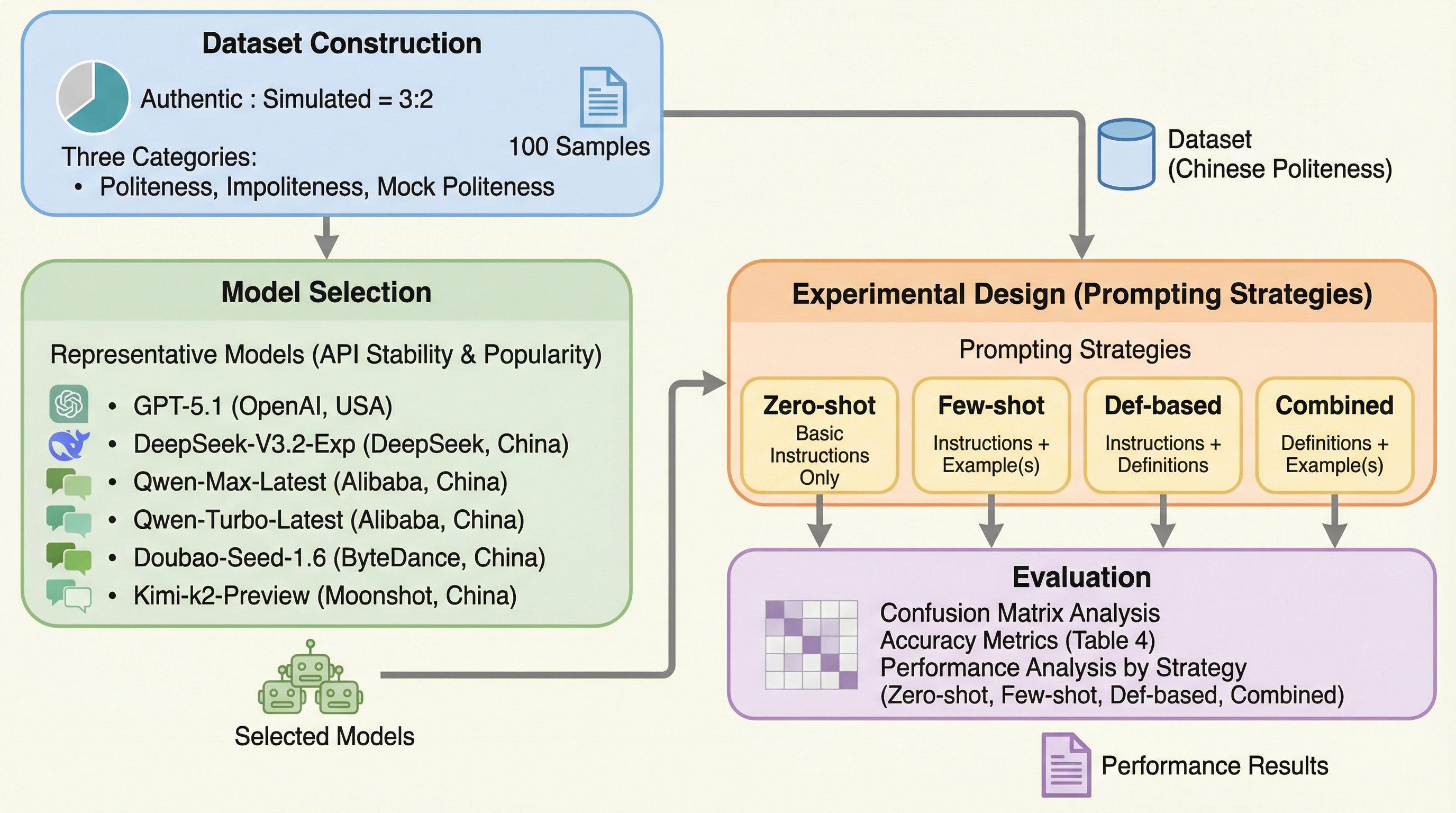
礼儀の仮面:大規模言語モデルにおける中国語の擬似的な丁寧さの理解のベンチマーク
大規模言語モデル(LLM)が中国語における「礼儀」「不作法」「虚偽の礼儀(表面上は丁寧だが裏に悪意がある表現)」をどの程度識別できるかを、GPT-5.1やDeepSeekを含む主要6モデルで体系的に評価した。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
