MeKi: 効率的なLLMスケーリングのためのメモリベースの専門知識注入
スマートフォンなどのエッジデバイスにおいて、計算量やメモリ消費を抑えつつモデルの能力を向上させるため、ストレージ(ROM)を活用して知識を注入する新しいアーキテクチャ「MeKi」が提案されました。
TL;DR(結論)
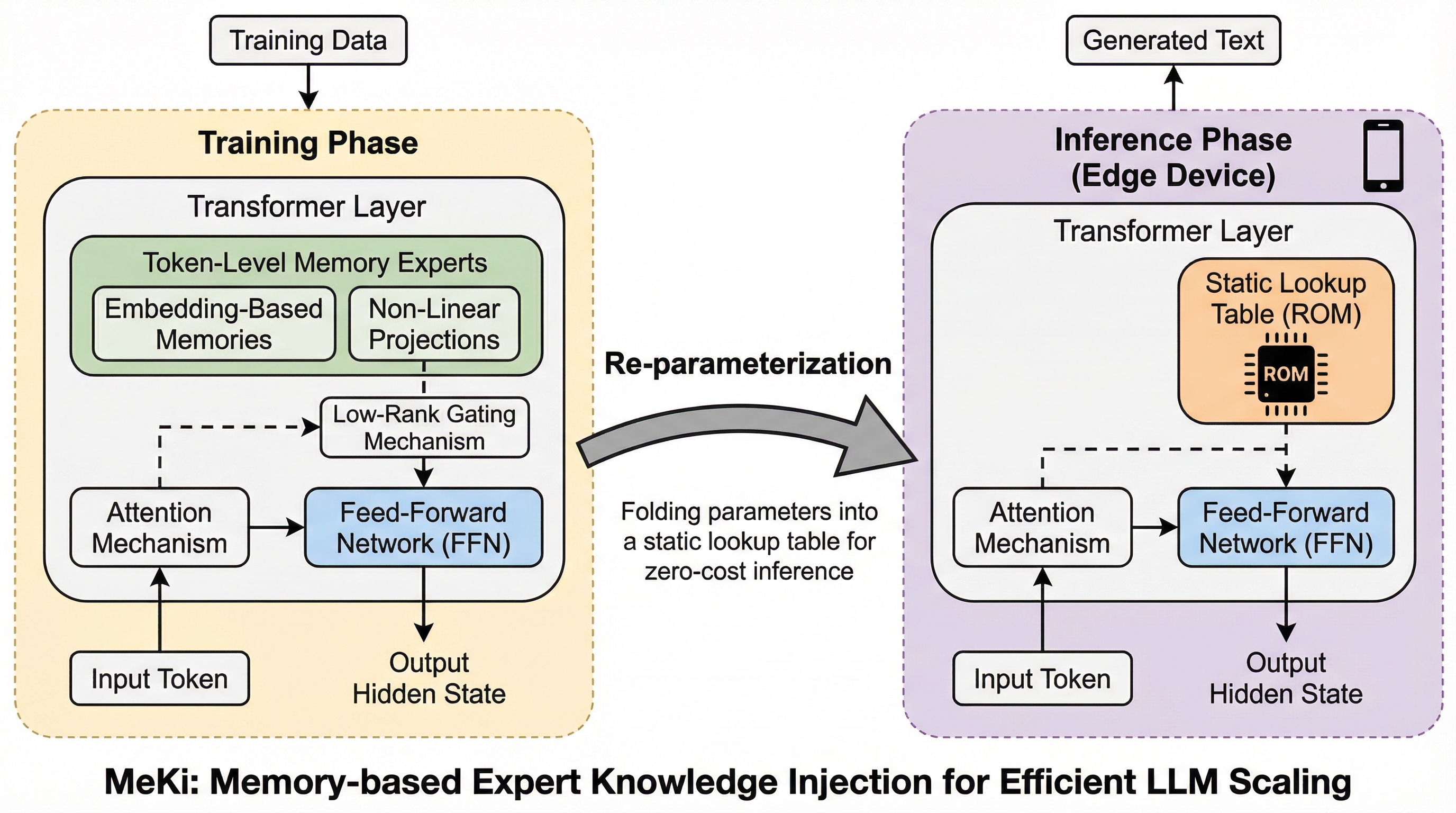
スマートフォンなどのエッジデバイスにおいて、計算量やメモリ消費を抑えつつモデルの能力を向上させるため、ストレージ(ROM)を活用して知識を注入する新しいアーキテクチャ「MeKi」が提案されました。 学習時には複雑な非線形投影を用いて知識を習得し、推論時には再パラメータ化技術によってこれらを静的なルックアップテーブルへと統合することで、計算負荷を増やすことなくモデルの容量を拡張することに成功しています。 検証の結果、1.7BパラメータのMeKiモデルは、推論速度で2.26倍の優位性を保ちながら、4Bパラメータの密なモデルに匹敵する性能を達成し、エッジデバイスでの高性能なAI実行に新たな可能性を示しました。
なぜこの問題か
大規模言語モデル(LLM)の性能を向上させるための標準的な手法は、パラメータ数を増やすか、あるいは推論時の計算量を増大させるスケーリング則に基づいています。しかし、これらの戦略をスマートフォンなどのエッジデバイスに適用しようとすると、搭載されているRAMの容量やNPUのリソースが限られているため、実用上の大きな障壁となります。モデルのパラメータを単純に拡大すると浮動小数点演算(FLOPs)が増加し、モバイルハードウェアにおいて許容できないほどの遅延や消費電力の増大を招くことになります。モバイルユーザーは遅延に対して非常に敏感であり、計算負荷の増大はユーザー体験を著しく損なう要因となります。 また、Mixture-of-Experts(MoE)のようなアーキテクチャは、トークンごとに一部のエキスパートのみを活性化させることで計算量を抑えようとしますが、エッジデバイスでは巨大で断片化されたエキスパートの重みを頻繁にロードする必要があります。…
核心:何を提案したのか
本研究では、計算コストからモデル容量を切り離す新しいシステムとして、MeKi(Memory-based Expert Knowledge Injection)を提案しています。MeKiは、各Transformerレイヤーにトークンレベルのメモリ・エキスパートを装備し、あらかじめ蓄積された意味的知識を生成プロセスに注入する仕組みです。この手法の最大の特徴は、モデルの能力向上を演算能力(FLOPs)ではなく、ストレージ容量(ROM)に依存させる点にあります。これにより、モデルの知識量を増やしながらも、推論時の計算負荷を一定に保つことが可能になります。 MeKiの設計思想は、モデルの学習能力と推論効率のギャップを埋めることにあります。学習段階では、埋め込みベースのメモリと非線形投影を組み合わせて、トークンレベルの高度なエキスパート知識表現を学習します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related