AIコーディングエージェントはいかにコードを修正するか:GitHubプルリクエストの大規模研究
AIエージェントと人間によるGitHubのプルリクエストを大規模に比較した結果、エージェントは人間よりも小規模かつ局所的なコード修正を行う傾向があり、特にコミット数において顕著な差(Cliff’s $\delta=0.5429$)があることが判明しました。
TL;DR(結論)
AIエージェントと人間によるGitHubのプルリクエストを大規模に比較した結果、エージェントは人間よりも小規模かつ局所的なコード修正を行う傾向があり、特にコミット数において顕著な差(Cliff’s $\delta=0.5429$)があることが判明しました。 修正内容と説明文の整合性については、エージェントは人間と同等かそれ以上に高い意味的類似性を示しており、自身の行った変更を正確に言語化して伝える能力が大規模なデータ解析によって裏付けられています。 エージェントの種類によって挙動に差があり、Claude CodeやOpenAI Codexは比較的広い範囲の修正を行う一方で、DevinやGitHub Copilotは一貫して特定の箇所に集中したコンパクトな修正を生成する特徴があることが明らかになりました。
なぜこの問題か
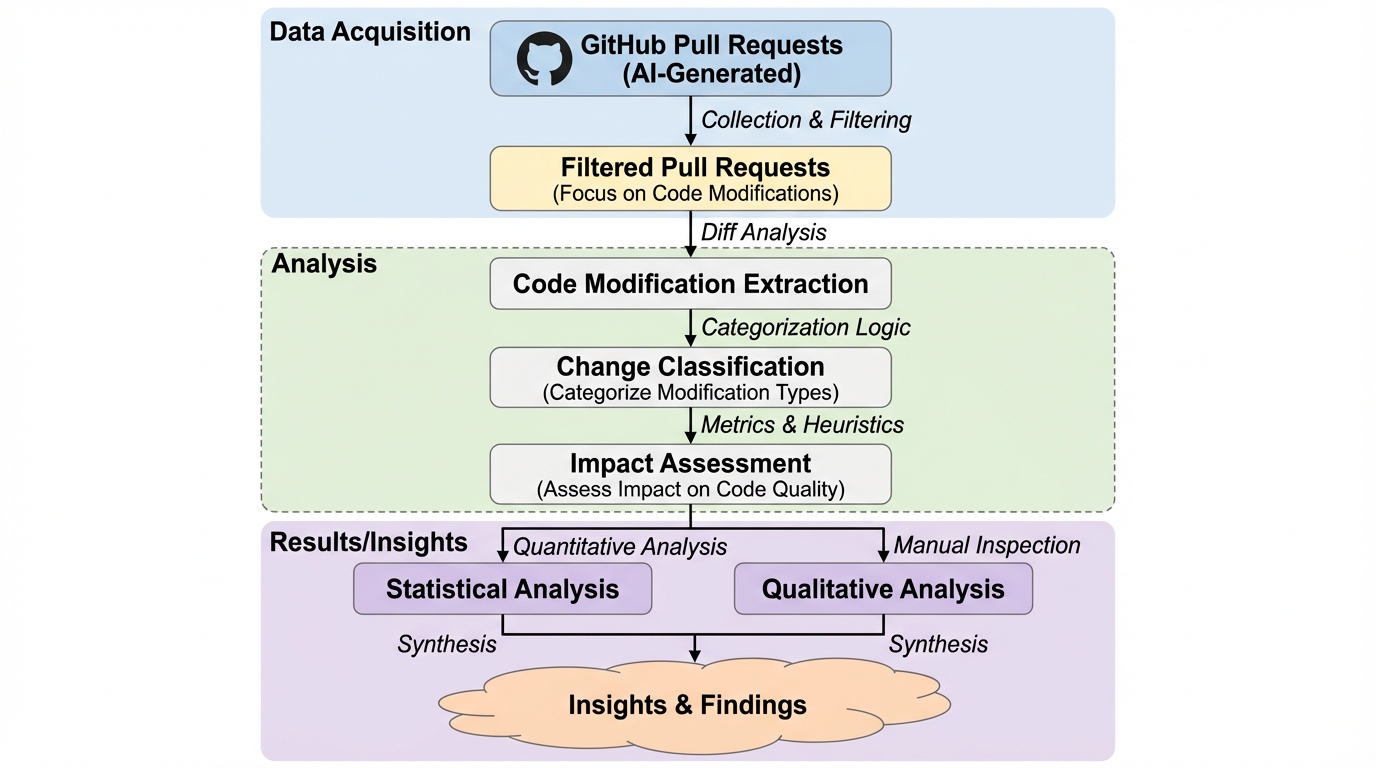
現代のソフトウェア開発において、AIコーディングエージェントは単なる補助ツールを超え、自律的な寄与者としての地位を確立しつつあります。GitHub Copilot、OpenAI Codex、Claude Code、Cursor、Devinといった高度なツールは、バグの修正や新機能の実装を自ら行い、プルリクエストを提出する能力を備えています。このような変化は「ソフトウェア工学3.0」への移行を象徴する重要なステップですが、エージェントが生成したプルリクエストが、熟練した人間による貢献とどのように異なるのかについては、これまで大規模な実証的証拠が不足していました。 特に、エージェントがソースコードをどのように構造的に変更し、その変更内容を自然言語でどのように説明しているのかを理解することは、開発ワークフローにおける信頼性や保守性を評価する上で極めて重要です。既存の研究の多くは、開発者がAIの提案をどのように受け入れるかや、生産性がどれほど向上するかといった点に焦点を当てており、自律的なAIエージェントが作成したプルリクエストそのものを大規模に分析した例は限られていました。…
核心:何を提案したのか
本研究は、AIコーディングエージェントと人間によるプルリクエストの差異を多角的に明らかにするため、大規模な実証的比較分析を提案し実施しました。分析の対象となったのは、AIDevデータセットに含まれる24,014件のマージ済みエージェントによるプルリクエスト(計440,295コミット)と、5,081件の人間によるプルリクエスト(計23,242コミット)です。これほど大規模なデータセットを用いて、エージェントの挙動を人間と比較した研究は他に類を見ません。 研究の柱は大きく分けて二つのリサーチクエスチョンで構成されています。一つ目は、追加行数、削除行数、修正ファイル数、コミット数といった「構造的特性」の比較です。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related