自己検証のジレンマ:LLMの推論における過剰なチェックの経験駆動型抑制
大規模推論モデル(LRM)の思考過程において、反省ステップの約4割から6割が中間結果の再確認(再チェック)であり、そのうち85%から95%という圧倒的多数が誤りを修正しない冗長なものであることが判明しました。
TL;DR(結論)
大規模推論モデル(LRM)の思考過程において、反省ステップの約4割から6割が中間結果の再確認(再チェック)であり、そのうち85%から95%という圧倒的多数が誤りを修正しない冗長なものであることが判明しました。 本研究では、過去の検証結果を蓄積した「経験プール」を参照し、不要な再チェックを推論時に動的に抑制する新しいテストタイムフレームワークを導入することで、戦略的な思考修正を維持したまま計算資源の無駄を省く手法を提案しました。 この手法を複数のモデルと数学的ベンチマークで検証した結果、回答精度を維持または向上させつつ、推論に使用されるトークン数を最大で20.3%削減することに成功し、効率的かつ信頼性の高い推論の実現可能性を実証しました。
なぜこの問題か
大規模言語モデル(LLM)は複雑な推論タスクにおいて飛躍的な進歩を遂げており、特にOpenAI o1やDeepSeek-R1に代表される大規模推論モデル(LRM)は、強化学習を通じて長い思考の連鎖(CoT)を生成し、人間のように自己反省や自己修正を行う能力を獲得しています。これらのモデルは、推論の過程で自らの思考を監視し、必要に応じて修正を加えることで高い信頼性を実現していますが、この強力なメカニズムには「オーバーシンキング(考えすぎ)」という深刻な副作用が伴うことが明らかになってきました。モデルがすでに十分な証拠を確保しているにもかかわらず、執拗に計算を繰り返したり、自明な中間結果を何度も検証したりすることで、膨大な計算資源が浪費されるという課題が浮き彫りになっています。 本研究の大規模な実証分析によれば、モデルが生成する反省ステップの多くは、推論戦略を根本から見直す「リシンク(再考)」ではなく、単に直前の計算が正しいかを確認するだけの「再チェック(自己検証)」に費やされています。さらに、これらの再チェックが実際に推論の誤りを特定し、最終的な回答を修正するケースは極めて稀であることが判明しました。…
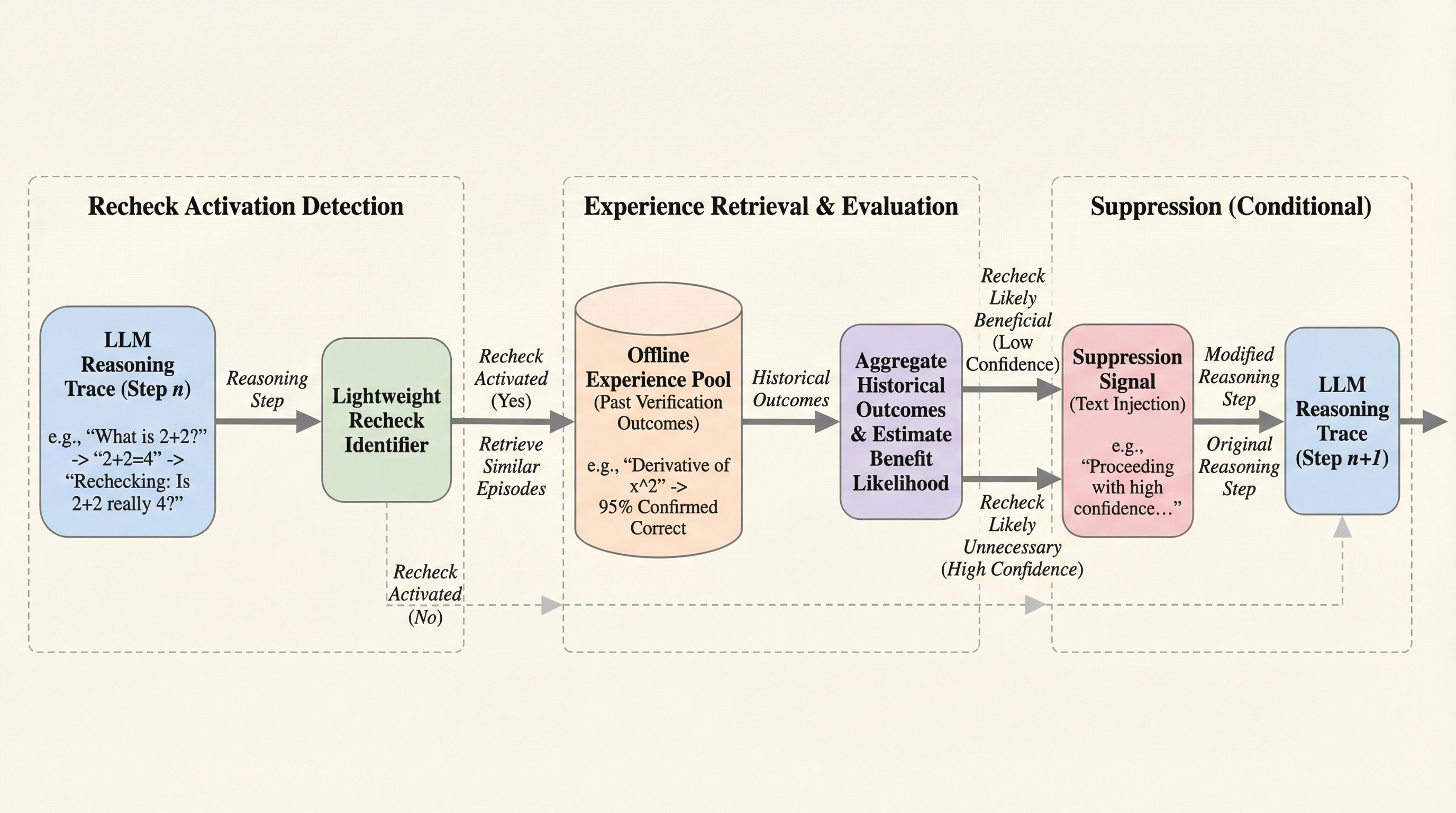
核心:何を提案したのか
本研究は、人間の問題解決プロセスにおける知恵に着想を得た「経験駆動型テストタイムフレームワーク」を提案しています。人間が数学の問題を解く際、微分などの慣れ親しんだ操作や標準的な制約の確認において、過去に同様の操作で失敗しなかったという経験に基づき、すべてのステップを再チェックすることなく自信を持って推論を進めることができます。この「選択的な自己検証」のメカニズムをAIの推論プロセスに導入することが、本提案の核心的なアイデアです。このフレームワークは、モデルの内部パラメータを一切変更することなく、推論時に外部から動的に介入する手法を採用しているため、既存のあらゆる大規模推論モデルに適用可能です。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related