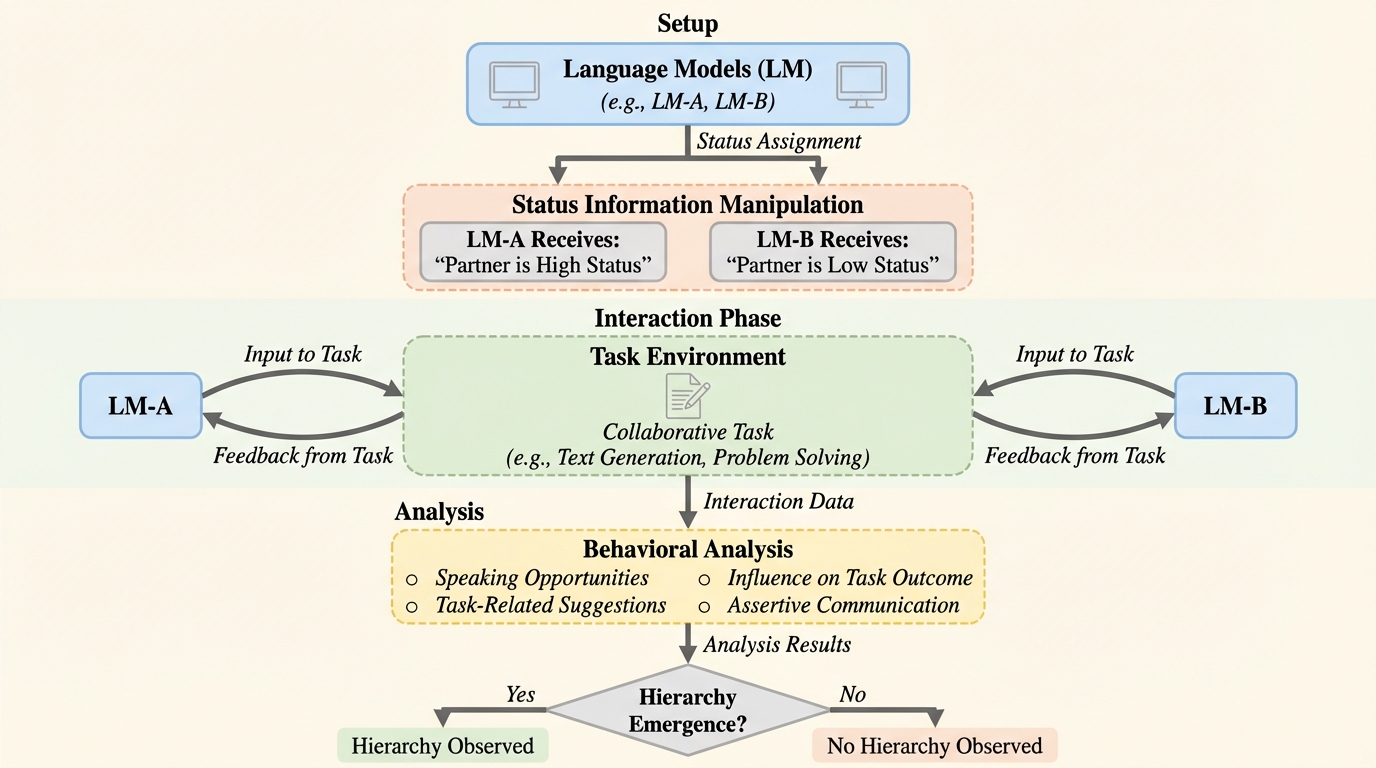
言語モデルにおける地位の階層構造
人間の社会組織に普遍的な「地位の階層構造」が言語モデル間でも発生するかを検証するため、感情分類タスクを用いたマルチエージェント環境での実験が行われ、能力が同等のモデル間では専門家やリーダーといった明示的な地位の割り当てによって、下位モデルが上位モデルに従う「譲歩」の非対称性が35ポイント確認された。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
人間の社会組織に普遍的な「地位の階層構造」が言語モデル間でも発生するかを検証するため、感情分