系列の繰り返しはトークン埋め込みを強化しデコーダーのみの言語モデルによる系列ラベリングを改善する
デコーダー専用言語モデルにおいて、入力系列を複数回繰り返す「系列繰り返し(SR)」という手法が、系列ラベリング(SL)タスクにおけるトークン埋め込みの質を大幅に向上させることを明らかにした。 従来の因果的マスクの除去といった侵襲的な手法とは異なり、SRはモデル構造を変更せずに双方向性を擬似的に実現し、エンコーダー専用モデルやマスク解除済みデコーダーを上回る精度を達成している。 繰り返し回数を増やすことで性能が向上する傾向があり、さらに中間層での早期終了(Early Exit)を組み合わせることで、計算コストを抑えつつ最終層と同等の高いパフォーマンスを維持できることが実証された。
TL;DR(結論)
デコーダー専用言語モデルにおいて、入力系列を複数回繰り返す「系列繰り返し(SR)」という手法が、系列ラベリング(SL)タスクにおけるトークン埋め込みの質を大幅に向上させることを明らかにした。 従来の因果的マスクの除去といった侵襲的な手法とは異なり、SRはモデル構造を変更せずに双方向性を擬似的に実現し、エンコーダー専用モデルやマスク解除済みデコーダーを上回る精度を達成している。 繰り返し回数を増やすことで性能が向上する傾向があり、さらに中間層での早期終了(Early Exit)を組み合わせることで、計算コストを抑えつつ最終層と同等の高いパフォーマンスを維持できることが実証された。
なぜこの問題か
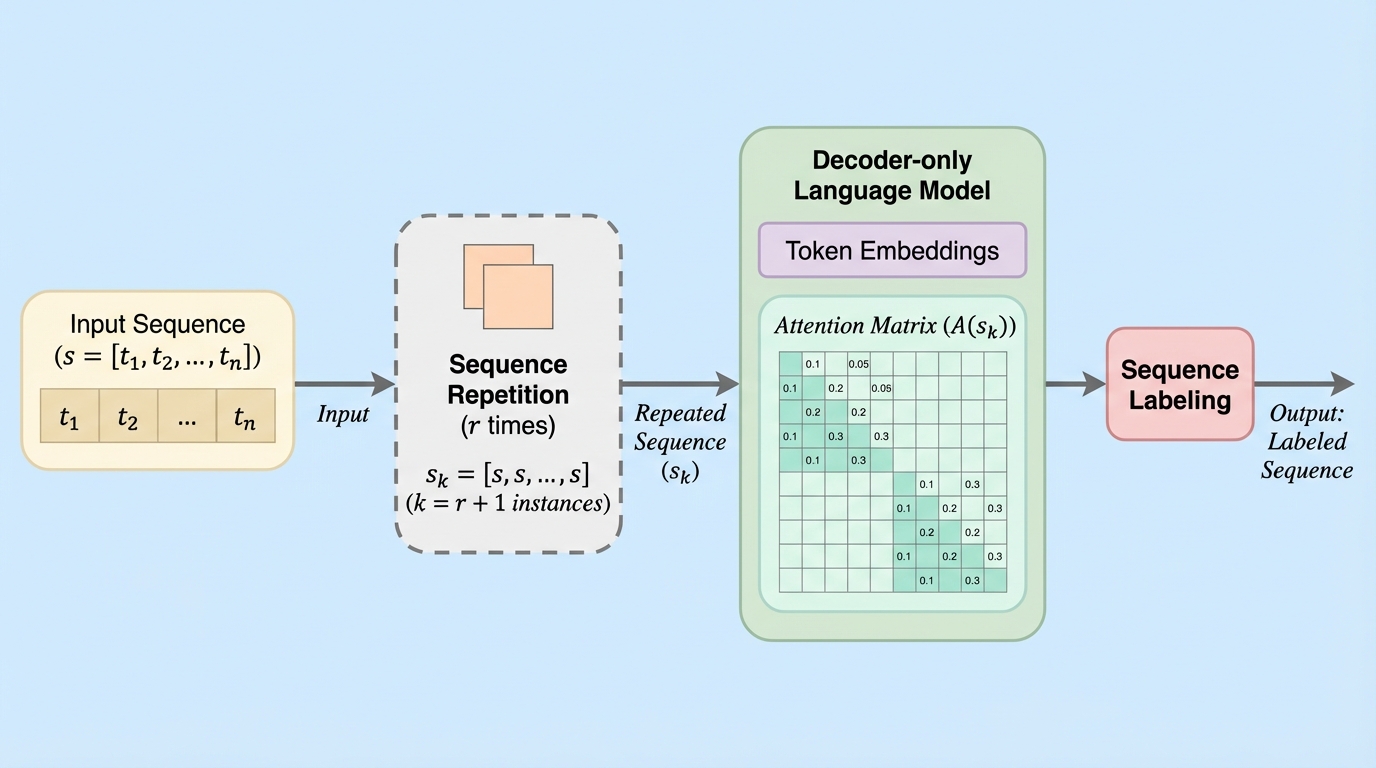
現代の自然言語処理において、言語モデルの主流は自己回帰的に学習されるデコーダー専用モデルへと移行している。しかし、これらのモデルは原理的に「過去の文脈(プレフィックス)」のみに依存して次のトークンを予測するため、系列ラベリング(SL)のようなタスクでは構造的な不利を抱えている。系列ラベリングは、固有表現抽出やイベント抽出のように、入力された各トークンに対して適切なラベルを割り当てるタスクであり、本質的に文全体の双方向的な文脈情報を必要とする。このため、歴史的にはBERTやRoBERTaのような、最初から双方向性を備えたエンコーダー専用モデルが標準的に利用されてきた。 近年、デコーダー専用モデルの規模拡大に伴い、これらを系列ラベリングに転用する試みが活発化している。一般的な手法としては、アテンション計算時の因果的マスク(Causal Mask)を取り除き、モデルを強制的にエンコーダーのように振る舞わせる「マスク解除」が提案されている。しかし、このアプローチはモデルの基本機能に大幅な変更を加える必要があり、実装上の負担が大きい。…
核心:何を提案したのか
本論文では、デコーダー専用モデルにおいて双方向性を実現するためのシンプルかつ効果的な代替案として「系列繰り返し(Sequence Repetition, SR)」を提案し、その有効性をトークンレベルのタスクで検証した。SRの基本的なアイデアは、入力系列 $s$ を $k$ 回($r$ 回の繰り返し)連続してモデルに入力することである。これにより、因果的マスクを維持したままでも、後続の繰り返しセグメントに含まれるトークンは、先行するセグメントに含まれる「未来のトークン」の情報にアクセスできるようになる。 具体的には、入力系列を複数回並べることで、アテンション行列の中に実質的な双方向ブロックが形成される。この手法の最大の利点は、モデルの内部構造やアテンションメカニズムに一切の手を加える必要がない点にある。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related