ステップ単位の忠実度最大化による誠実な推論の学習
大規模言語モデルの多段階推論において、従来の最終回答のみを評価する強化学習は、論理を無視して正解を推測する過度な自信やハルシネーションを助長する課題がありましたが、本研究は推論の各ステップが証拠に基づいているかを直接評価する新しい強化学習フレームワーク「FaithRL」を提案しました。
TL;DR(結論)
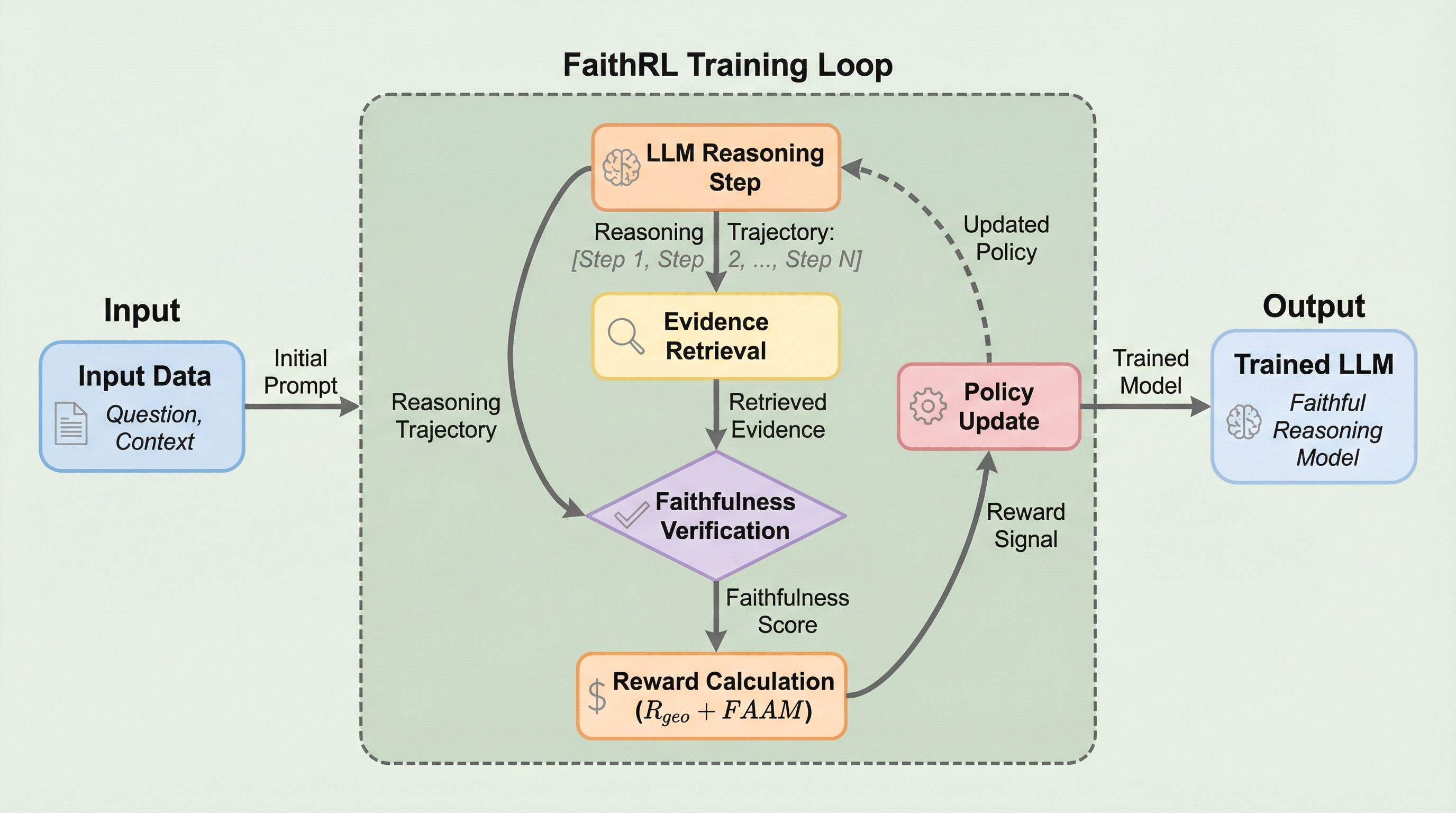
大規模言語モデルの多段階推論において、従来の最終回答のみを評価する強化学習は、論理を無視して正解を推測する過度な自信やハルシネーションを助長する課題がありましたが、本研究は推論の各ステップが証拠に基づいているかを直接評価する新しい強化学習フレームワーク「FaithRL」を提案しました。 この手法は、モデルの初期能力に基づいた「幾何学的報酬」によって正解・拒否・ハルシネーションのバランスを最適化し、さらに「忠実度認識アドバンテージ変調(FAAM)」を用いて、証拠に裏付けられた推論ステップのみをトークン単位で強化することで、誠実な推論プロセスを学習させます。 実験の結果、複数のベンチマークでハルシネーション率を平均4.7ポイント削減しながら正解率を1.6ポイント向上させ、未知の数学タスク等においても高い汎化性能と論理的な安定性を実証し、モデルが「知らないことを知らないと言う」誠実さを獲得できることを示しました。
なぜこの問題か
大規模言語モデル(LLM)の推論能力を向上させる手法として、検証可能な報酬を用いた強化学習(RLVR)が注目を集めていますが、これには解決すべき重大な課題が残されています。現在のRLVRの多くは、最終的な回答の正誤のみに基づく「スパースな報酬」に依存しており、回答に至るまでの中間的な推論ステップが論理的に正しいかどうかを十分に監視できていません。その結果、モデルは論理的な裏付けがないまま正解を「推測」して報酬を得ようとする傾向があり、これが「過度な自信」や、事実に基づかない「ハルシネーション(幻覚)」を引き起こす要因となっています。具体的には、モデルが不確実な状況で回答を拒否するよりも、不確かな推論を重ねてでも正解を導き出すことにインセンティブを感じてしまうという問題があります。 また、偶然正解に辿り着いた誤った推論ステップが正の報酬によって強化される一方で、正しい推論の途中経過が最終的な誤答のために不当に罰せられるという現象も発生しています。…
核心:何を提案したのか
本論文では、推論の忠実度を直接的に最大化することを目的とした強化学習フレームワーク「FaithRL」を提案しています。このフレームワークの核心は、モデルの推論プロセスを「正解セット(Correct Set)」「拒否セット(Miss Set)」「ハルシネーションセット(Hallucination Set)」の3つに分類し、それぞれの発生確率を制御することで、モデルの能力に応じた最適な推論戦略を学習させる点にあります。まず、理論的な基盤として「推論忠実度の最大化」という最適化目標を定式化しました。これは、モデルが使用する知識が、与えられた問いに答えるために必要な最小限の証拠セットと厳密に一致する状態を目指すものです。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related