類タスクを用いたマルチエージェント環境での実験が行われ、能力が同等のモデル間では専門家やリーダーといった明示的な地位の割り当てによって、下位モデルが上位モデルに従う「譲歩」の非対称性が35ポイント確認された。
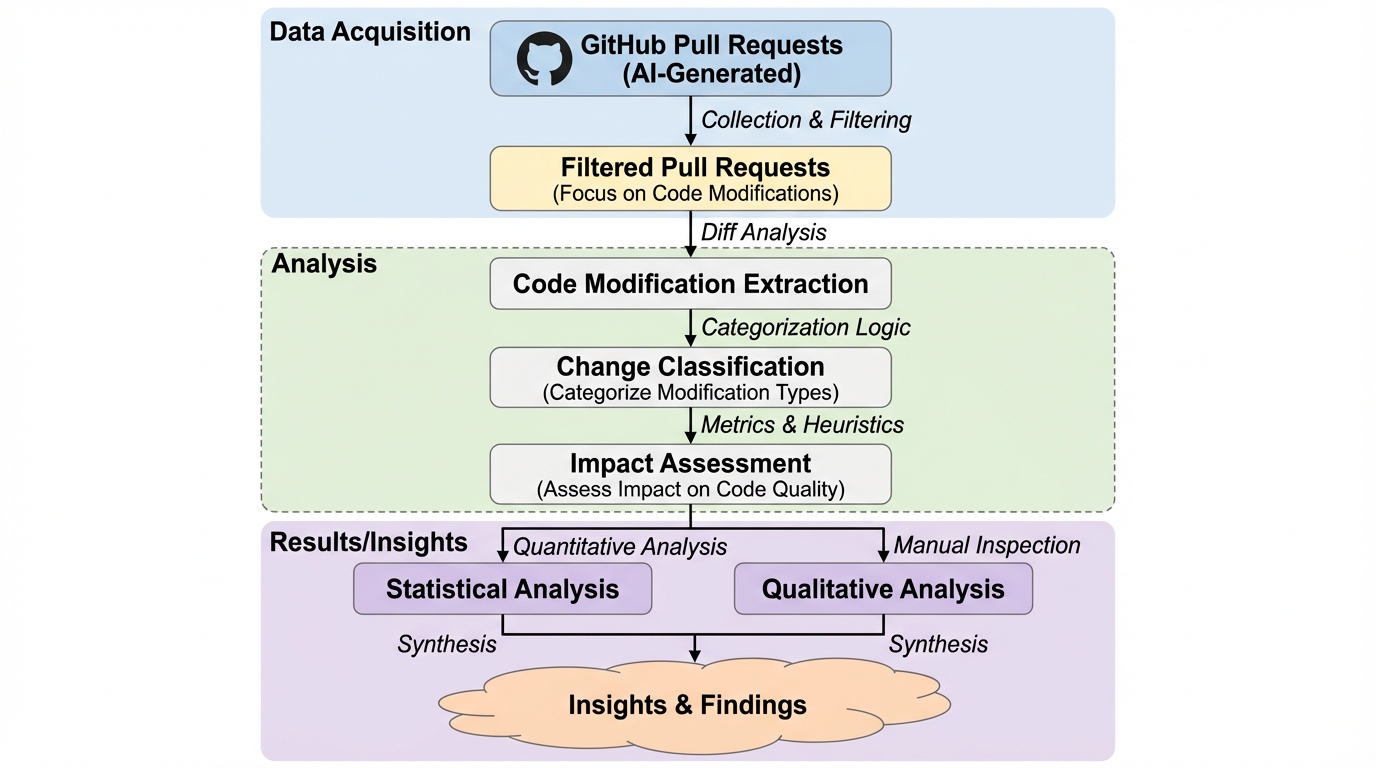
AIエージェントと人間によるGitHubのプルリクエストを大規模に比較した結果、エージェントは人間よりも小規模かつ局所的なコード修正を行う傾向があり、特にコミット数において顕著な差(Cliff’s $\delta=0.5429$)があることが判明しました。
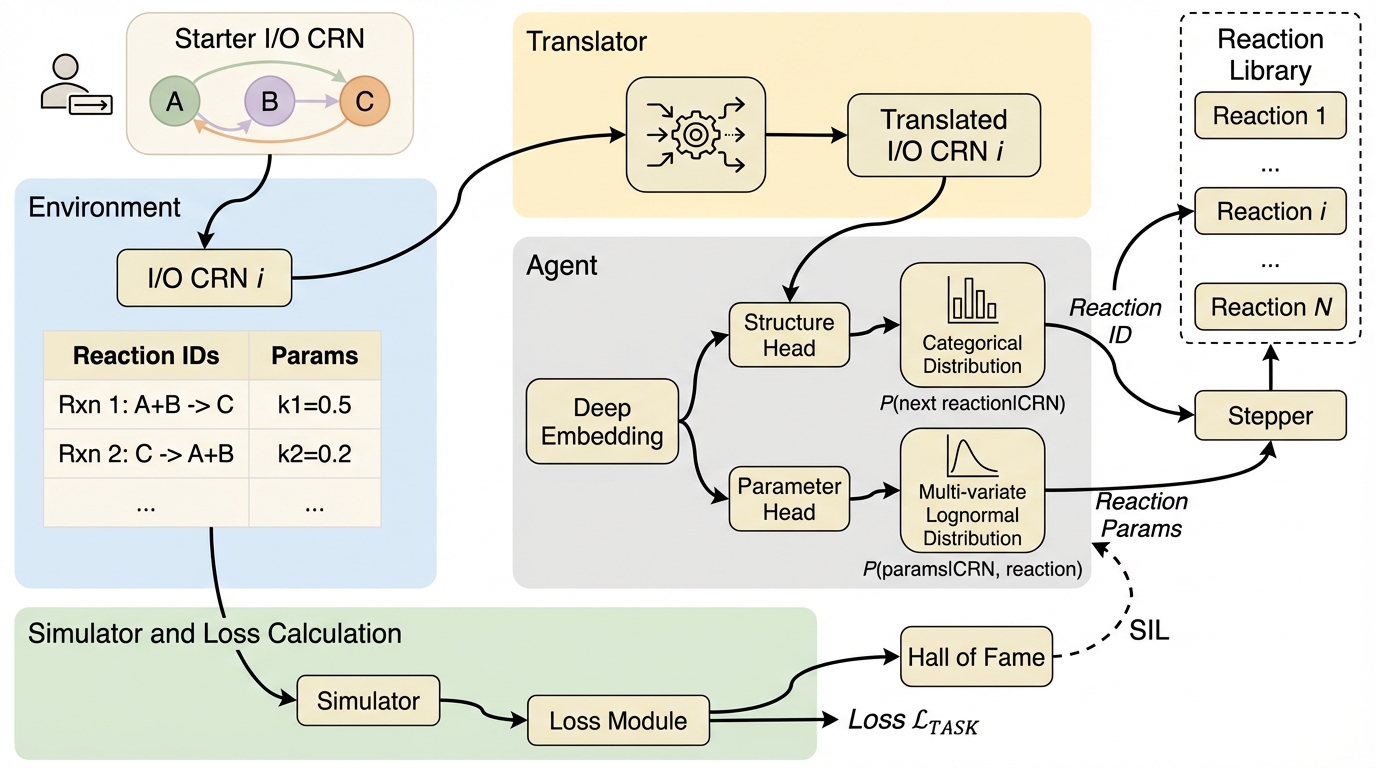