大規模言語モデル(LLM)が中国語における「礼儀」「不作法」「虚偽の礼儀(表面上は丁寧だが裏に悪意がある表現)」をどの程度識別できるかを、GPT-5.1やDeepSeekを含む主要6モデルで体系的に評価した。
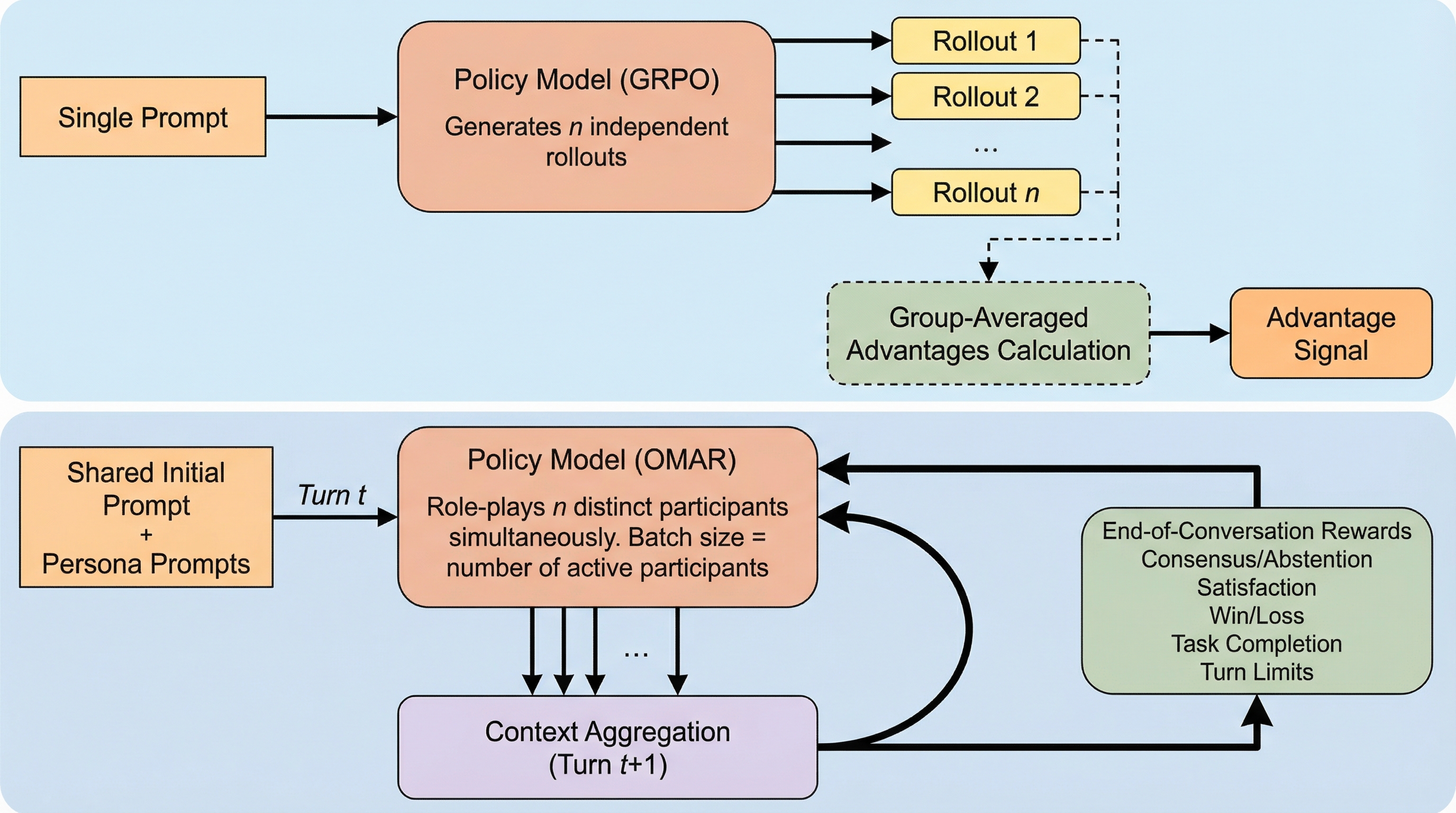
OMAR(One Model, All Roles)は、単一の言語モデルが会話内の全参加者を同時に演じ、多人数かつ多ターンの自己対話を通じて社会的知能を自律的に学習する新しい強化学習フレームワークである。
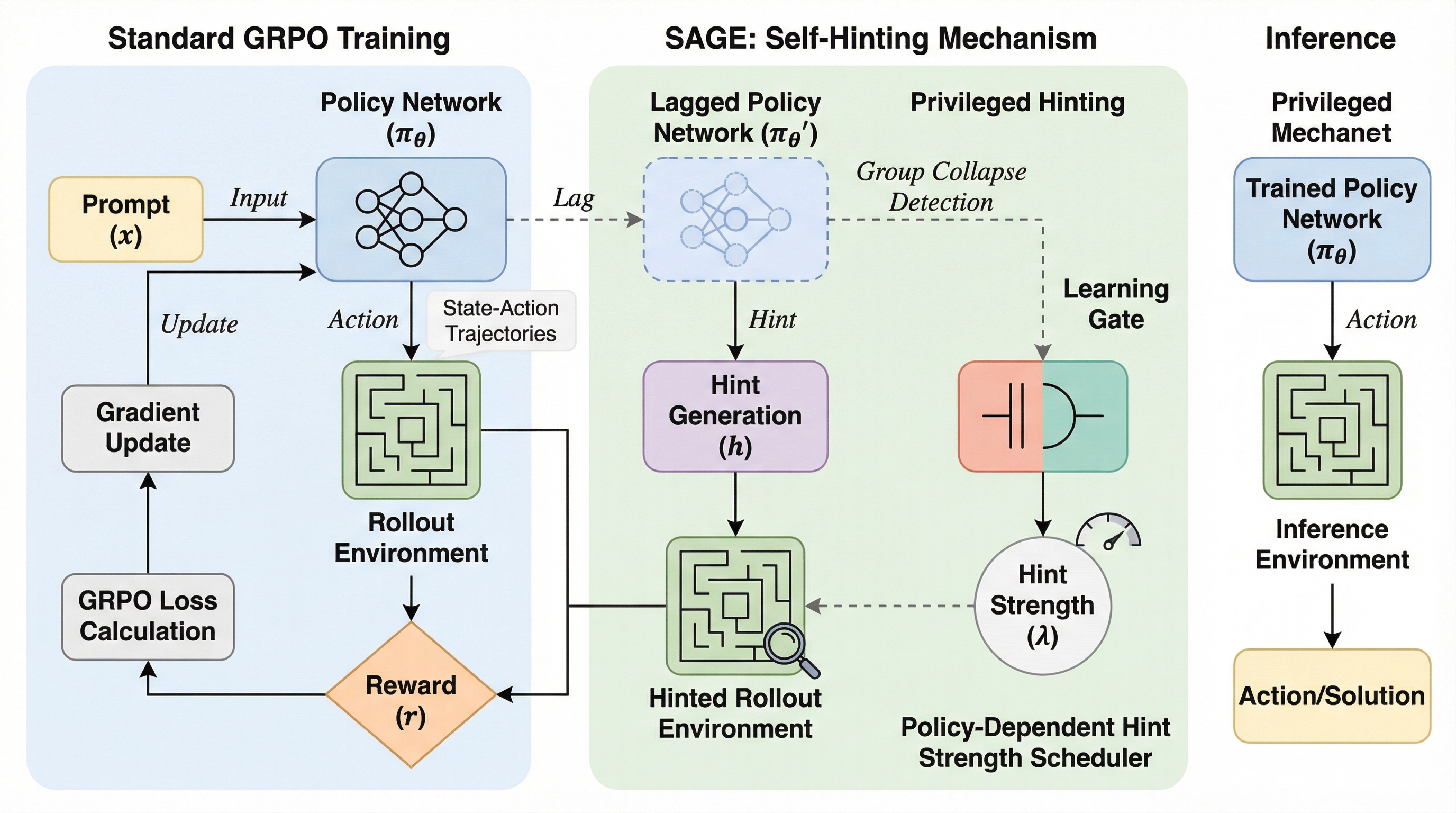
