必要な時にグラフを使用する:検索拡張生成とグラフの効率的かつ適応的な統合
大規模言語モデルのハルシネーションや知識の風化を防ぐため、クエリの構文的な複雑さを解析して、従来のRAG(検索拡張生成)と構造的な知識グラフを用いるGraphRAGを動的に切り替える新フレームワーク「EA-GraphRAG」が提案されました。
TL;DR(結論)
大規模言語モデルのハルシネーションや知識の風化を防ぐため、クエリの構文的な複雑さを解析して、従来のRAG(検索拡張生成)と構造的な知識グラフを用いるGraphRAGを動的に切り替える新フレームワーク「EA-GraphRAG」が提案されました。 軽量な多層パーセプトロンを用いた複雑度スコアラーを導入することで、単純な質問には高速なベクトル検索を、複雑な推論が必要な質問にはグラフ検索を、境界線上のケースには両者の融合手法を適応的に選択し、精度と効率の最適化を図っています。 複数のベンチマーク評価において、従来手法が抱えていた「単純なクエリでの精度低下」と「過度な遅延」という課題を解決し、回答精度の向上と処理速度の高速化を同時に実現して、実世界での混合シナリオにおける最先端の性能を達成しました。
なぜこの問題か
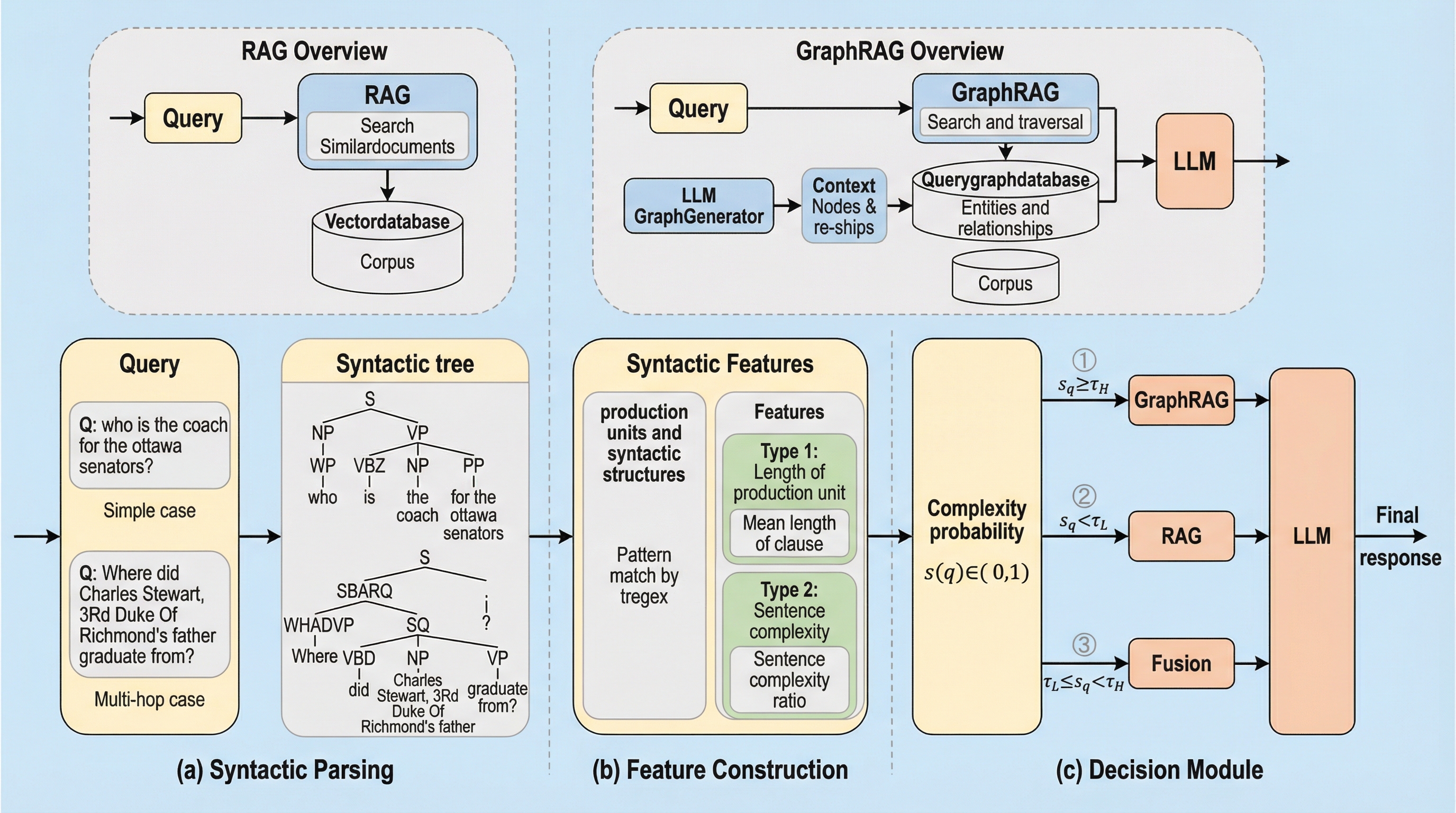
大規模言語モデル(LLM)は、学習データに含まれない最新の知識や専門的な事実を扱う際に、もっともらしい嘘をつく「ハルシネーション」や、内部知識が古くなるという根本的な課題を抱えています。これに対処するため、外部の文書群から関連情報を取得して回答を生成する検索拡張生成(RAG)が広く普及しましたが、非構造化データから断片的なテキストを抽出するだけでは、情報のつながりや文脈の深い理解が不十分になるという限界がありました。特に、複数の情報を組み合わせて推論を行う必要がある複雑な質問に対しては、単純なベクトル検索では対応しきれないことが多くなっています。 この欠点を補うために、知識グラフを活用して構造的な推論を可能にするGraphRAGが登場しましたが、実世界の運用においては新たな問題が浮き彫りになりました。GraphRAGは複雑な推論には長けている一方で、皮肉なことに単純な質問に対しては従来のRAGよりも精度が低くなる傾向があります。先行研究の分析によれば、シングルホップ(一段階の検索で済む)の質問において、GraphRAGは従来のRAGよりも精度が13.4%低下し、時間的な制約があるクエリでは16.…
核心:何を提案したのか
本研究では、クエリの構文的な複雑さを適応的に分析し、RAGとGraphRAGを効率的に統合する新しいフレームワーク「EA-GraphRAG」を提案しました。このフレームワークの核心は、クエリの「構文(シンタックス)」に着目して複雑さを判定し、最適な検索経路を動的に選択する点にあります。言語学的な知見に基づき、文の構造的な難しさは構文的な特徴に反映されるという原理を利用することで、高コストなLLMによる分類に頼らず、軽量かつ高速な判定を実現しました。 EA-GraphRAGは主に3つの革新的なコンポーネントで構成されています。第一に、クエリを解析して構造的な特徴を抽出する「構文特徴量コンストラクタ」です。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related