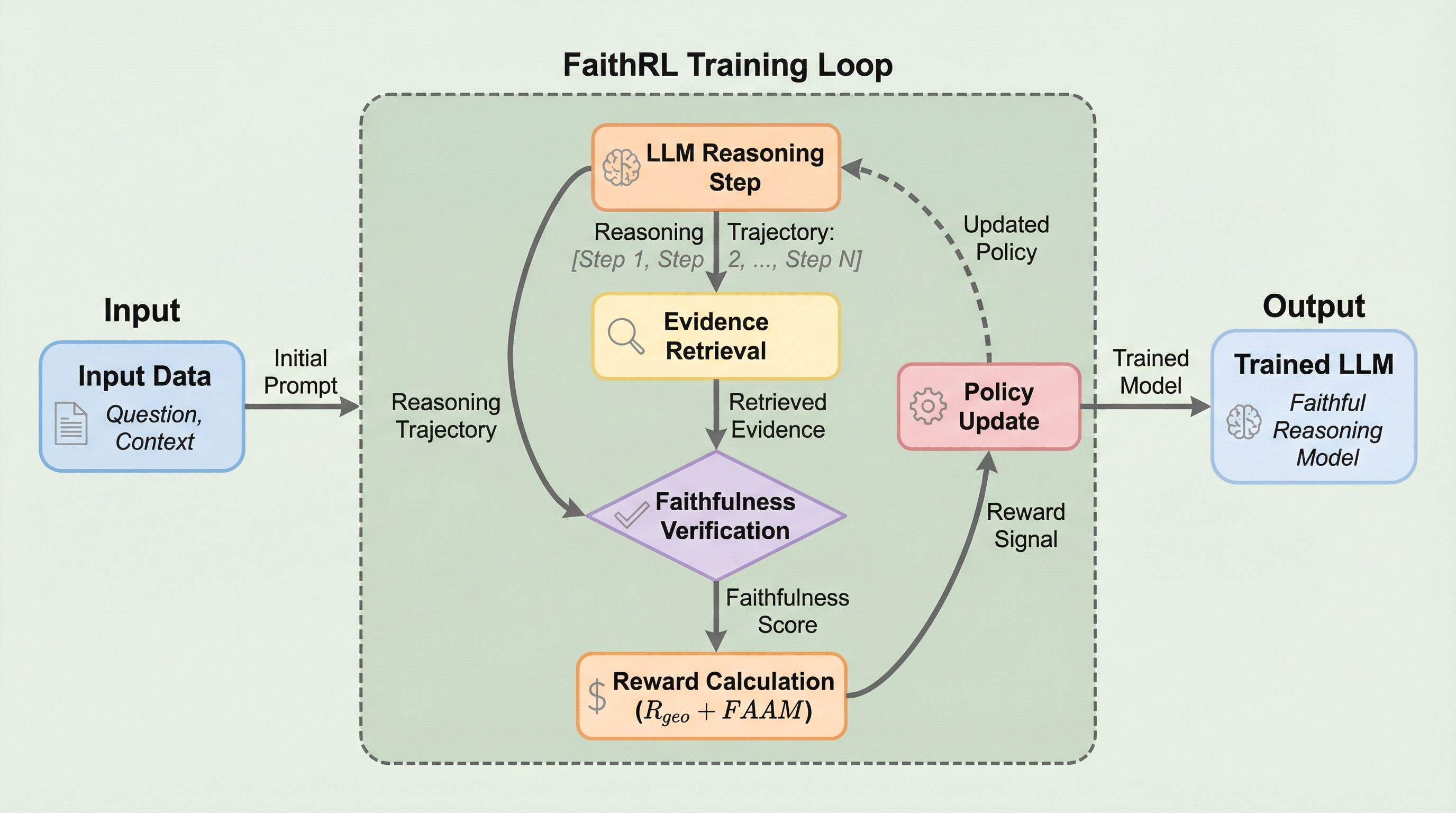
大規模言語モデルの多段階推論において、従来の最終回答のみを評価する強化学習は、論理を無視して正解を推測する過度な自信やハルシネーションを助長する課題がありましたが、本研究は推論の各ステップが証拠に基づいているかを直接評価する新しい強化学習フレームワーク「FaithRL」を提案しました。