大規模言語モデルの強化学習において、難易度の高い問題で正解が全く得られず学習が停滞する「アドバンテージの崩壊」を解決するため、訓練時のみ「特権的なヒント」を導入する新手法「SAGE」が提案されました。
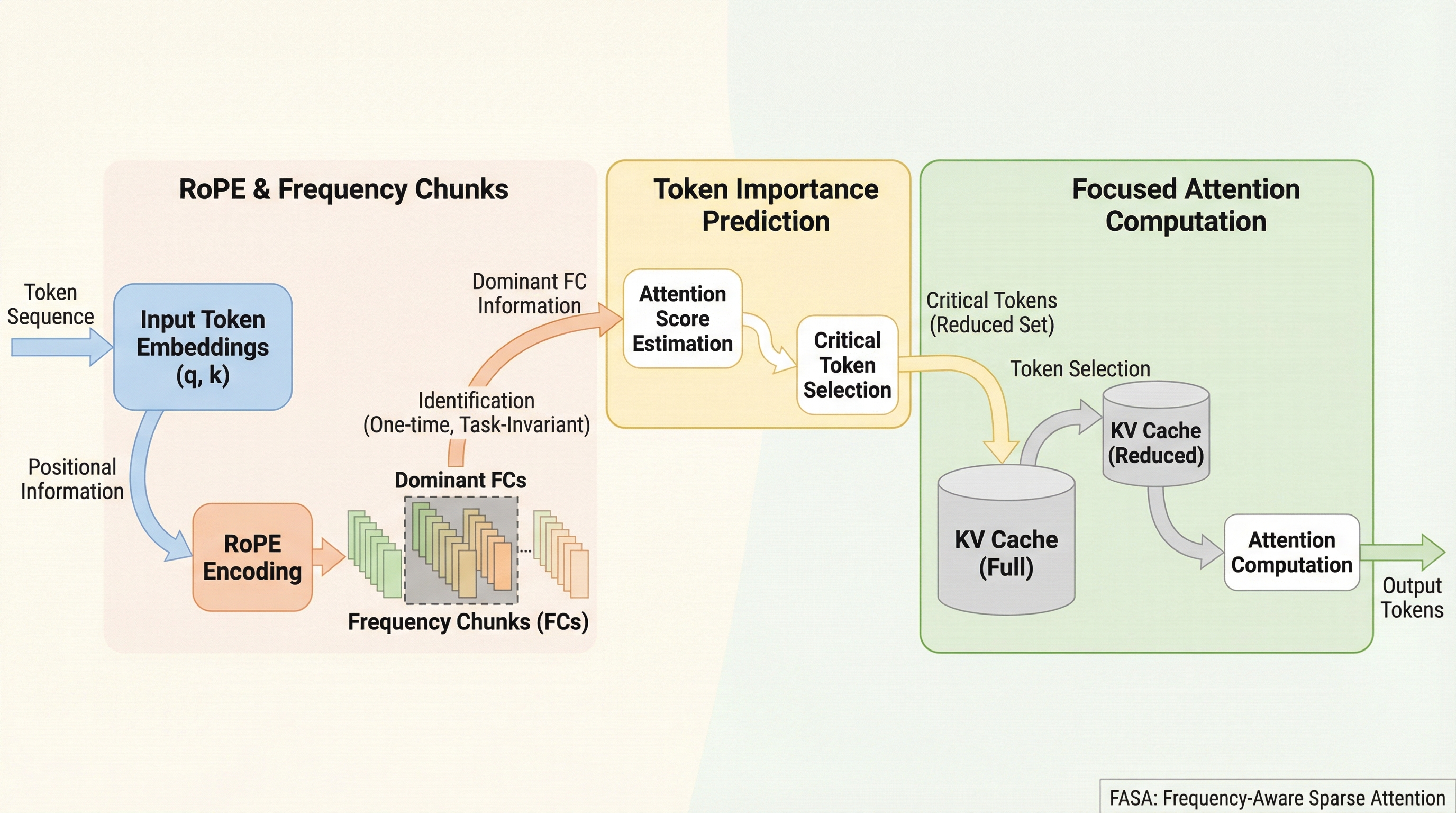
大規模言語モデルの長文処理におけるKVキャッシュのメモリ増大問題を解決するため、RoPE(回転位置エンコーディング)の周波数成分に存在する機能的な疎性を利用し、重要なトークンを動的に予測する学習不要のフレームワーク「FASA」が提案されました。
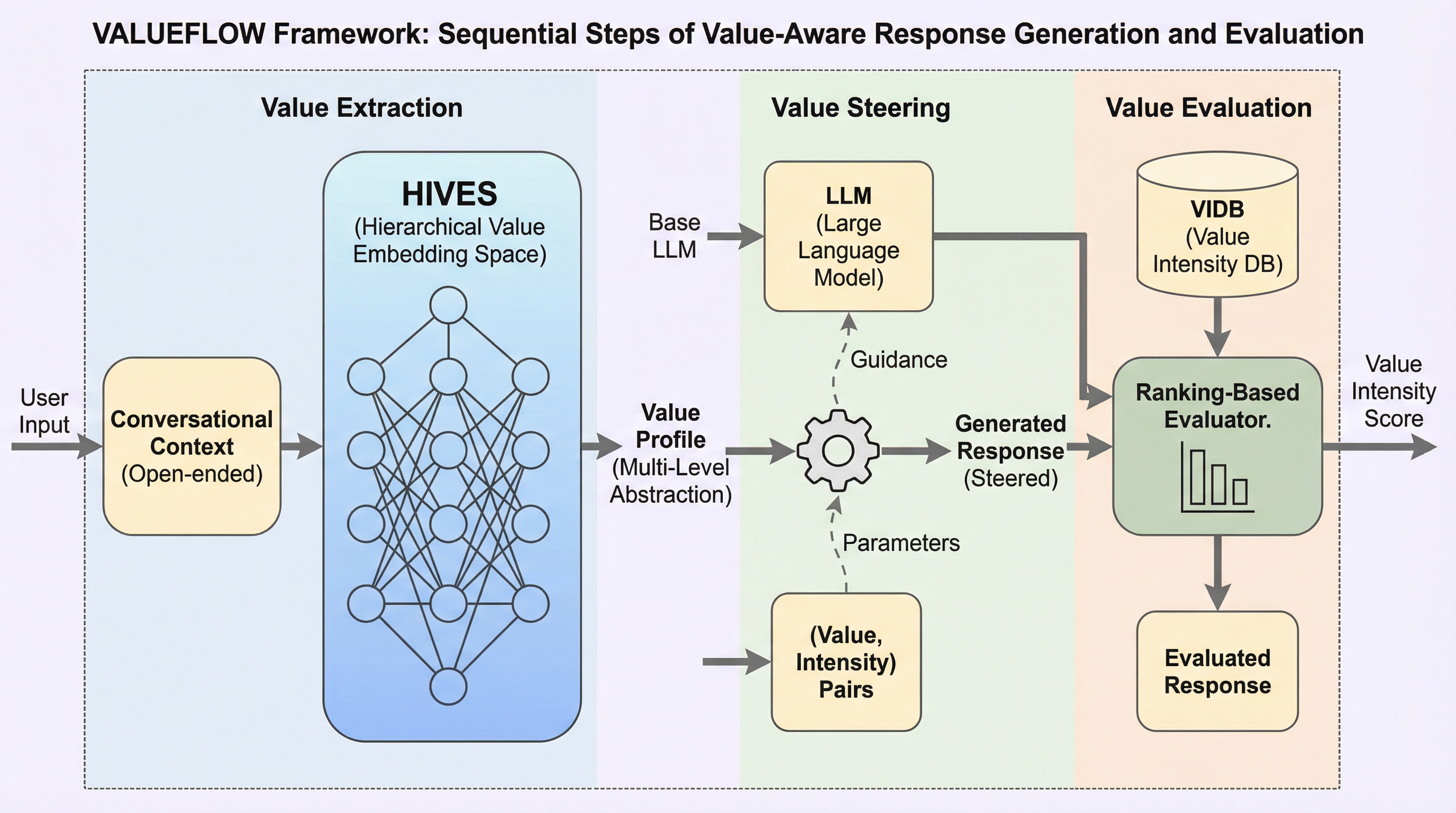
