FactNet: 多言語の事実根拠付けのための10億規模ナレッジグラフ
FactNetは、1.7億件の原子的な主張と316の言語版Wikipediaから抽出された30.1億件の証拠ポインタを統合した、世界最大規模の多言語ナレッジグラフであり、LLMのハルシネーション抑制に不可欠な追跡可能な根拠を提供する。
TL;DR(結論)
FactNetは、1.7億件の原子的な主張と316の言語版Wikipediaから抽出された30.1億件の証拠ポインタを統合した、世界最大規模の多言語ナレッジグラフであり、LLMのハルシネーション抑制に不可欠な追跡可能な根拠を提供する。 決定論的な構築パイプラインを採用することで、全ての証拠をバイトレベルの精度で元のソースから復元可能にし、人間による監査で92.1%という極めて高い根拠付け精度を達成しており、情報の透明性と監査可能性を極限まで高めている。 知識グラフ補完、質問回答、事実検証を含む包括的な評価スイート「FactNet-Bench」を同時に提供し、信頼性の高い多言語AIシステムの訓練と評価のための再現可能な基盤リソースとして、オープンソースで公開されている。
なぜこの問題か
現在の大規模言語モデル(LLM)は驚異的な流暢さを持つ一方で、知識集約的なタスクにおいて事実関係が不安定になり、もっともらしい嘘をつくハルシネーション(捏造)が深刻な課題となっている。この問題を解決するには、生成された主張を検索可能で追跡可能な証拠に結びつける「根拠付け(Grounding)」が不可欠であるが、既存のリソースには大きな制約が存在していた。例えば、Wikidataのような知識ベースは大規模で構造化されているものの、検証に必要なテキストベースの証拠が欠落しており、一方でFEVERやAveriTeCのような検証用データセットは人間による手作業で作成されているため、規模や言語の網羅性が極めて限定的である。 また、機械翻訳やLLMを用いた合成データによって規模を拡張しようとする最近の手法は、エラーの伝播や翻訳ミスの導入を招きやすく、何よりも人間が執筆した元の文書との接続が断たれるため、情報の出所(プロベナンス)の監査可能性が損なわれるという致命的な欠点がある。…
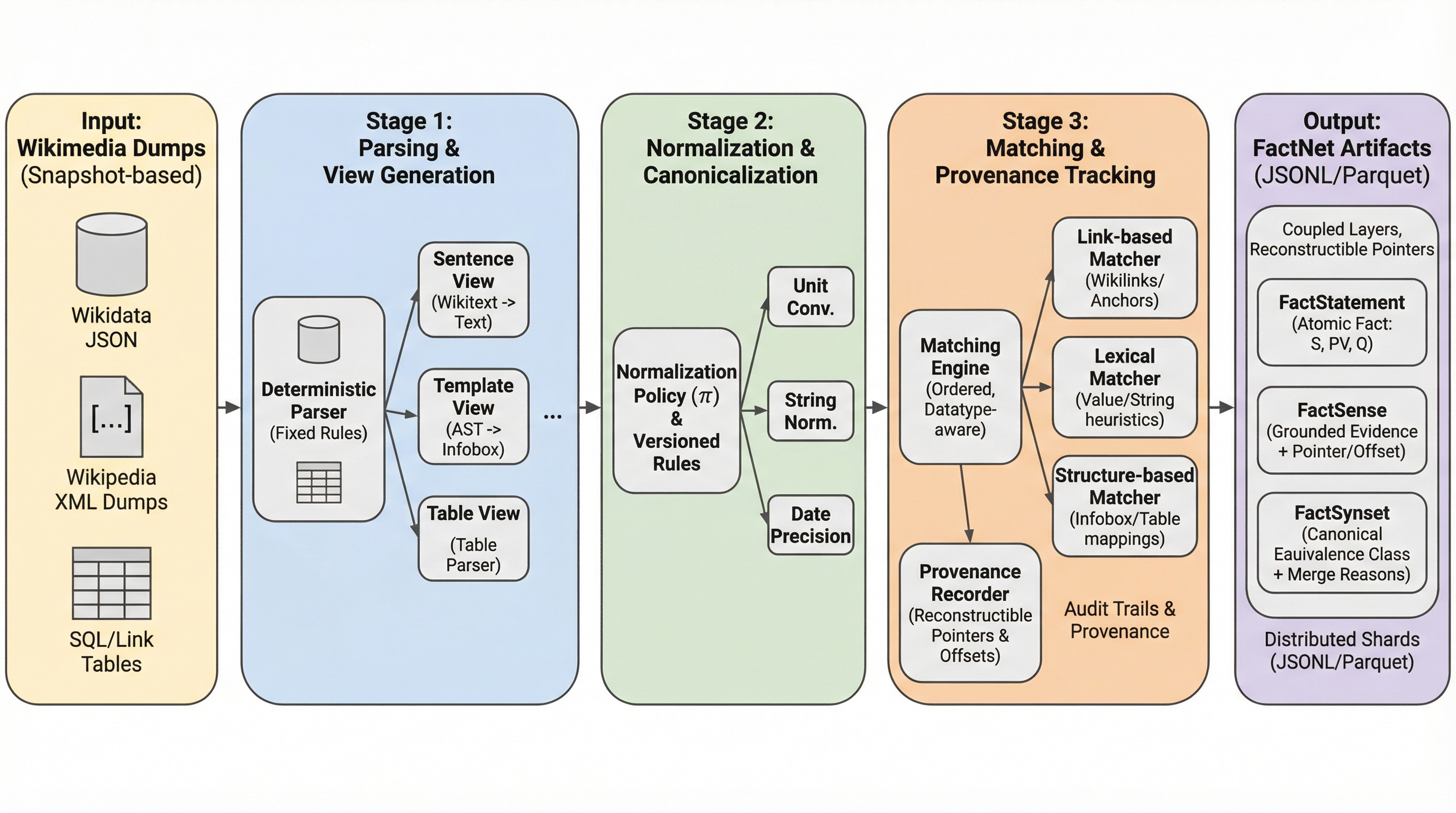
核心:何を提案したのか
本研究では、1.7億件の原子的な主張(FactStatement)と、316のWikipedia言語版から得られた30.1億件の監査可能な証拠ポインタ(FactSense)を統合した、オープンソースの巨大リソース「FactNet」を提案した。FactNetの最大の特徴は、確率的なモデルや機械学習による推論を一切排除した「厳密に決定論的な構築パイプライン」を採用している点にある。これにより、全ての証拠ユニットをバイトレベルの精度で元のソースから復元することが可能となり、データの信頼性と再現性を担保している。 グラフの構造は、情報の粒度と役割に応じて3つの層で構成されている。第一層の「FactStatement」は、Wikidataの主張をベースにした言語に依存しない原子的な単位であり、修飾子や参照情報を含んでいる。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related