GenAI-Netは、特定の動的機能を持つ生体分子ネットワークの設計を自動化する生成AIフレームワークであり、反応を提案するAIエージェントとシミュレーションによる評価をループ状に結合することで、複雑な設計課題を効率的に解決するシステムである。
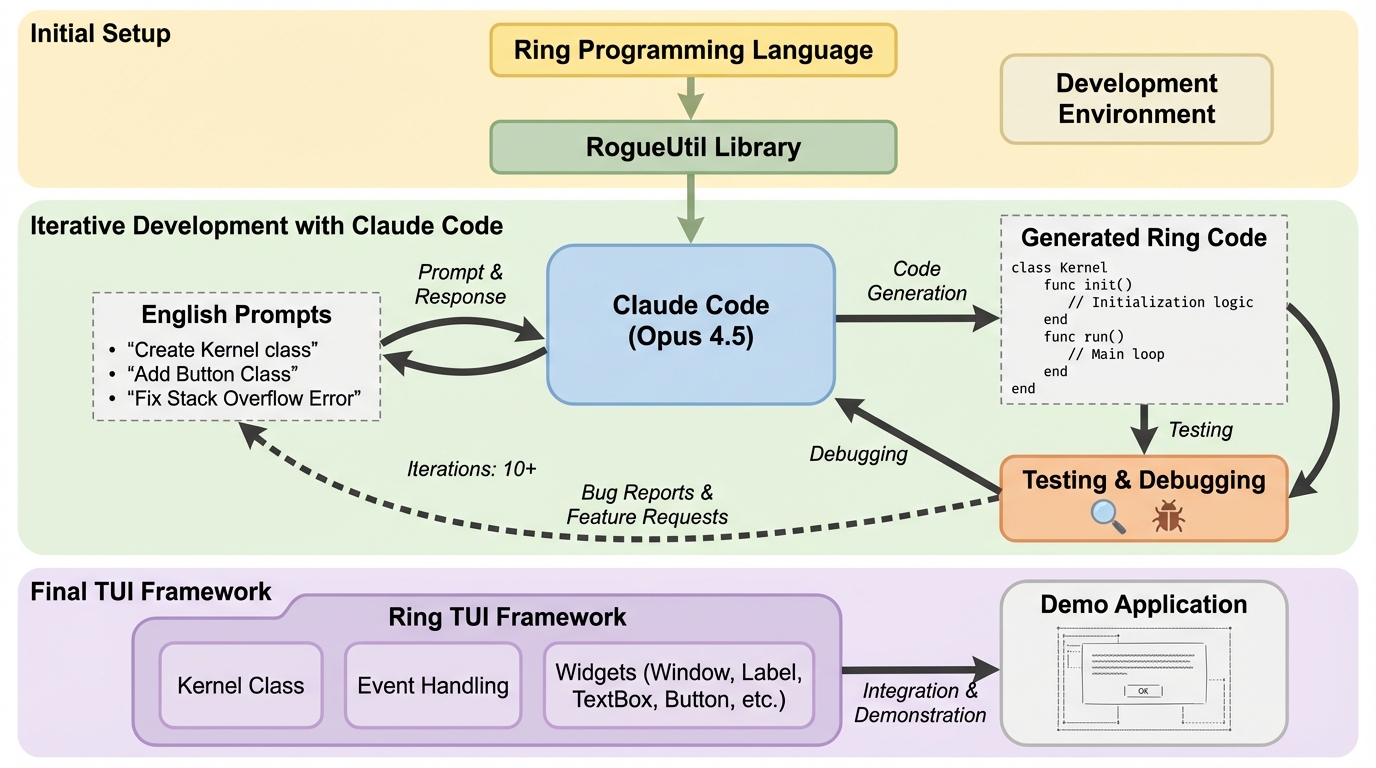
本研究は、Claude Code(Opus 4.5)を活用したプロンプト駆動開発(PDD)により、Ringプログラミング言語用の高度なターミナルユーザーインターフェース(TUI)フレームワークを構築した過程を報告するものである。
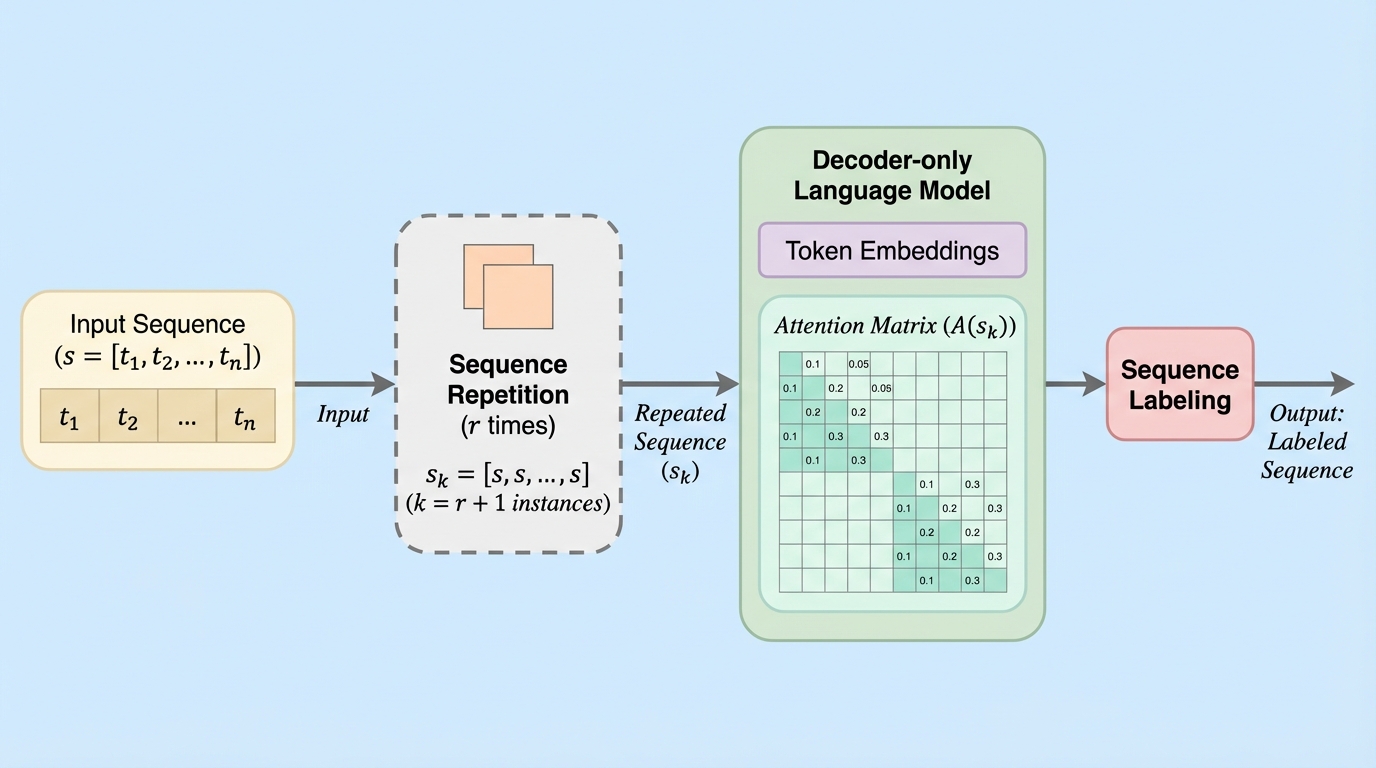
