骨格と肉の分離:もつれを解いたアライメントと構造を考慮したガイダンスによる効率的なマルチモーダル表推論
大型視覚言語モデル(LVLM)において、表の複雑なレイアウトと内容が密接に結合している問題を解決するため、構造(骨格)と内容(肉)を分離して学習させる「DISCO」アライメント手法を提案した。 外部ツールや膨大な推論用データに頼らず、表全体から必要な部分を段階的に特定して推論を行う「Table-GLS」フレームワークを導入し、未知の表構造に対しても高い汎用性と信頼性を実現した。 21種類のタスクを用いた検証の結果、わずか1万枚の画像による学習で、従来の大規模データを用いた手法を上回る性能を達成し、効率的かつ解釈可能なマルチモーダル表推論が可能であることを示した。
TL;DR(結論)
大型視覚言語モデル(LVLM)において、表の複雑なレイアウトと内容が密接に結合している問題を解決するため、構造(骨格)と内容(肉)を分離して学習させる「DISCO」アライメント手法を提案した。 外部ツールや膨大な推論用データに頼らず、表全体から必要な部分を段階的に特定して推論を行う「Table-GLS」フレームワークを導入し、未知の表構造に対しても高い汎用性と信頼性を実現した。 21種類のタスクを用いた検証の結果、わずか1万枚の画像による学習で、従来の大規模データを用いた手法を上回る性能を達成し、効率的かつ解釈可能なマルチモーダル表推論が可能であることを示した。
なぜこの問題か
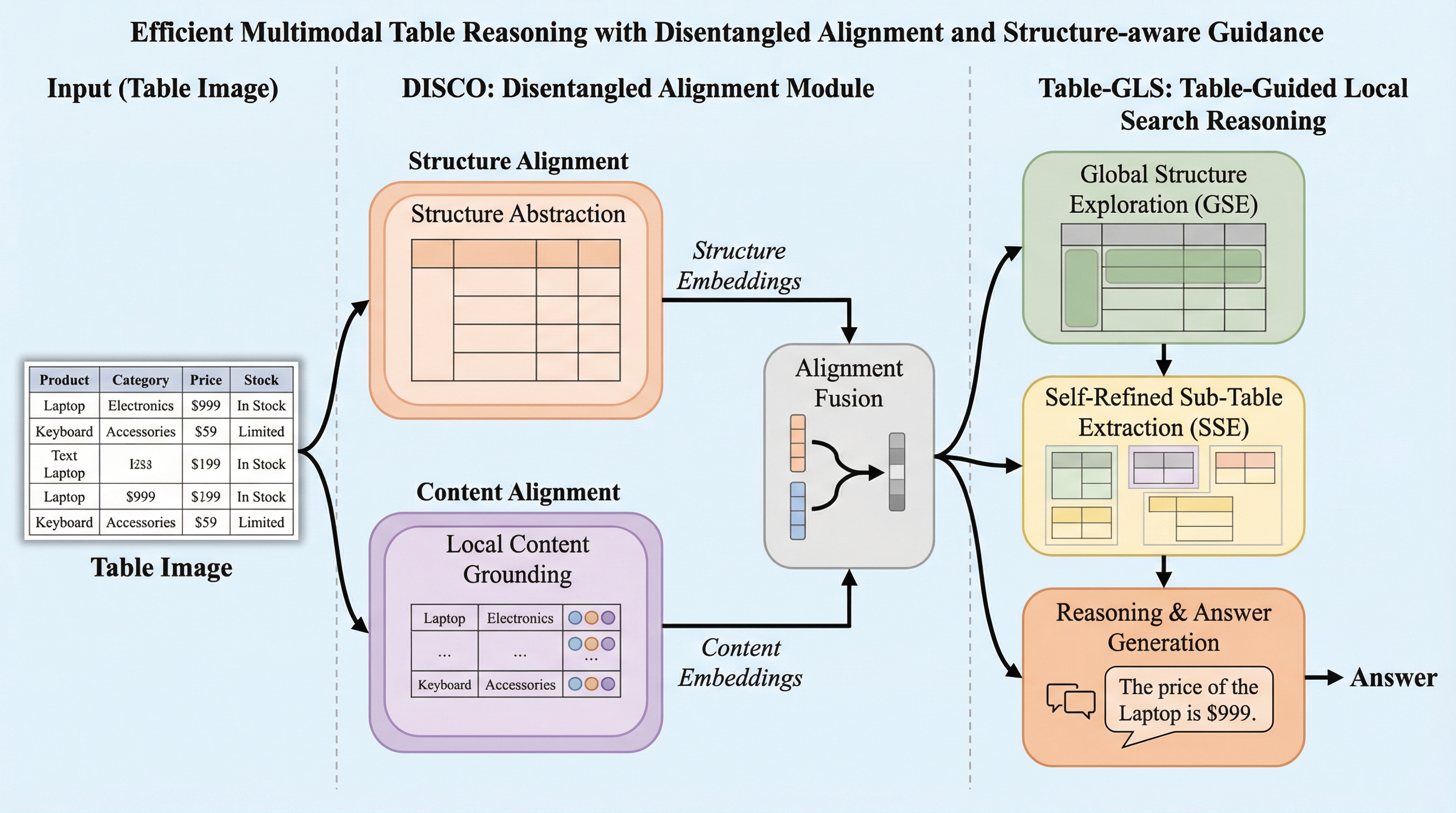
表は、財務報告書、学術論文、医療記録、政府文書など、多岐にわたる分野で情報を体系的に整理するための基本的な媒体である。行と列によって構成されるこの構造的データは、関係性を伝える上で極めて重要である。近年の大型視覚言語モデル(LVLM)の進歩により、視覚的な認識と言語モデリングを統合し、表の画像やスキャンされた文書を直接解釈する試みが進んでいる。しかし、表が複雑なレイアウトを持っていたり、データ密度が高かったり、構造的な依存関係が入り組んでいたりする場合、既存のモデルは依然として正確な理解と推論に苦慮している。 この課題に対し、現在の主なアプローチは二つの方向に分かれている。第一の方向性は、膨大な教師あり微調整や強化学習を用いて、モデルに表の推論能力を直接学習させるものである。この手法は一定の効果を上げるが、専門家による高品質な注釈データの収集には多大なコストがかかり、スケーラビリティに欠けるという欠点がある。また、特定のタスクに特化しすぎることで、モデルが本来持っていた汎用的な推論能力を損なう「破滅的忘却」のリスクも孕んでいる。…
核心:何を提案したのか
本論文では、LVLMを表推論に効率的に適応させるための新しいフレームワークを提案した。その核心となるアイデアは、表の「構造的な知覚」と「意味的な接地(グラウンディング)」を明示的に分離することである。これを実現するために、二つの主要な構成要素を導入した。 第一の要素は、DISCO(Disentangled Structure–Content alignment)と呼ばれるアライメント・フレームワークである。従来の学習手法では、表の画像をHTMLやMarkdownといったテキスト表現に変換する際、構造と内容を一つのシーケンスとして同時に学習させていた。これに対し、DISCOは構造の学習と内容の学習を切り離す。構造アライメントでは、セルの内容を匿名化し、行や列の区切り、ヘッダーの階層、セルの結合といったレイアウト情報のみに焦点を当てて学習を行う。これにより、モデルは表の「骨格」を純粋に把握する能力を獲得する。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related