深層内発的驚き正則化制御(DISRC):疎な環境における効率的な深層Q学習のための生物学に着想を得た機構
従来の深層Q学習(DQN)は固定された学習率や一律の更新スケールに依存するため、報酬が稀な「疎な報酬環境」では学習が不安定になり収束が遅れるという課題がありましたが、本研究は脳のドーパミンによる学習調整機能に着想を得た「深層内発的驚き正則化制御(DISRC)」を提案しました。
TL;DR(結論)
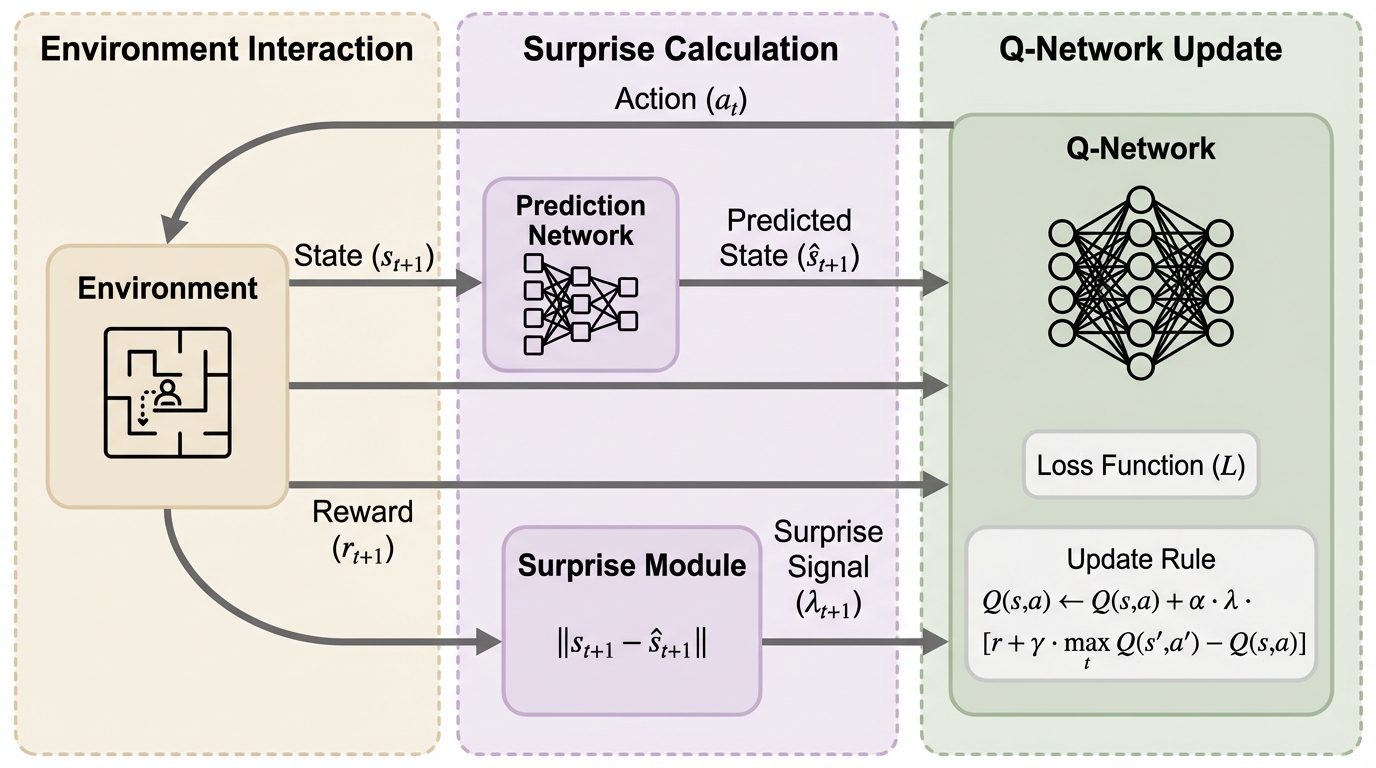
従来の深層Q学習(DQN)は固定された学習率や一律の更新スケールに依存するため、報酬が稀な「疎な報酬環境」では学習が不安定になり収束が遅れるという課題がありましたが、本研究は脳のドーパミンによる学習調整機能に着想を得た「深層内発的驚き正則化制御(DISRC)」を提案しました。 DISRCは、潜在空間における「驚き(期待からの逸脱)」の強度に基づいてQ値の更新幅を動的に調整する仕組みを持ち、実験ではMiniGrid環境のDoorKeyタスクにおいて従来のDQNより33%早く目標性能に到達し、報酬のばらつきを抑えつつ高い累積報酬を達成することに成功しました。 この手法は、驚きを単なる探索の動機付けではなく、学習の強度を直接制御する信号として利用することで、自律ロボットや臨床計画といった実世界の複雑な意思決定システムにおける学習の効率性と安定性を大幅に向上させる可能性を秘めています。
なぜこの問題か
深層強化学習(DRL)は、ロボットの操作や自律航法、戦略ゲームといった高次元で複雑な領域において、エージェントが自律的に意思決定を行うための強力な枠組みを提供してきました。しかし、標準的なDeep Q-Network(DQN)をはじめとする既存のアルゴリズムには、サンプル効率の低さや学習の不安定性という深刻な限界が存在します。特に、報酬が滅多に得られない「疎な報酬環境」においては、エージェントがどの経験から重点的に学ぶべきかを判断することが難しく、学習が停滞したり、過去の経験に過剰に適合して収束が不安定になったりすることが頻繁に起こります。 従来のDQNは、時間差(TD)誤差に基づいてネットワークを更新しますが、学習率が固定されていたり、更新のスケールが一律であったりするため、環境の変化や新しい発見に対して柔軟に対応することが困難です。また、経験再生(Experience Replay)を利用する際、再生されるデータが独立同一分布(i.i.d.)の仮定に反することが多く、これが学習の不安定化を助長しています。…
核心:何を提案したのか
本研究が提案する「深層内発的驚き正則化制御(DISRC)」は、生物学的な脳の仕組みに着想を得た、DQNの新しい拡張フレームワークです。この手法の核心は、エージェントの内部的な「驚き」の信号を用いて、Qネットワークの更新強度を動的にスケーリング(調整)する自己調整機構を導入した点にあります。 具体的には、エージェントが観測した状態を抽象的な潜在空間にマッピングし、その空間内での「期待からの逸脱」を驚きとして定義します。この驚きの強さに応じて、学習の初期段階や未知の状況に遭遇した際には高い可塑性(大きな更新幅)を維持し、環境に慣れて期待通りの結果が得られるようになるにつれて、より保守的で安定重視の更新へと移行させます。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related