デコーダー専用言語モデルにおいて、入力系列を複数回繰り返す「系列繰り返し(SR)」という手法が、系列ラベリング(SL)タスクにおけるトークン埋め込みの質を大幅に向上させることを明らかにした。 従来の因果的マスクの除去といった侵襲的な手法とは異なり、SRはモデル構造を変更せずに双方向性を擬似的に実現し、エンコーダー専用モデルやマスク解除済みデコーダーを上回る精度を達成している。 繰り返し回数を増やすことで性能が向上する傾向があり、さらに中間層での早期終了(Early Exit)を組み合わせることで、計算コストを抑えつつ最終層と同等の高いパフォーマンスを維持できることが実証された。
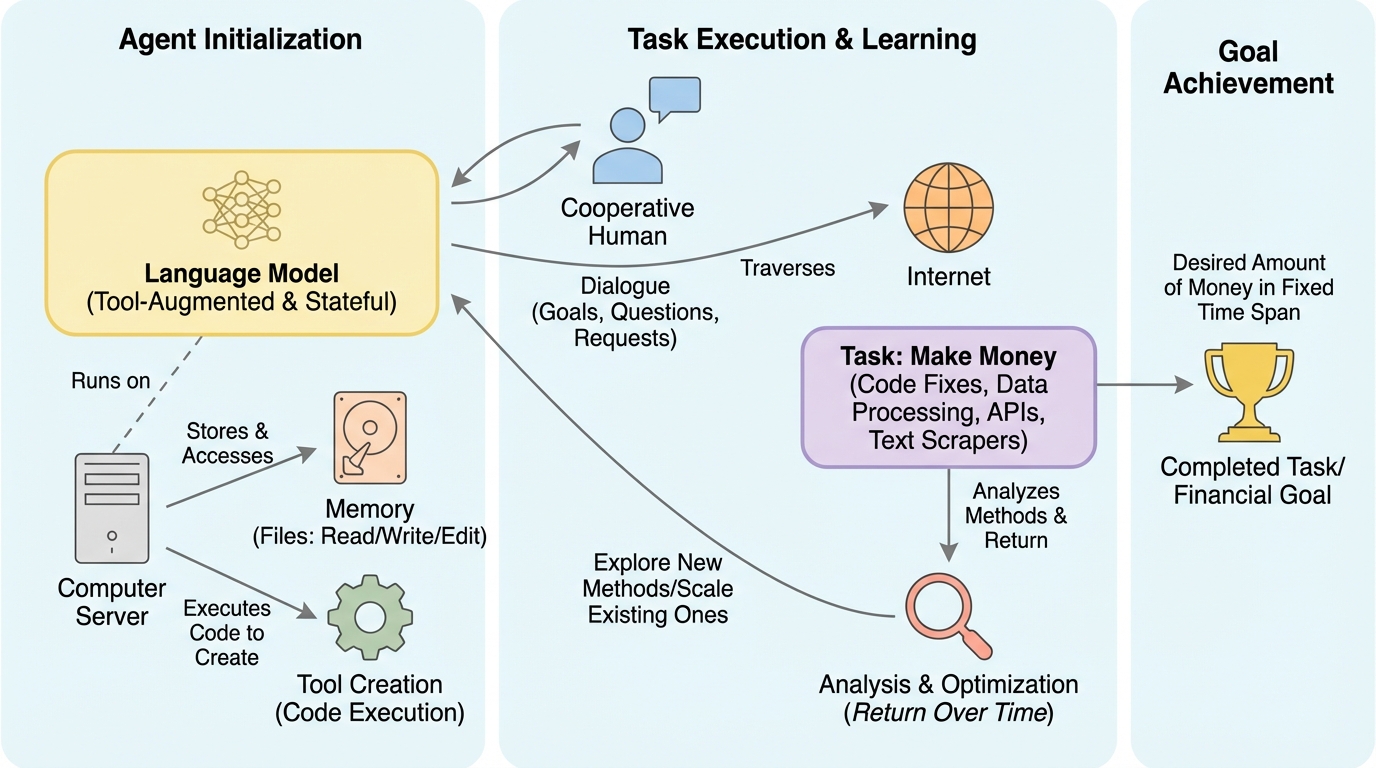
知能の成立には、記号を外部世界の参照先と結びつけて意味を付与する「グラウンディング(記号接地)」が不可欠であるが、物理的な肉体を持つ「身体性」は必須ではない。 知能を「動機付け」「信号予測」「因果関係の理解」「経験からの学習」という4つの特性の集合として定義し、これらはデジタル環境のエージェントでも達成可能であることを論じている。 大規模言語モデル(LLM)などの進展を背景に、物理世界に限定されない一貫した規則を持つ環境との相互作用こそが知能の本質であり、身体性は知能の十分条件ではあっても必要条件ではないと結論付けている。