大規模言語モデルを多様な人間の価値観に適合させるため、抽出・評価・制御を統合した初の包括的フレームワークである「VALUEFLOW」が開発され、価値の階層構造を捉える埋め込み空間、大規模な強度データベース、および安定したアンカーベースの評価器が導入されました。
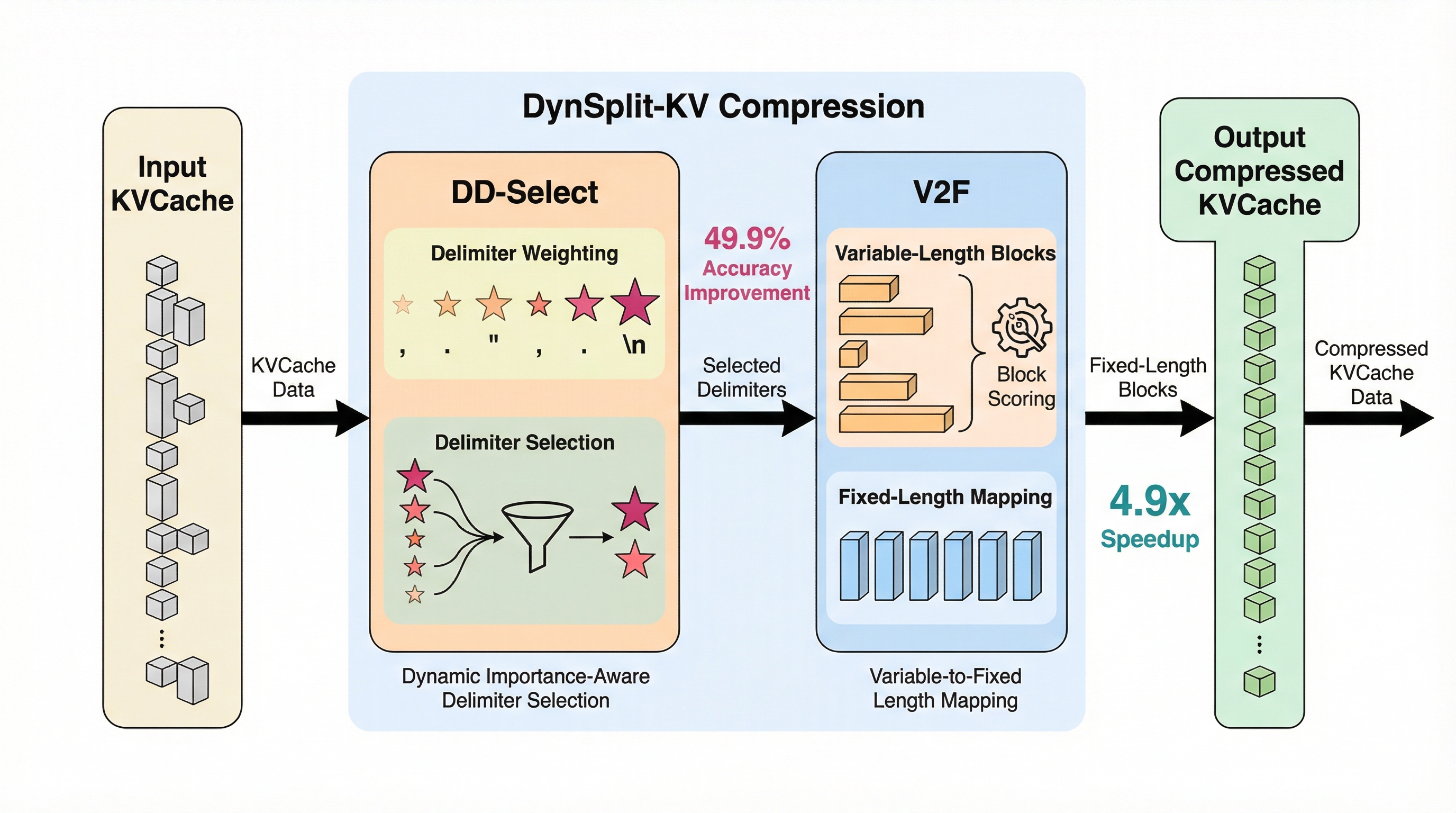
大規模言語モデルの長文推論において、従来の固定長や固定区切り文字によるKVキャッシュ分割は、文脈ごとの意味境界を無視するため最大55.1%もの大幅な精度低下を招くという深刻な課題がありましたが、本研究はこれを解決する動的分割手法を提案しました。
