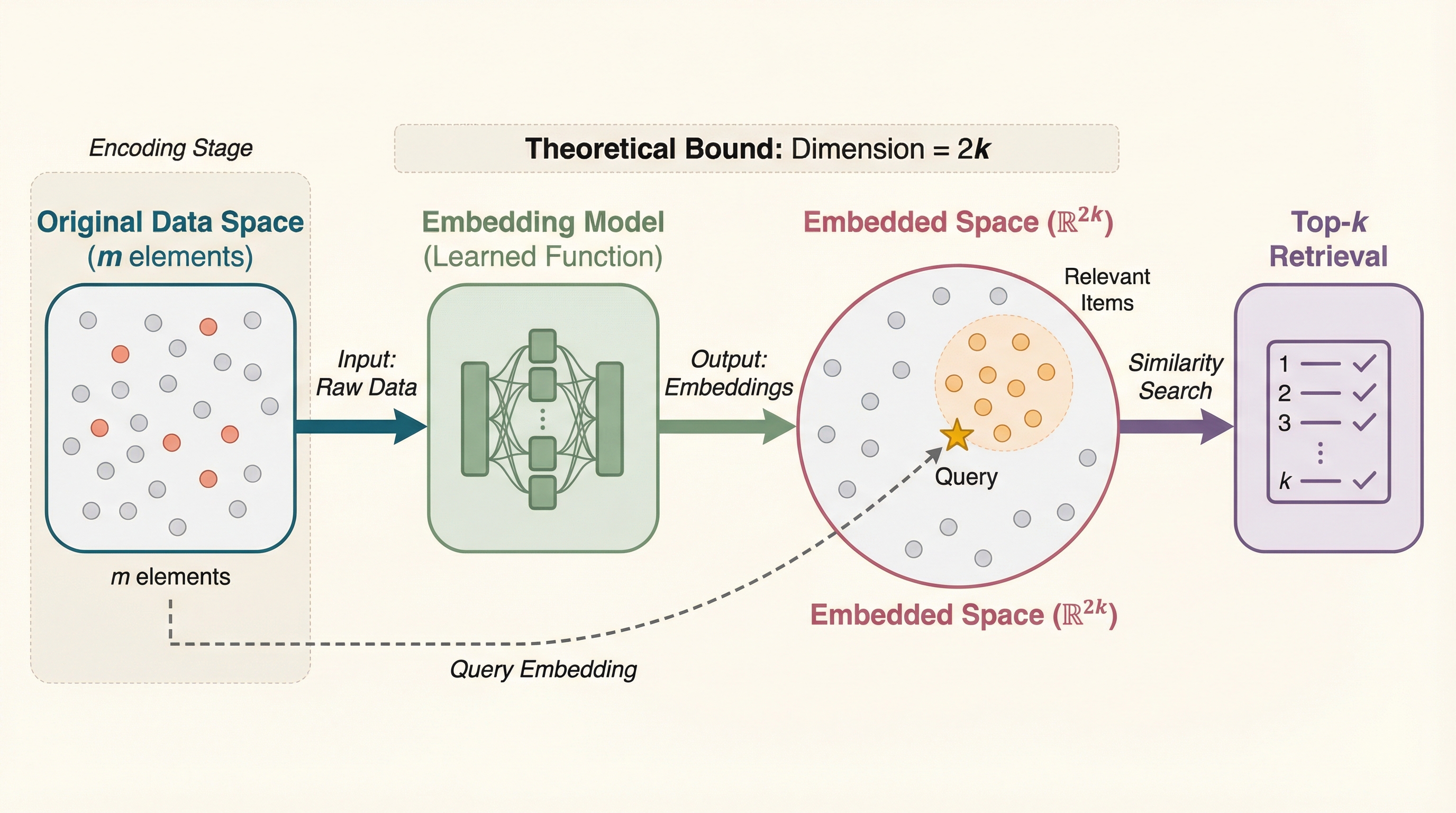
$\mathbb{R}^{2k}$ is Theoretically Large Enough for Embedding-based Top-$k$ Retrieval
本研究は、要素数mの集合から最大k個の要素を検索するために必要な最小埋め込み次元(MED)を理論的に解明し、内積やコサイン類似度、ユークリッド距離といった主要な指標において、理論上は要素数mに依存せず2k次元あれば十分であることを数学的に証明した。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
本研究は、要素数mの集合から最大k個の要素を検索するために必要な最小埋め込み次元(MED)を理論的に解明し、内積やコサイン類似度、ユークリッド距離といった主要な指標において、理論上は要素数mに依存せず2k次元あれば十分であることを数学的に証明した。