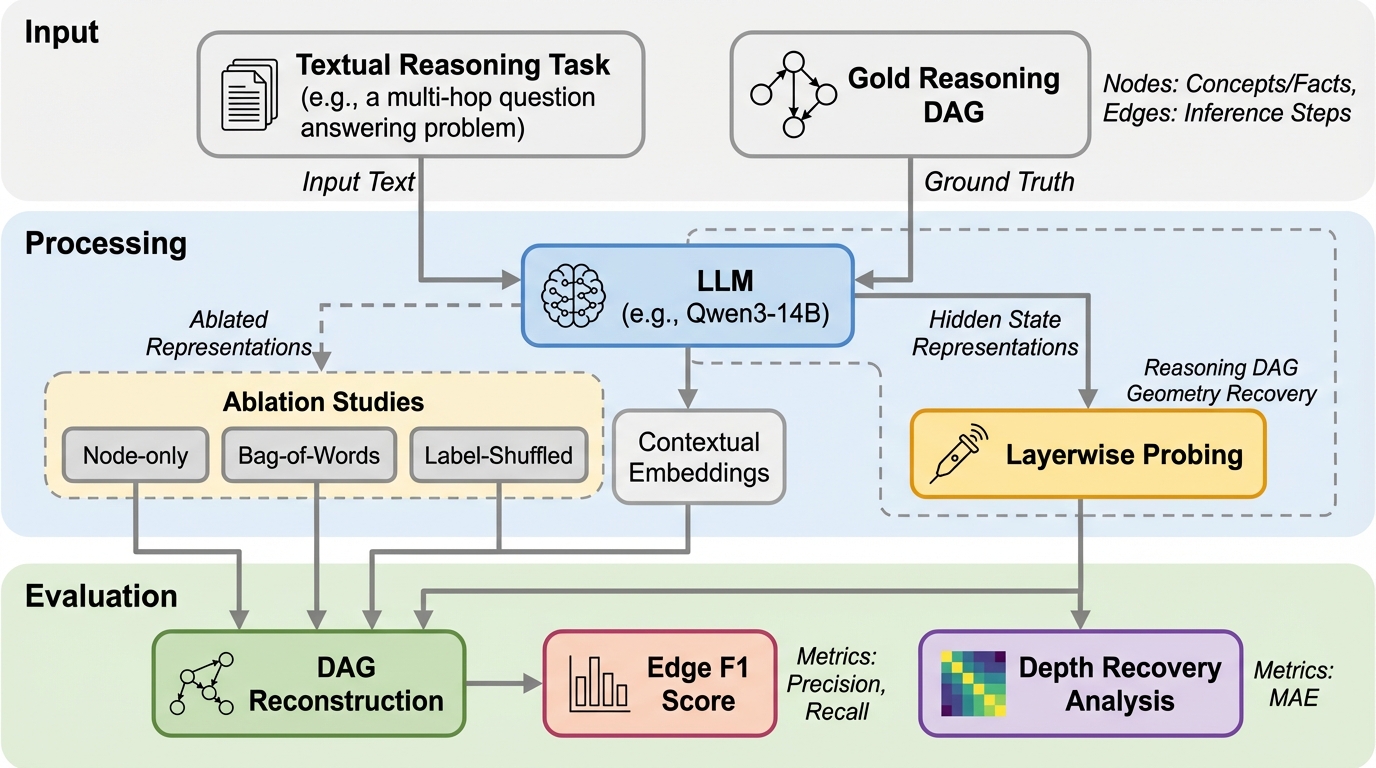
大規模言語モデル(LLM)の内部的な推論プロセスは、従来の「思考の連鎖(CoT)」のような単純な線形構造ではなく、複数の前提や分岐、再利用を含む「有向非巡回グラフ(DAG)」として空間的に符号化されていることを明らかにしました。
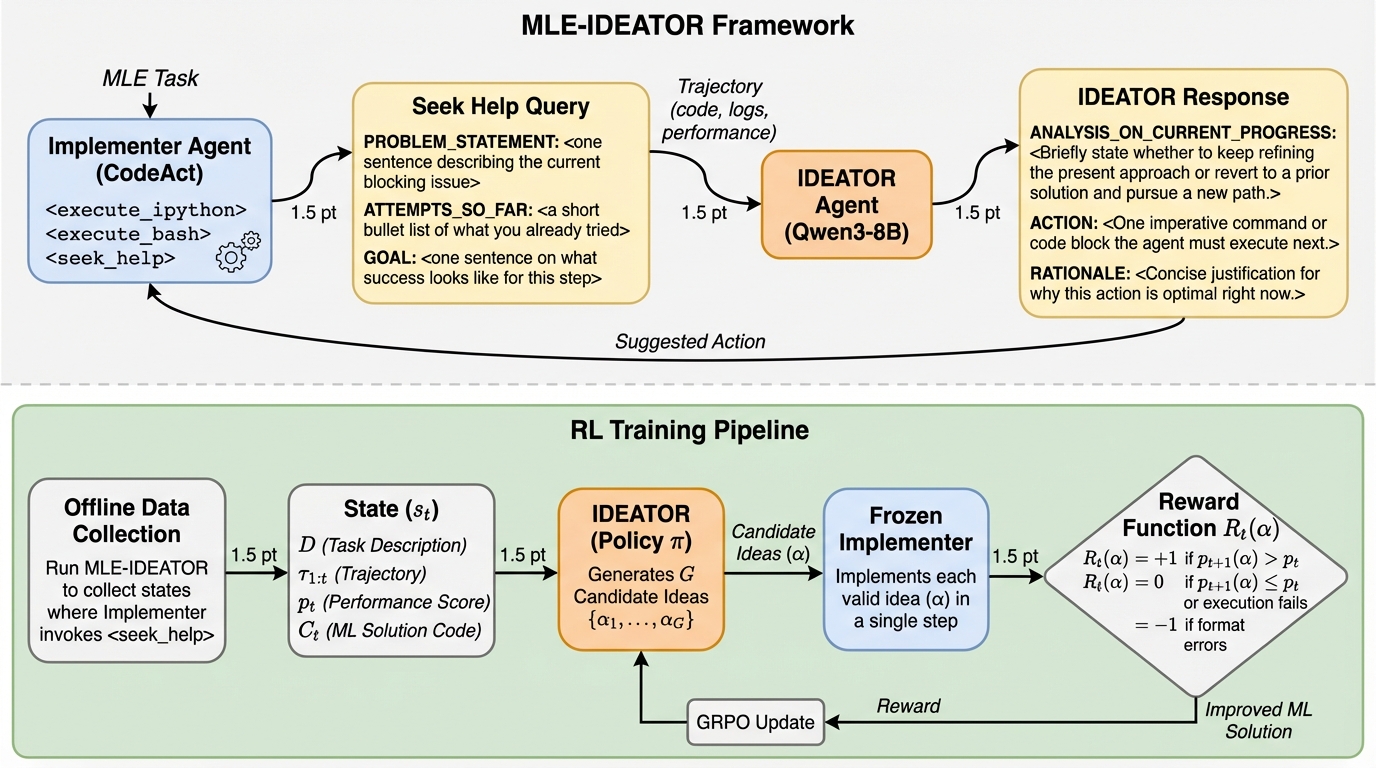
機械学習エンジニアリング(MLE)において、戦略的なアイデア創出とコード実装を分離した二層エージェント構成「MLE-IDEATOR」を開発し、従来の実装のみを行うエージェントを大幅に上回る性能を達成した。 強化学習(GRPO)を用いて軽量なQwen3-8Bモデルを訓練した結果、未訓練時と比較して11.
