FASA:周波数を考慮したスパースアテンション
大規模言語モデルの長文処理におけるKVキャッシュのメモリ増大問題を解決するため、RoPE(回転位置エンコーディング)の周波数成分に存在する機能的な疎性を利用し、重要なトークンを動的に予測する学習不要のフレームワーク「FASA」が提案されました。
TL;DR(結論)
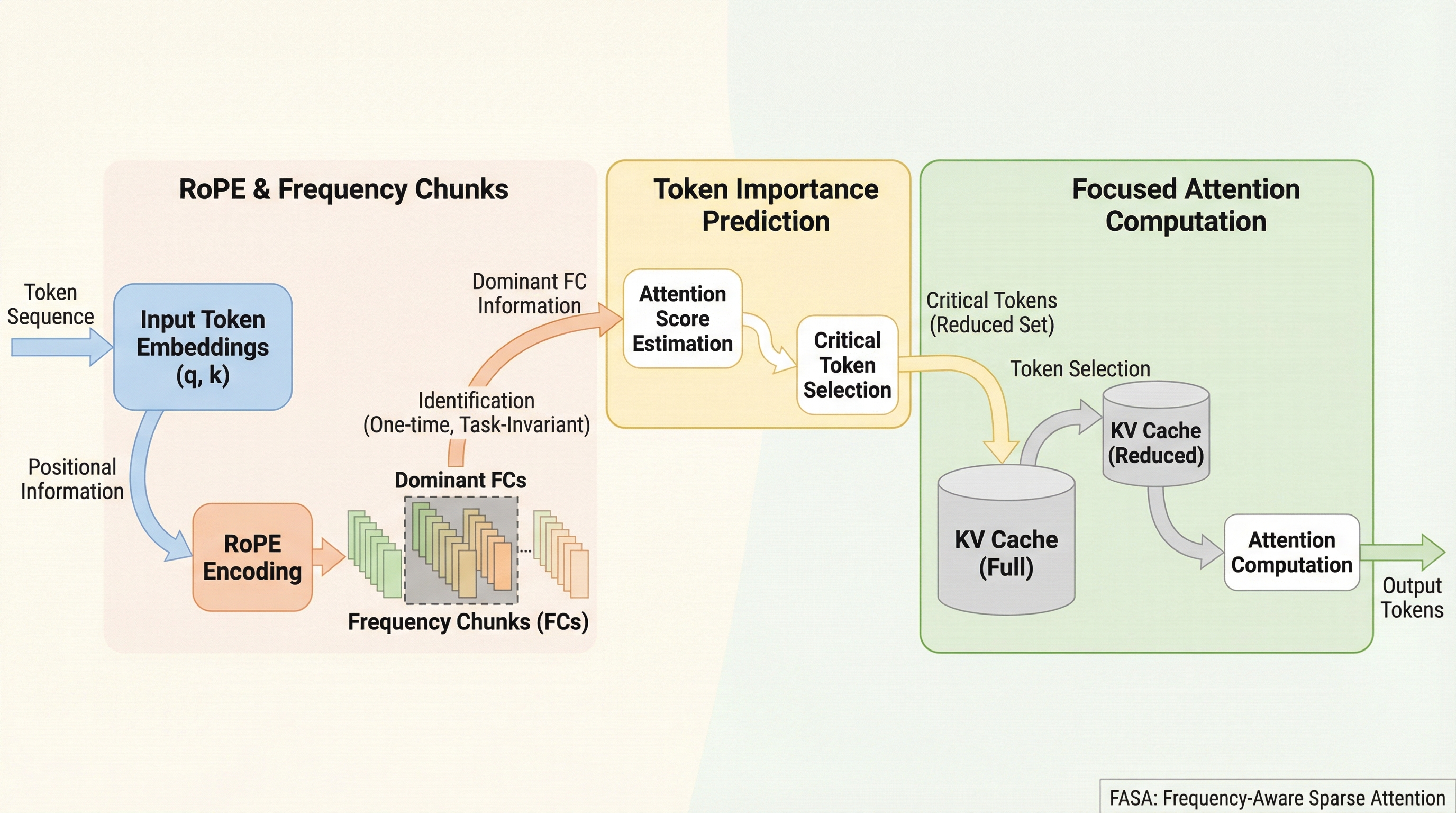
大規模言語モデルの長文処理におけるKVキャッシュのメモリ増大問題を解決するため、RoPE(回転位置エンコーディング)の周波数成分に存在する機能的な疎性を利用し、重要なトークンを動的に予測する学習不要のフレームワーク「FASA」が提案されました。 この手法は、少数の支配的な周波数成分のみを用いてクエリに応じたトークンの重要度を低コストで推定し、選別された重要なトークンに対してのみフル次元のアテンション計算を行うことで、精度の低下を最小限に抑えつつ計算効率とメモリ効率を劇的に向上させます。 実験では、わずか256トークンの保持でフルキャッシュと同等の性能を達成し、特定のタスクで2.56倍の高速化や8倍のメモリ圧縮を実現するなど、既存のトークン削除手法を凌駕する高い堅牢性と汎用性が実証されました。
なぜこの問題か
大規模言語モデル(LLM)の急速な進歩に伴い、リポジトリレベルのコード解析や長大な文書の要約、複雑な思考の連鎖を必要とするタスクなど、非常に長いコンテキストを扱う需要がかつてないほど高まっています。しかし、入力シーケンスが長くなるにつれて、Key-Value(KV)キャッシュのメモリ占有量が線形に増加し、これがモデルのデプロイと実用化における決定的なボトルネックとなっています。特に、各トークンの生成時には過去の全KVキャッシュにアクセスする必要があるため、メモリI/Oのレイテンシが増大し、高性能なGPUの計算資源を十分に活用できず、全体的なスループットが著しく制限されるという深刻な課題があります。実際に、32Kトークンのコンテキストでは、デコーディング段階が全レイテンシの90%を占めることが確認されており、このメモリ帯域幅の制約をいかに克服するかが鍵となります。 この課題を解決するために、不要なトークンを削除するトークン・エビクションという手法が盛んに研究されてきましたが、既存のアプローチにはそれぞれ重大な欠点が存在します。…
核心:何を提案したのか
本研究では、追加学習を必要とせず、高い粒度でクエリに応じたトークンの重要度を予測する革新的なフレームワークであるFASA(Frequency-Aware Sparse Attention)を提案しています。この提案の核心は、RoPE(Rotary Positional Encodings)における異なる回転周波数が、アテンションの機能的な疎性を引き起こしているという独自の発見にあります。RoPEの各次元は特定の回転周波数を持っており、これを「周波数チャンク(FC)」として捉え直すと、モデルの文脈理解において支配的な役割を果たす特定のFCがごく少数存在することが明らかになりました。具体的には、RoPEの周波数成分は機能的に二分されます。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related