GFlowPO: 言語モデルプロンプトオプティマイザとしての生成フローネットワーク
GFlowPOは、言語モデルのプロンプト探索を潜在的なプロンプトに対する事後分布推論の問題として定式化し、生成フローネットワーク(GFlowNet)を活用して効率的に最適化を行う新しい確率的フレームワークです。
TL;DR(結論)
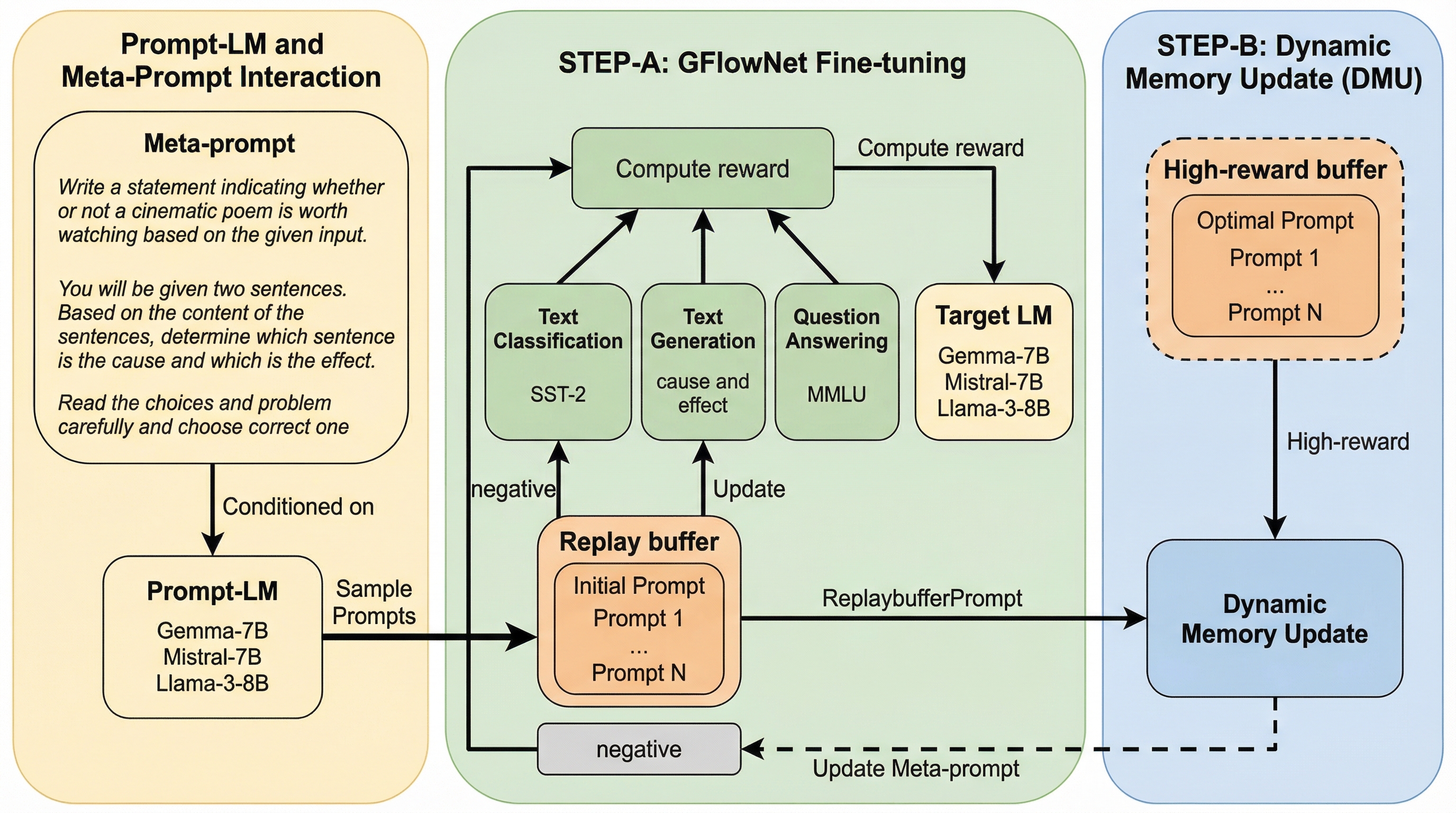
GFlowPOは、言語モデルのプロンプト探索を潜在的なプロンプトに対する事後分布推論の問題として定式化し、生成フローネットワーク(GFlowNet)を活用して効率的に最適化を行う新しい確率的フレームワークです。 過去の評価結果を再利用するオフポリシー学習(STEP-A)と、メタプロンプトを動的に更新して探索範囲を高報酬領域へと絞り込む動的メモリ更新(DMU、STEP-B)を組み合わせることで、評価コストの高いターゲットモデルに対するサンプル効率を劇的に向上させます。 テキスト分類や質問回答などの多様なタスクにおいて、LlamaやGemmaといった様々なモデルを用いた検証の結果、既存の強化学習ベースの手法を一貫して上回る性能を示し、特に軽量なモデルでも高度なプロンプト生成が可能であることを実証しました。
なぜこの問題か
現代の言語モデル(LM)において、入力されるプロンプトの設計はモデルの性能を左右する極めて重要な要素ですが、プロンプトのわずかな語句の変更が出力結果に劇的な影響を与えることが知られています。しかし、効果的なプロンプトを見つけ出す作業は、現状では人間の直感や試行錯誤に依存した手動のプロセスであり、多大な労力と時間を要するという大きな課題があります。このプロセスを自動化しようとする「自動プロンプト最適化」は有望な研究分野ですが、プロンプトの探索空間は語彙の組み合わせによって爆発的に巨大化するため、最適な解を特定することは極めて困難です。また、ターゲットとなる言語モデルの評価には高い計算コストやAPI費用がかかるため、得られる報酬信号が非常に疎(スパーズ)であるという問題も存在します。既存の強化学習(RL)を用いた手法の多くは、現在の方策から得られたサンプルのみを使用する「オンポリシー学習」に依存しており、これが効率を下げています。このような手法では、信頼できる勾配を得るために膨大な数のサンプルが必要となり、サンプル効率が著しく低いという致命的な欠点がありました。…
核心:何を提案したのか
本研究では、プロンプト探索を「事後分布推論問題」として捉え直す、新しい確率的フレームワークである「GFlowPO」を提案しました。このフレームワークの核心は、参照言語モデル(reference-LM)による事前分布で正則化された潜在プロンプトの事後分布を、軽量なプロンプト生成用言語モデル(prompt-LM)によって近似することにあります。GFlowPOは、2つの主要なステップを交互に繰り返すことで、効率的な探索と最適化を実現します。第一のステップ(STEP-A)では、生成フローネットワーク(GFlowNet)の目的関数を用いて、オフポリシーでのサンプル効率の高い学習を行います。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related