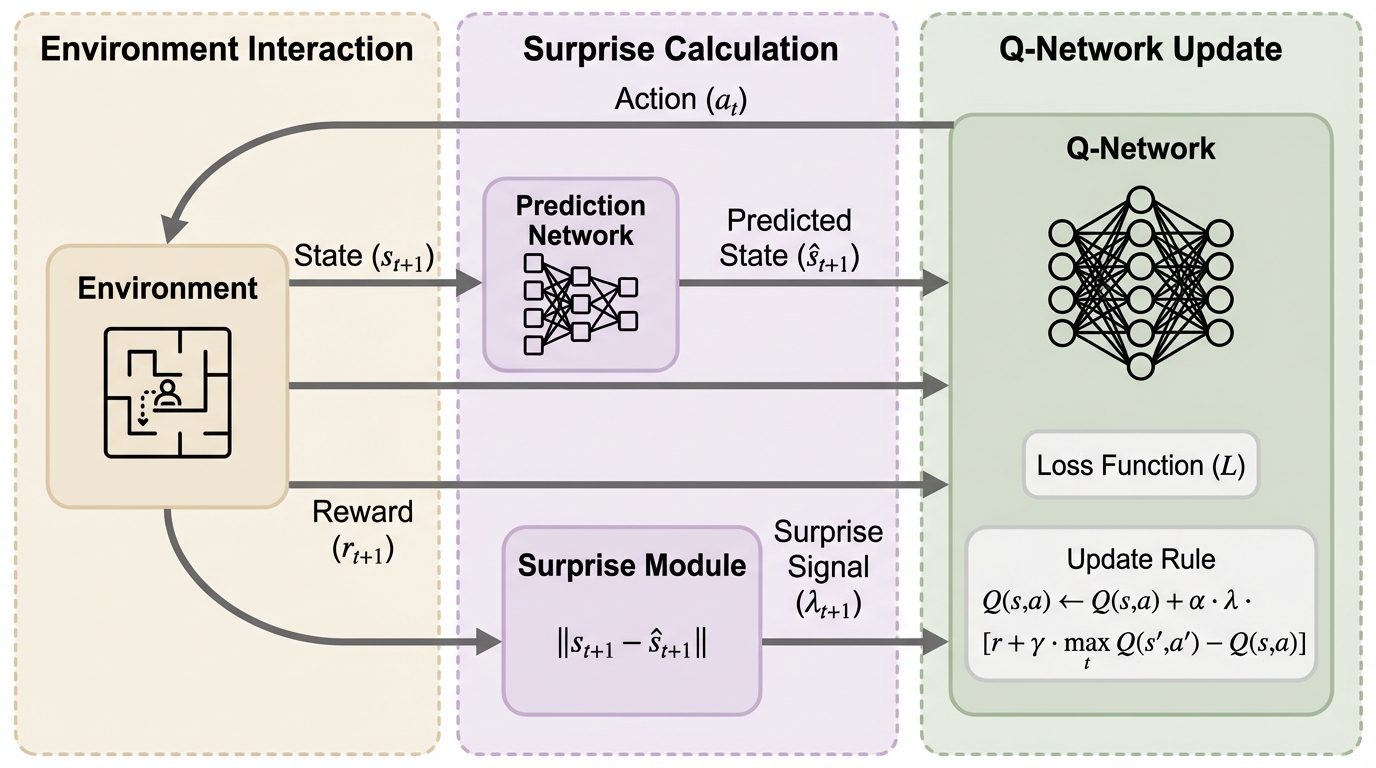
従来の深層Q学習(DQN)は固定された学習率や一律の更新スケールに依存するため、報酬が稀な「疎な報酬環境」では学習が不安定になり収束が遅れるという課題がありましたが、本研究は脳のドーパミンによる学習調整機能に着想を得た「深層内発的驚き正則化制御(DISRC)」を提案しました。
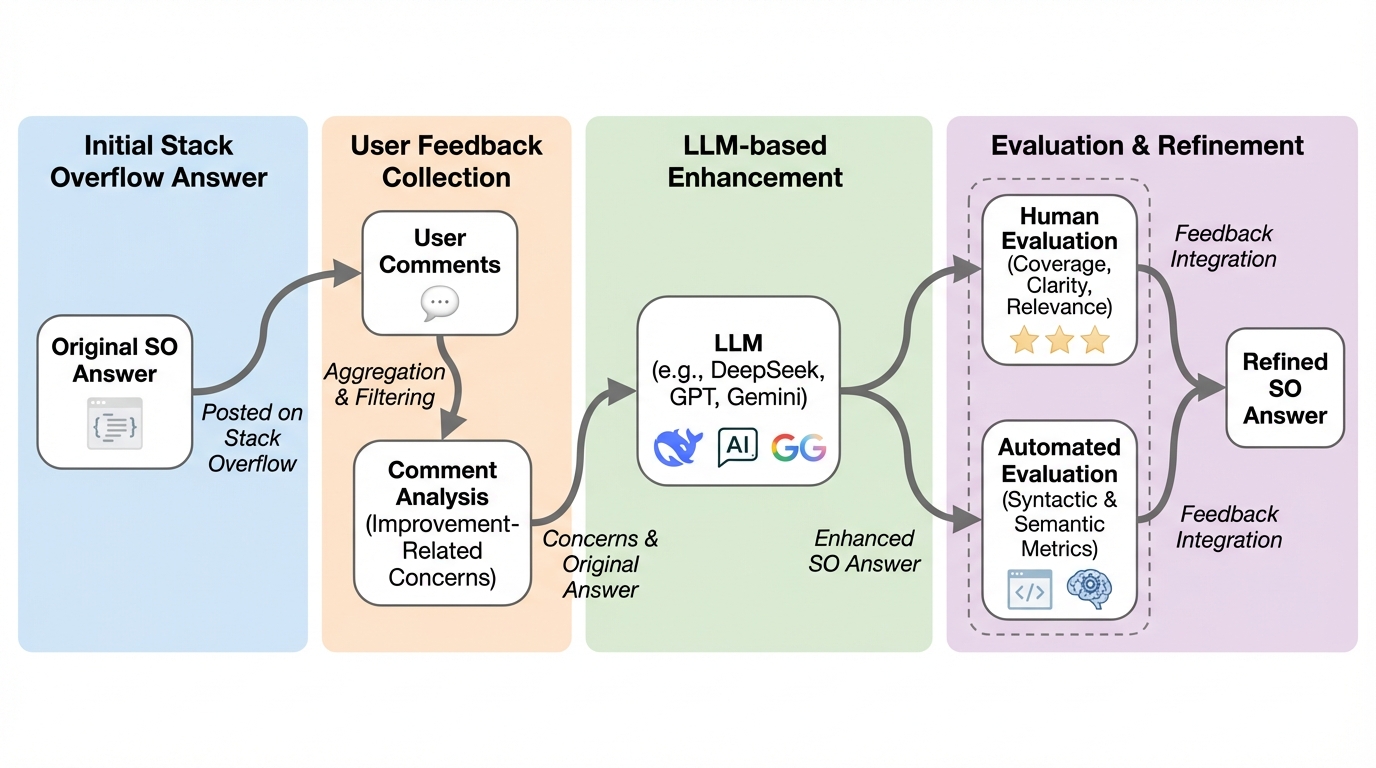
Stack Overflow等の技術Q&Aサイトでは、回答に対する有益な指摘の約3分の1が放置されており、情報の陳腐化や不完全さが深刻な課題となっているが、本研究ではLLMを用いてユーザーのフィードバックを解釈・統合し、コードと解説文の両方を人間のように改善するツール「AUTOCOMBAT」を提案し、その有効性を検証した。 58名の専門家による評価では、84.5%が導入や推奨を支持し、手動作業の削減やフィードバックの正確な反映、解説の明快さにおいて極めて高い有用性が確認された。 本研究は、LLMを単なるコード生成器としてではなく、分散した人間の知見を統合して継続的な改善を行う「応答性の高いパートナー」として位置づけ、知識ベースの信頼性と研究における有用性を高めるための新しいパラダイムを提示している。