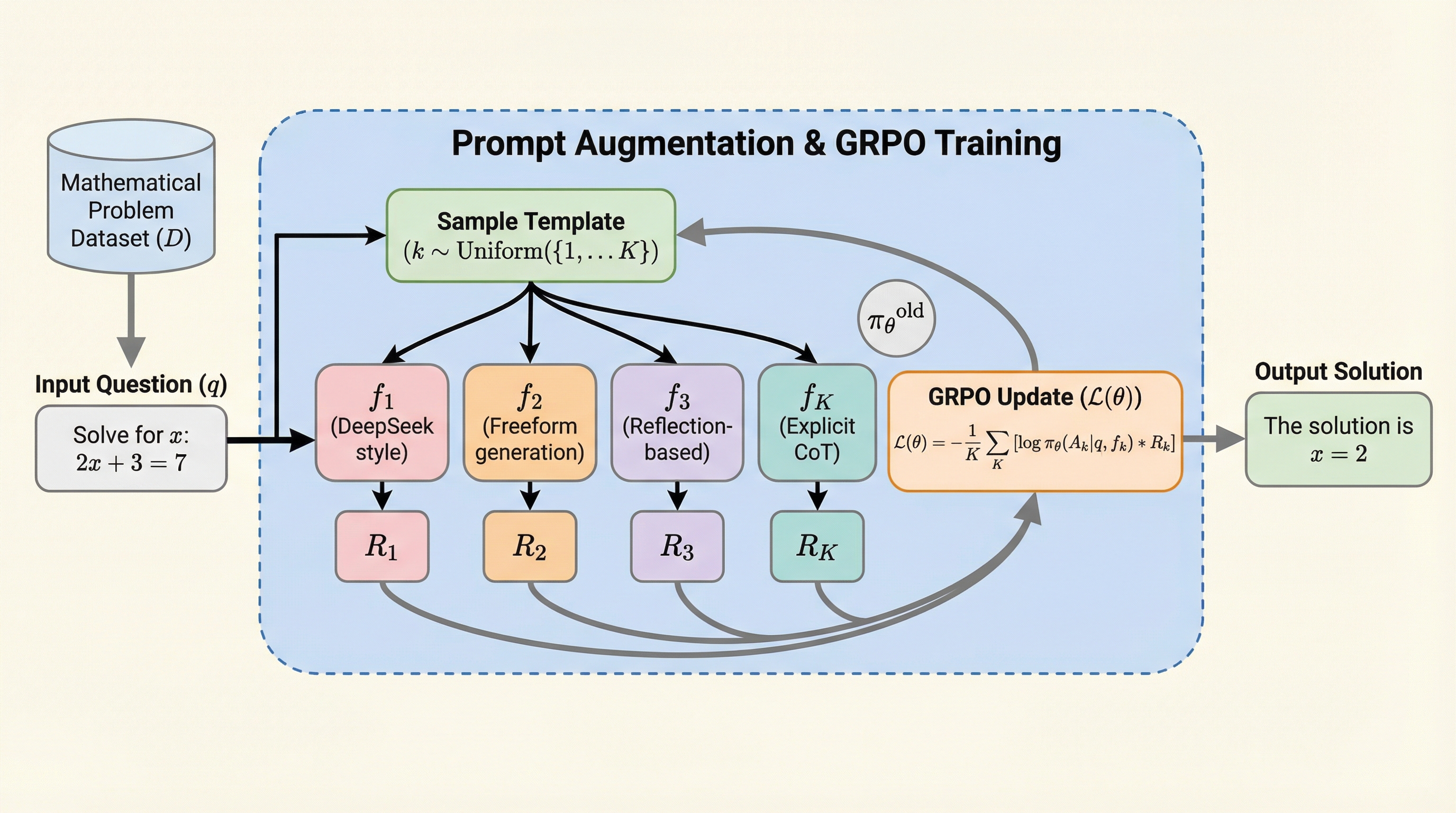
大規模言語モデルの数学的推論能力を向上させる強化学習において、従来はエントロピー崩壊による不安定性が原因で、学習が5〜20エポック程度の短期間に制限されるという課題がありました。本研究が提案する「プロンプト拡張」は、複数の推論テンプレートとフォーマット報酬を組み合わせることで、単一の学習実行内で多様な推論の振る舞いを引き出し、エントロピー崩壊を抑制することに成功しました。