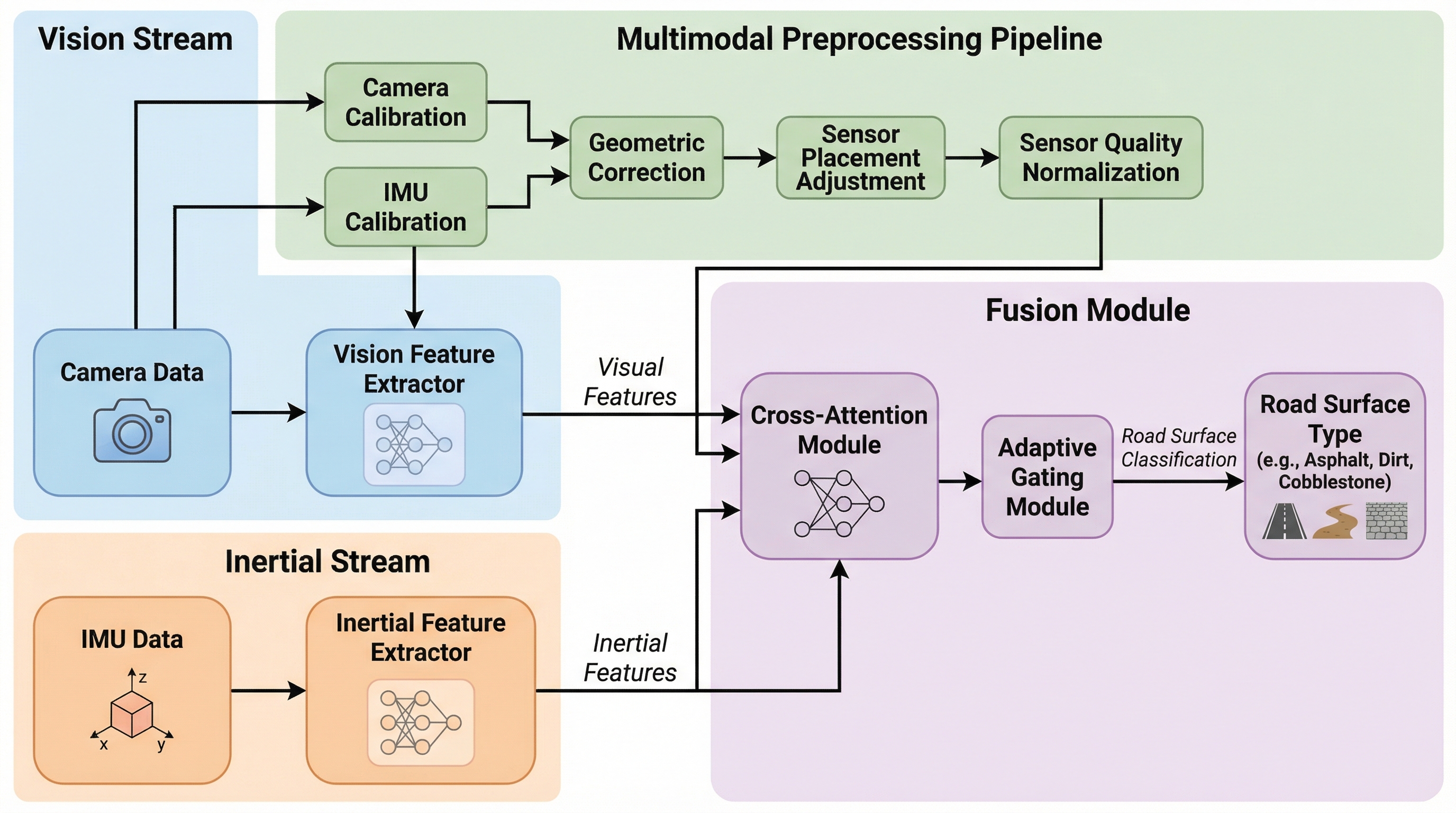
本研究は、カメラ画像と慣性計測装置(IMU)のデータを統合し、軽量な双方向クロスアテンションと適応型ゲーティング層を用いることで、夜間や豪雨、激しい砂埃といった過酷な環境下でも路面を正確に分類する新しいマルチモーダルフレームワークを提案しています。
本研究では、表形式データの生成において変分オートエンコーダ(VAE)のどの構成要素にTransformerを配置すべきかを、57種類の多様なデータセットを用いて網羅的に調査しました。実験の結果、Transformerを潜在空間やデコーダに配置することで生成データの多様性は向上するものの、元のデータに対する忠実度が低下するという明確なトレードオフの関係が存在することが判明しました。また、デコーダに配置されたTransformerは層正規化の影響により実質的に線形な挙動を示しており、複雑な特徴間相互作用の学習には限定的な寄与しかしていない可能性が示唆されています。
