OMAR:多人数・多ターンの自己対話強化学習による会話型社会的知能の獲得
OMAR(One Model, All Roles)は、単一の言語モデルが会話内の全参加者を同時に演じ、多人数かつ多ターンの自己対話を通じて社会的知能を自律的に学習する新しい強化学習フレームワークである。
TL;DR(結論)
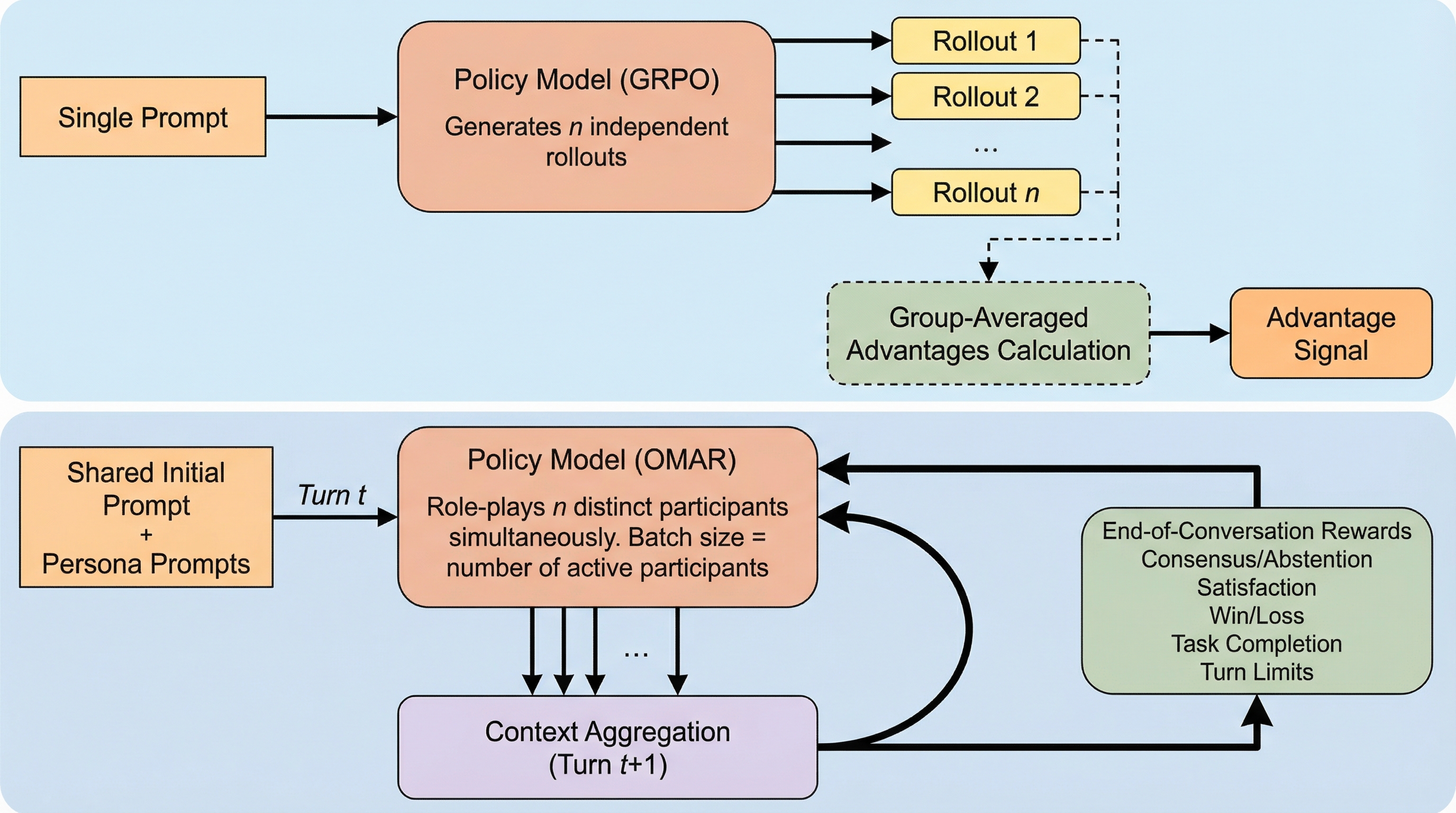
OMAR(One Model, All Roles)は、単一の言語モデルが会話内の全参加者を同時に演じ、多人数かつ多ターンの自己対話を通じて社会的知能を自律的に学習する新しい強化学習フレームワークである。 従来の静的な学習や単一ターンの最適化とは異なり、長期的な目標達成や複雑な社会規範の獲得を目的としており、ターン単位とトークン単位の利得を段階的に推定する階層的アドバンテージ推定によって、長い対話における学習の安定化を実現している。 SOTOPIA環境や人狼ゲームを用いた検証の結果、人間による直接的な監視や模範データがない状態でも、共感の表明、説得、妥協案の提示、相互利益の追求といった高度で微細な社会的行動がモデルから自発的に創発されることが確認された。
なぜこの問題か
人工知能は現在、受動的な支援ツールから社会的な参加者へと進化する新しい段階に移行している。次世代のAIシステムには、単なる言語処理や情報検索の能力だけでなく、人間と協力し、チームを調整し、社会的な取り組みに貢献する能力が求められている。このような役割を果たすためには、多様なペルソナや目標を持つ個人または集団と意思疎通を図り、複雑で動的な環境において自己と集団の両方の目的を理解する「社会的知能」が不可欠である。しかし、これまでの学習手法には大きな課題が存在していた。 人間は日々の会話や経験を通じて適応し、社会的知能を育んでいくが、従来の行動クローニング(Behavior Cloning)は本質的に静的な学習であり、固定されたデモンストレーションを模倣することに終始している。また、現在の大規模言語モデルの推論能力を支えている強化学習手法の多くは、検証可能な正解がある単一ターンの最適化を目的として設計されており、多人数が参加する多ターンの動的な対話には適していない。既存の手法では、ターゲットとなる応答を生成することは学習できても、長期的な社会目標を追求しながら動的にやり取りする能力を養うことは困難であった。…
核心:何を提案したのか
本論文では、多人数・多ターンの会話環境において言語モデルを訓練するための汎用的な強化学習フレームワーク「OMAR(One Model, All Roles)」を提案している。このフレームワークの最大の特徴は、その名称が示す通り、単一のモデルが会話におけるすべての役割を同時に演じる点にある。ユーザーは参加者の役割(ペルソナ)と目標、会話の終了条件、そしてエピソード終了時の報酬を定義するだけでよい。トレーニングが始まると、モデルは自分自身の異なるバージョンや異なる役割と対話を行い、最終的な報酬を最大化するための戦略と社会的知能を自律的に発達させていく。 OMARは、マルチエージェント間の相互作用を単一モデルによるシミュレーションへと変換することで、システムの複雑さを大幅に軽減している。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related