この手法により、Qwen2.5-Math-1.5Bモデルにおいて最大50エポックの安定した長期学習が可能となり、主要な数学ベンチマークで従来手法を上回る最高水準の精度を達成しました。具体的には、多様なテンプレートを用いることで低エントロピー状態でも学習を継続できる安定性を確保し、計算コストを抑えつつモデルの推論能力を最大限に引き出す新しいトレーニングパラダイムを提示しています。
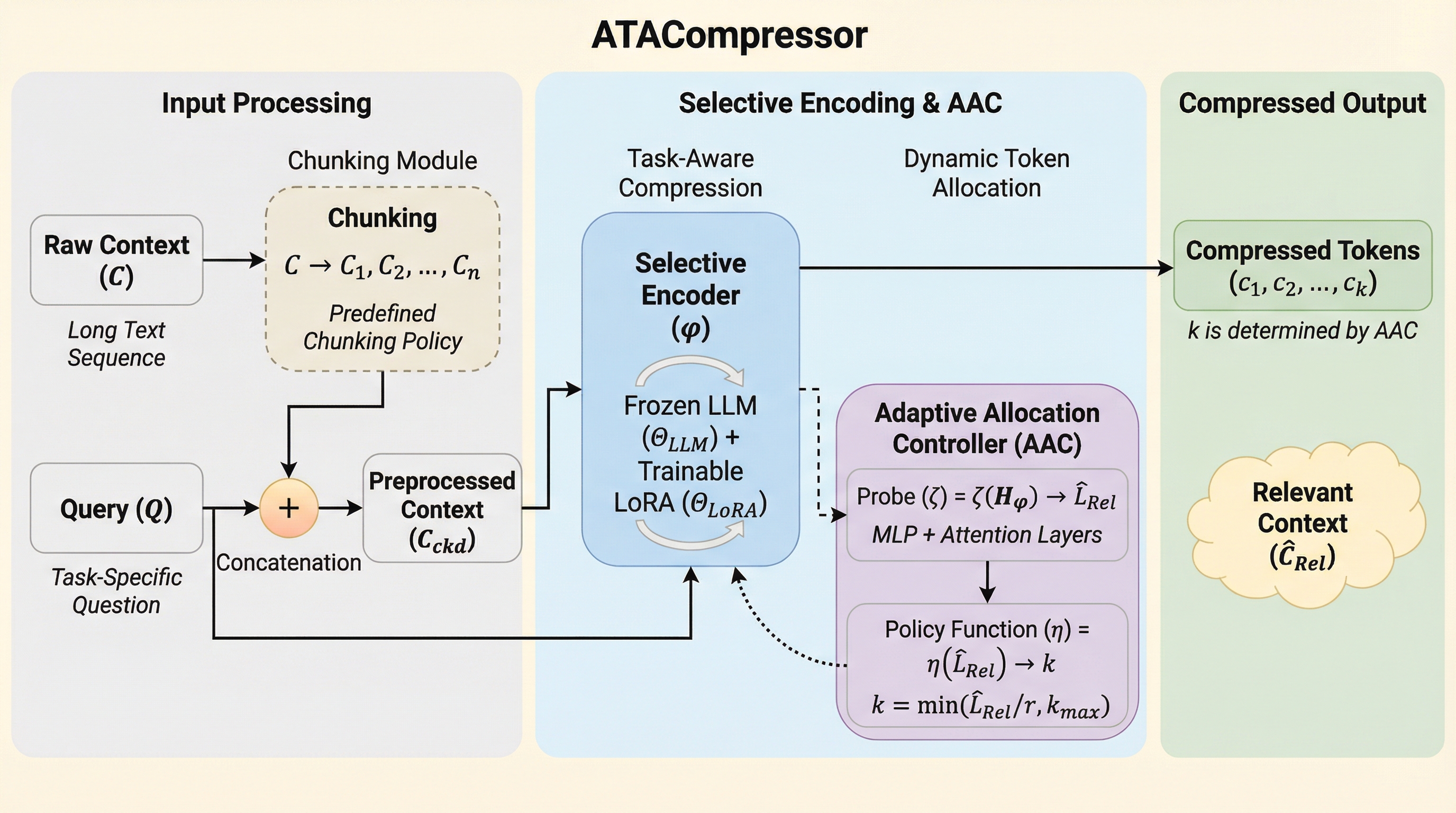
ATACompressorは、大規模言語モデル(LLM)が長大な入力文を処理する際に、重要な情報が埋もれてしまう「情報の埋没(lost