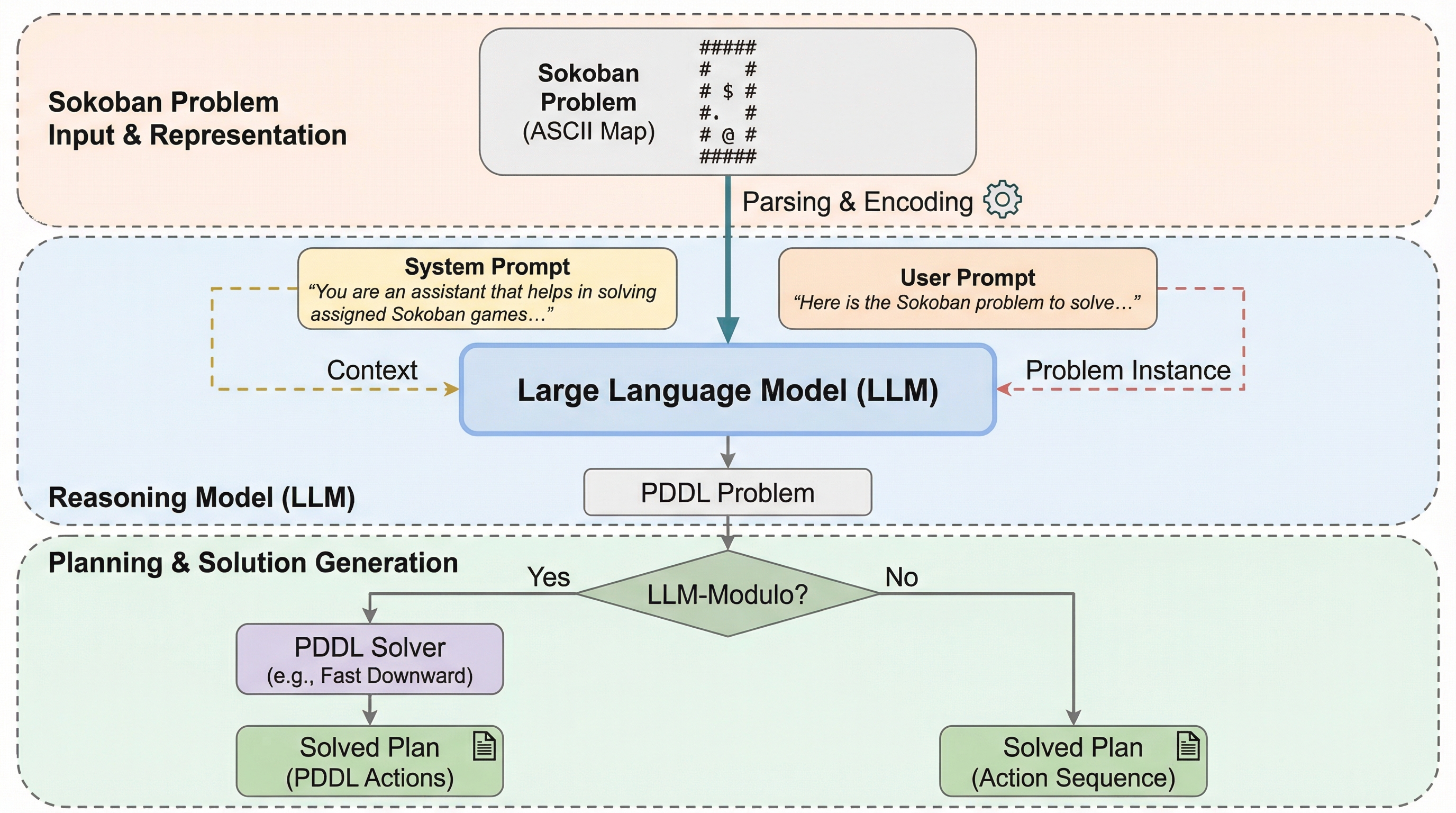
SokoBenchは、大規模言語モデル(LLM)の長期的な計画能力を評価するために、倉庫番パズルを直線的な廊下状のマップに簡略化した新しいベンチマークである。空間的な複雑さを排除し、純粋に手順の長さ(ホライゾン)がモデルの内部的な推論や状態保持に与える影響を測定した結果、解決に25手以上を要する課題では正確性が急激に低下することが判明した。 外部の計画言語(PDDL)ツールを組み合わせるLLM-Modulo手法を導入しても性能向上は限定的であり、モデル内部の空間推論や逐次的な論理構築における根本的な限界が浮き彫りになった。本研究は、現在の推論モデルが単純な記号操作の積み重ねにおいてさえ、長期的な一貫性を維持できないというシステム的な欠陥を明らかにしている。 