SWE-Master:ポストトレーニングによるソフトウェアエンジニアリングエージェントの潜在能力の解放
SWE-Masterは、ソフトウェアエンジニアリング(SWE)タスクを自律的に解決するエージェントを構築するための、完全に再現可能でオープンソース化されたポストトレーニングフレームワークである。
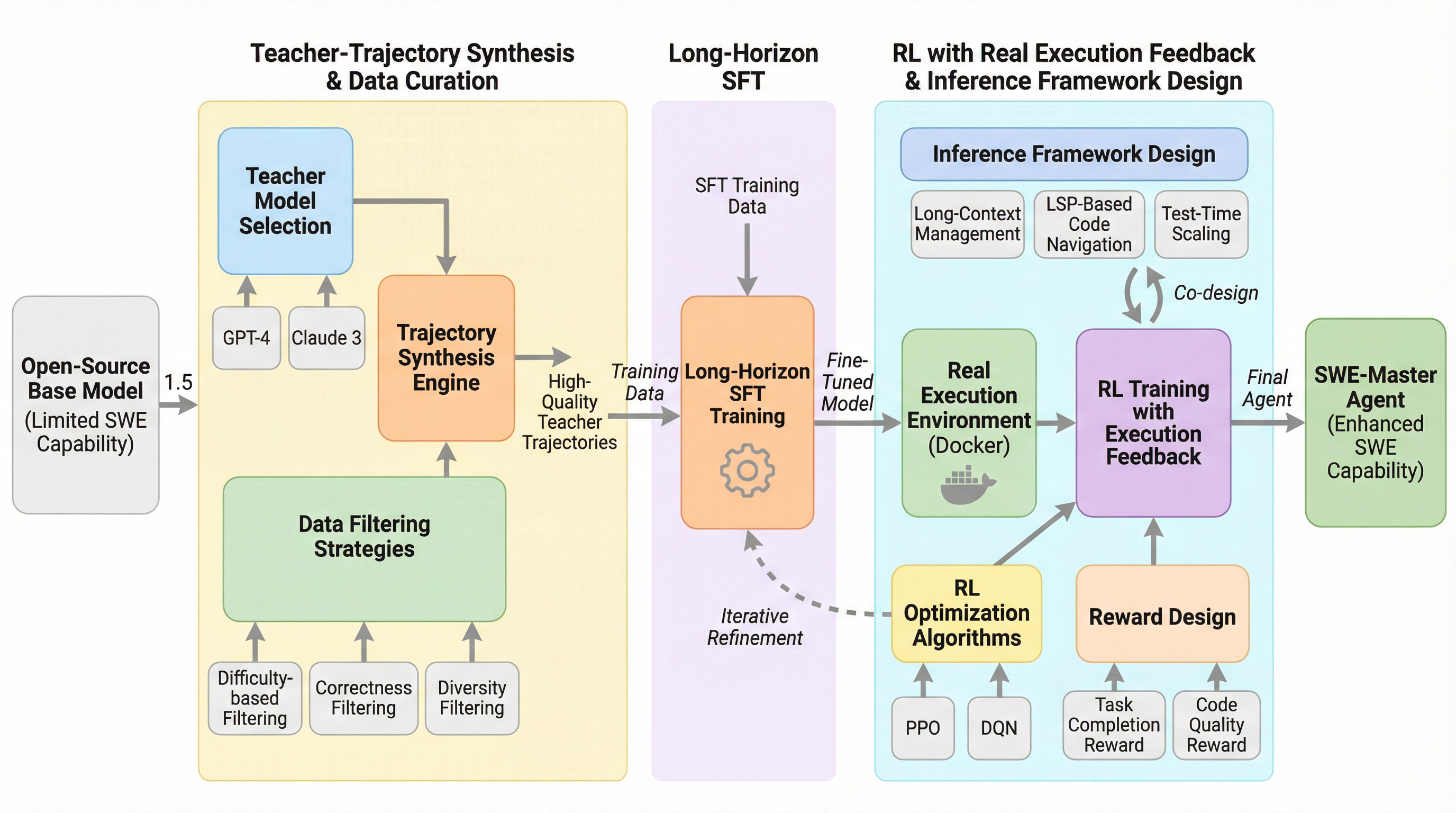
TL;DR(結論)
SWE-Masterは、ソフトウェアエンジニアリング(SWE)タスクを自律的に解決するエージェントを構築するための、完全に再現可能でオープンソース化されたポストトレーニングフレームワークである。本研究では、教師モデルによる軌跡の合成、データの精査、長文コンテキストに対応した教師あり微調整(SFT)、および実際の実行フィードバックを用いた強化学習(RL)を体系的に組み合わせる手法を提案している。 Qwen2.5-Coder-32Bを基盤モデルとして採用し、標準的なベンチマークであるSWE-bench Verifiedにおいて61.4%という高い解決率を達成しており、これは既存のオープンソースのベースラインを大幅に上回る数値である。さらに、LLMベースの環境フィードバックを活用したテスト時スケーリング(TTS)を導入することで、解決率は最大で70.8%にまで到達し、Pass@8の設定では76.2%という極めて高い性能の可能性を示している。 本フレームワークは、データ処理から推論フレームワークに至るまでの全工程を透明化しており、LSP(Language Server Protocol)を活用したコードナビゲーション機能の実装により、効率的かつ構造的なリポジトリの理解を可能にしている。これにより、従来は不透明だったSWEエージェントの開発プロセスを標準化し、学術コミュニティにおける再現可能な研究を促進するための実用的な基盤を提供することを目指している。
なぜこの問題か
ソフトウェア開発の自動化において、大規模言語モデル(LLM)を基盤としたソフトウェアエンジニアリングエージェントは、複雑なタスクを解決するための強力なパラダイムとして注目されている。従来の手法は短いコード断片の生成に焦点を当てていたが、現代のエージェントには自然言語による要件の理解、大規模なコードベースの探索、複数ファイルにわたる修正、テストの実行、そして解決策の反復的な改善が求められる。しかし、現在の最先端システムの多くは、トレーニングデータの構築方法や最適化の手順が不透明であり、再現性が著しく欠如しているという深刻な課題がある。特に、長期間の推論と現実的な環境との相互作用を捉える高品質な教師軌跡を効率的に構築することは極めて困難である。 また、エージェントのトレーニングは通常、教師あり微調整(SFT)と強化学習(RL)の2段階のパラダイムに従うが、これにはデータの多様性と難易度のバランスをどう取るか、報酬設計をどう安定させるかといった繊細な調整が必要となる。これらの詳細が公開されていないことが多く、多くの研究者にとって大きな障壁となっている。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related