R1-SyntheticVL:生成モデルによる合成データはマルチモーダル大規模言語モデルへの準備ができているか?
マルチモーダル大規模言語モデル(MLLM)の進化において、高品質な学習データの不足とアノテーションコストの増大が深刻な課題となっており、特に複雑な推論を必要とする実世界のタスクに対応するための思考の連鎖(CoT)を含むデータの入手は極めて困難です。
TL;DR(結論)
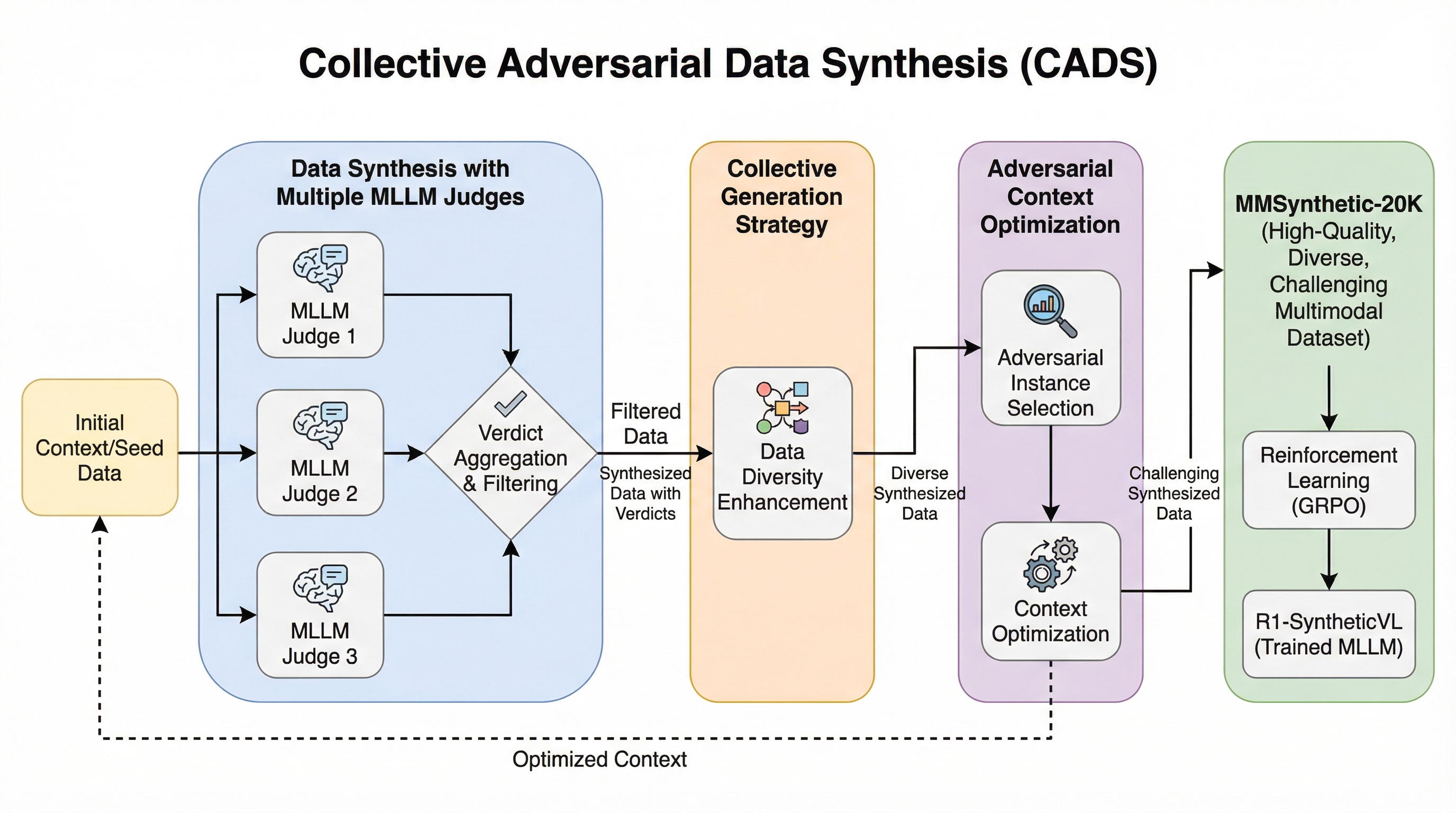
マルチモーダル大規模言語モデル(MLLM)の進化において、高品質な学習データの不足とアノテーションコストの増大が深刻な課題となっており、特に複雑な推論を必要とする実世界のタスクに対応するための思考の連鎖(CoT)を含むデータの入手は極めて困難です。 本研究では、複数のモデルの知能を統合する集合知と敵対的学習を組み合わせ、高品質で多様かつ挑戦的なデータを自律的に合成する新手法「Collective Adversarial Data Synthesis(CADS)」を提案し、データの質、多様性、難易度の問題を同時に解決しました。 この手法で構築した2万件のデータセット「MMSynthetic-20K」を用いて強化学習を行ったモデル「R1-SyntheticVL」は、MathVistaなどの主要なベンチマークで既存手法を上回る優れた性能を示し、合成データがMLLMの能力向上に有効であることを証明しました。
なぜこの問題か
マルチモーダル大規模言語モデル(MLLM)は、画像とテキストを統合して理解し推論する能力において目覚ましい進歩を遂げてきましたが、その成功は大規模かつ高品質な学習データに強く依存しています。しかし、現在AIの学習に利用可能なデータは枯渇しつつあるという指摘があり、特に医療や安全性が重視される特定のドメインにおけるデータは本質的に希少で入手が困難です。たとえ生のデータが手に入ったとしても、複雑な実世界のタスクに対応するための思考の連鎖(Chain-of-Thought)を含むような高度なアノテーションを付与するには、膨大な時間と費用が必要となります。データ合成はこうした制約を緩和する有望な代替案として注目されており、言語モデルの分野では自己指示などの手法が成功を収めていますが、マルチモーダル分野ではテキストと厳密に整合した高品質な視覚コンテンツを生成することが長年の課題でした。…
核心:何を提案したのか
本研究では、複雑な実世界のタスクを解決するために、マルチモーダル学習データを自律的に合成する新しい汎用的なアプローチ「Collective Adversarial Data Synthesis(CADS)」を提案しました。CADSの核心的なアイデアは、複数のモデルの知能を結集する「集合知」を活用して高品質かつ多様な生成を保証しつつ、「敵対的学習」の概念を取り入れることでモデルの能力向上に効果的な挑戦的なサンプルを合成することにあります。この手法は、単一のモデルが持つバイアスや限界を克服するために、複数のマルチモーダル大規模言語モデルが共同でデータを生成するフェーズと、それらのモデルが判定者となって生成物の品質を評価するフェーズの二つの循環的なプロセスで構成されています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related