エージェントの失敗予測の精度は必ずしも効果的な失敗防止を意味しない
LLMエージェントの失敗を事前に検知する批判モデルは、たとえAUROC 0.94という極めて高い予測精度を持っていても、実際の運用時に介入を行うとエージェントの思考プロセスを破壊し、性能を大幅に低下させるリスクがあることが判明しました。
TL;DR(結論)
LLMエージェントの失敗を事前に検知する批判モデルは、たとえAUROC 0.94という極めて高い予測精度を持っていても、実際の運用時に介入を行うとエージェントの思考プロセスを破壊し、性能を大幅に低下させるリスクがあることが判明しました。 研究チームは、介入による「失敗からの回復率」と「成功軌道の中断率」のトレードオフを数式化し、ベースラインの失敗率が特定のしきい値を超えない限り、介入はむしろ有害であるという「介入のパラドックス」を理論と実験の両面から明らかにしました。 成功率が高いタスクでは最大26ポイントの性能低下が見られた一方、失敗が常態化しているタスクでは改善が確認されており、介入の是非は予測精度ではなく、エージェントが修正をどれだけ柔軟に受け入れられるかという特性に依存するという結論に至りました。
なぜこの問題か
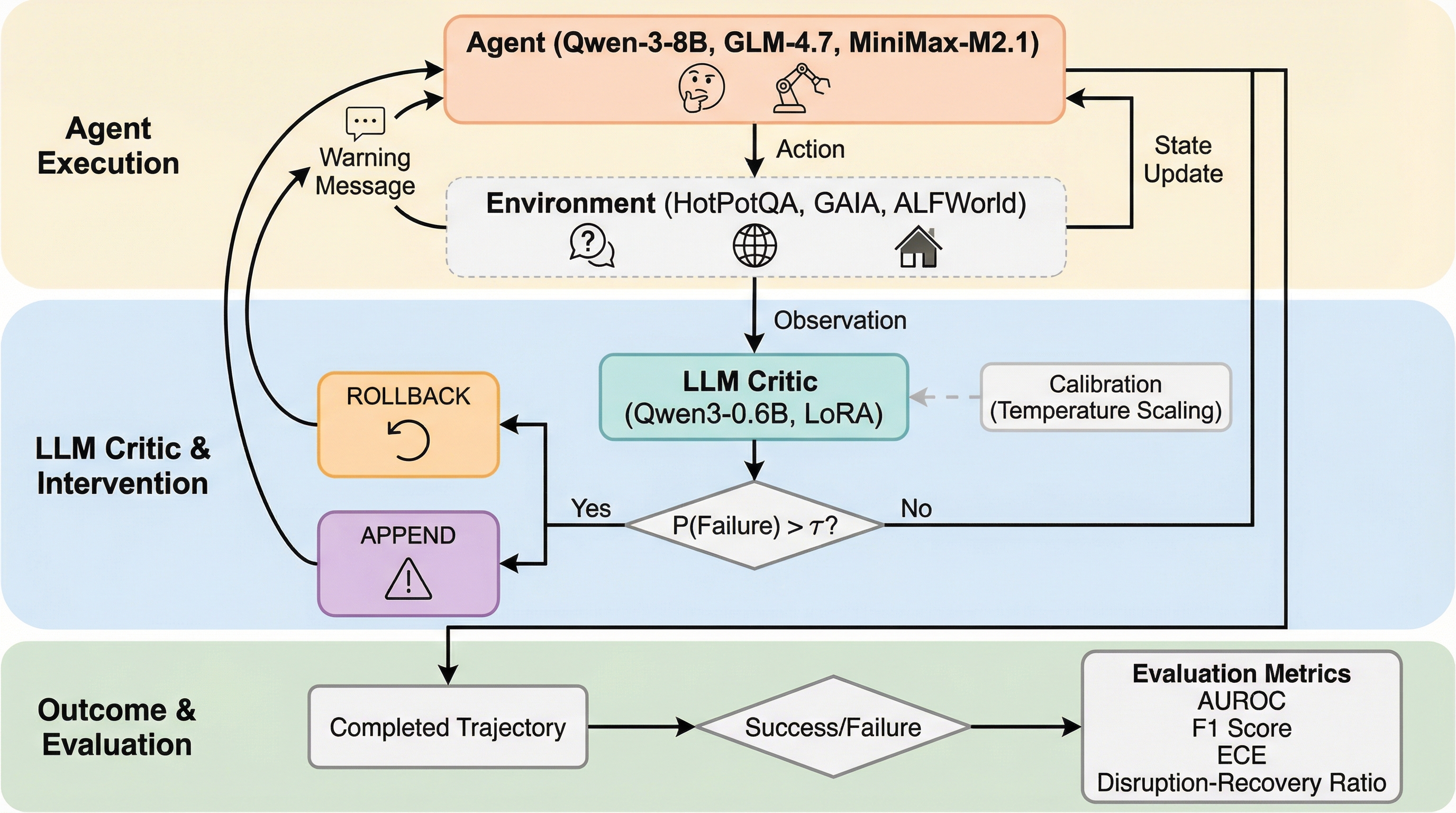
大規模言語モデル(LLM)をベースとしたエージェントは、複数のステップを伴う複雑なタスクを実行するために広く導入されています。しかし、これらのエージェントが途中で失敗すると、計算リソースの無駄遣いや誤った出力の生成、さらにはユーザー体験の著しい低下を招くことになります。このような失敗を未然に防ぐための一般的な戦略として、実行中に「批判モデル(LLM critic)」がエージェントの動きを監視し、失敗の兆候を検知した時点で介入を行い、正しい方向へ軌道修正させるという手法が提案されてきました。直感的には、失敗を正確に予測できれば、それに基づいた介入は常に有益であると考えられがちです。しかし、実際のエージェント運用時における介入の効果については、これまで十分に理解されていませんでした。 本研究では、この「介入は常に善である」という直感に疑問を投げかけています。特に、予測モデルが非常に高い精度で失敗を言い当てることができたとしても、その後の介入プロセスがエージェントの思考プロセスを破壊し、本来成功するはずだったタスクまで失敗させてしまうリスクがあることに着目しています。…
核心:何を提案したのか
本研究の核心は、介入の効果を「回復(Recovery)」と「中断(Disruption)」のトレードオフとして定式化したことにあります。研究チームは、エージェント単体(ベースライン)と、エージェントに批判モデルを加えたシステム(介入あり)の実行結果を比較するために、2×2の出力テーブルを定義しました。このテーブルでは、ベースラインが失敗して介入によって成功したケースを「回復(C)」、ベースラインが成功していたのに介入によって失敗したケースを「中断(B)」としてカウントします。これに基づき、ベースラインの失敗率(p)、回復率(r)、中断率(d)という3つの指標を導入しました。 成功率の変化(ΔSuccess)は、「p × r - (1 - p) × d」という数式で表されます。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related