in the middle)」問題を解決するために開発された、革新的な適応型コンテキスト圧縮技術である。
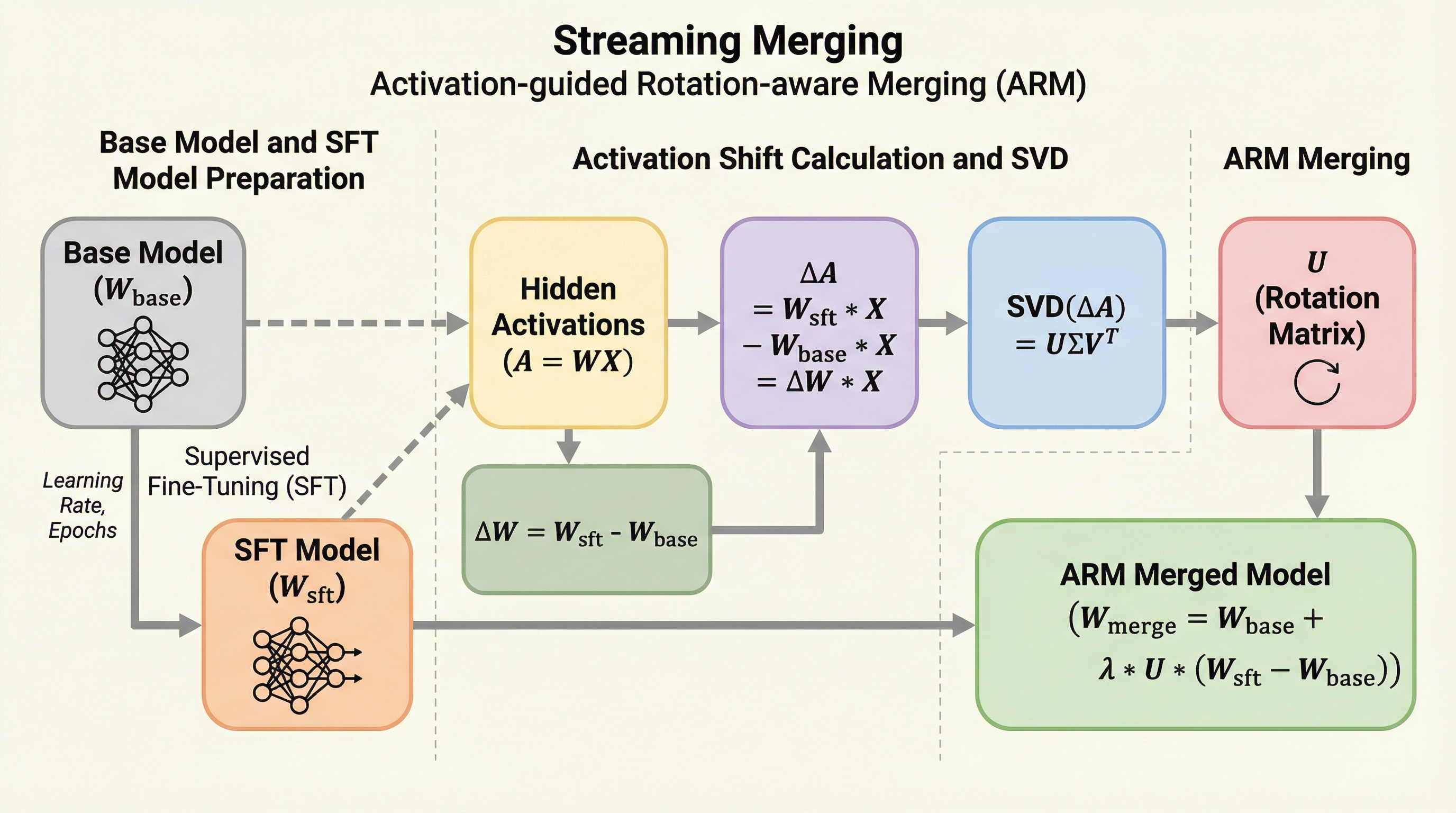
大規模言語モデルの効率的な適応手法として、モデルマージを単なる事後処理ではなく、反復的な最適化プロセスとして再定義する「ストリーミング・マージ」という新しい枠組みが提案されました。 中核技術である「ARM(アクティベーション誘導回転認識マージ)」は、モデル内部の活動差分から回転行列を導出し、従来の線形補間では到達不可能だった幾何学的な性能限界を突破して勾配降下法の動態を近似します。 実験では、学習初期のチェックポイントのみを用いたマージによって、完全に収束した教師あり微調整(SFT)モデルの性能を上回るという、計算効率と高精度を両立した画期的な結果が示されました。
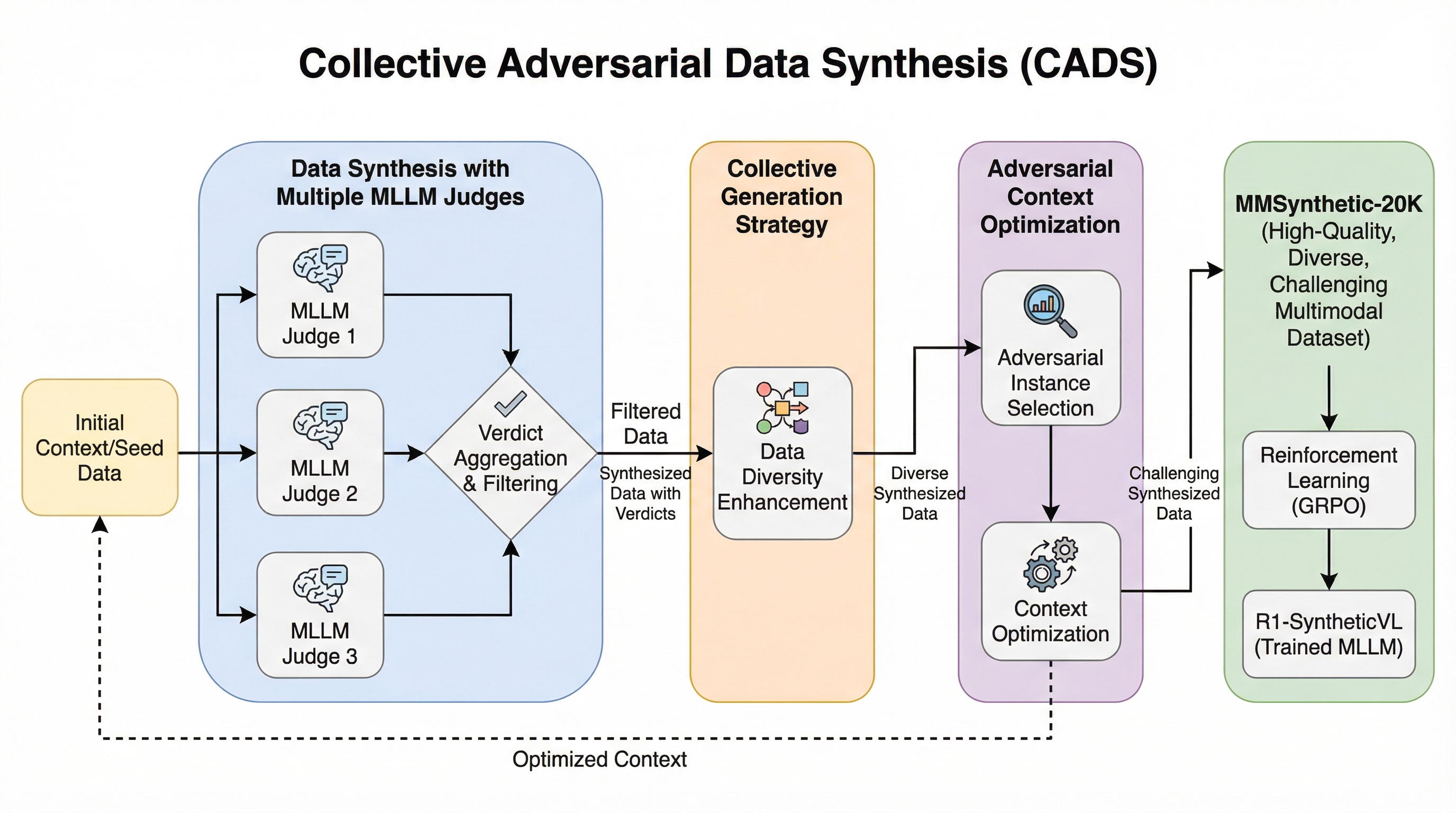
マルチモーダル大規模言語モデル(MLLM)の進化において、高品質な学習データの不足とアノテーションコストの増大が深刻な課題となっており、特に複雑な推論を必要とする実世界のタスクに対応するための思考の連鎖(CoT)を含むデータの入手は極めて困難です。