最新の推論モデルであっても、分岐のない単純な環境においてステップ数が増加するだけで論理的な破綻を来すことが示されており、これはモデル内部での状態保持や計数能力がステップ数の増加に伴って指数関数的に劣化するためである。この結果は、現在のモデルが持つ前方計画の容量には物理的または構造的な限界が存在することを示唆している。
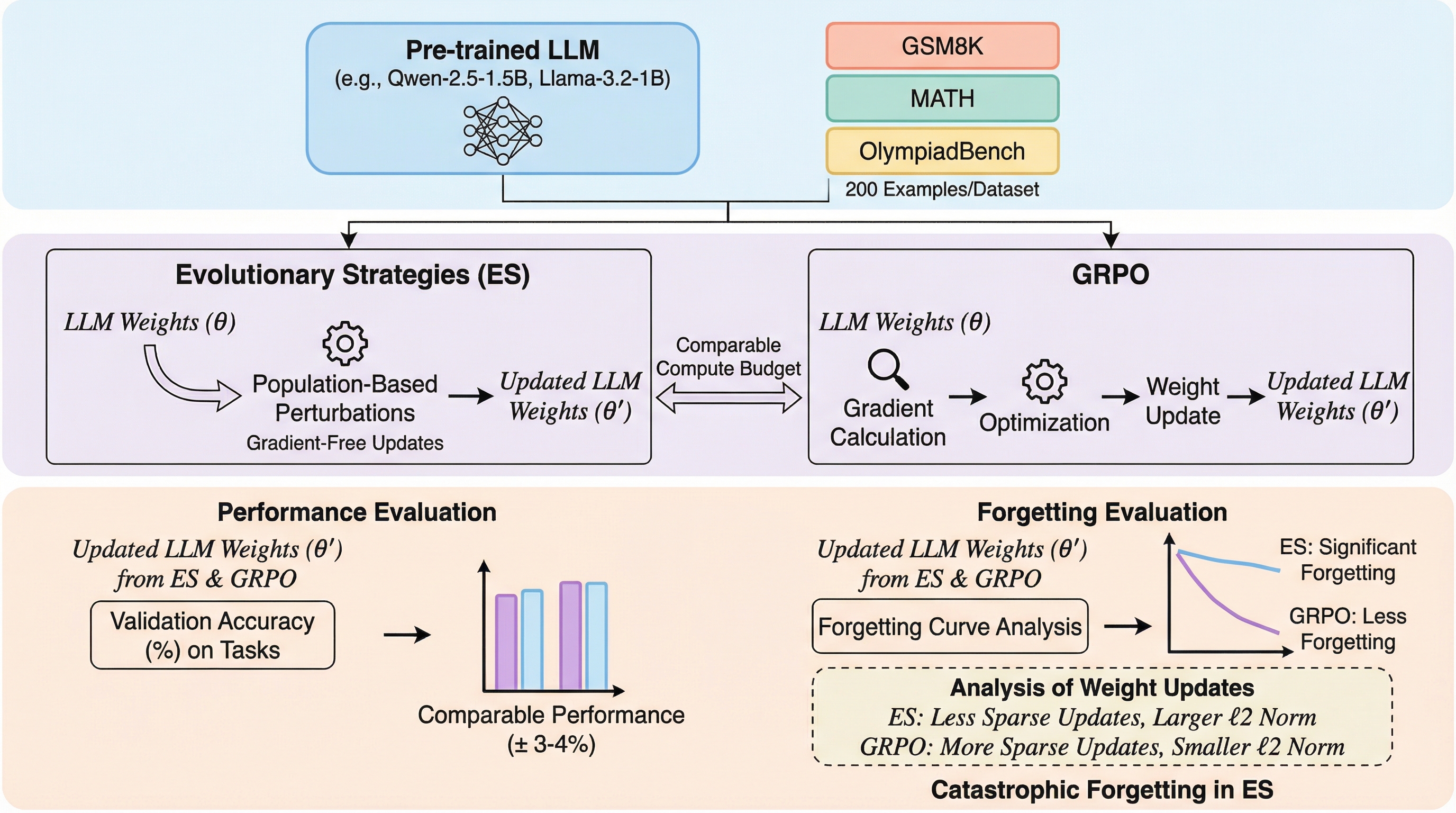
進化戦略(ES)は、従来の勾配ベースの手法であるGRPOと比較して、数学や推論タスクにおいて同等の性能を達成しつつ、メモリ消費を大幅に抑えられる可能性を秘めています。 しかし、本研究の分析により、ESを用いた学習はモデルが既に持っていた既存の知識を急速に失わせる「破滅的忘却」を引き起こし、特定のタスクに特化する一方で汎用性が著しく低下することが判明しました。 この忘却の原因は、ESによるパラメータ更新がGRPOに比べて1000倍も大きなノルムを持ち、かつモデル全体にわたる高密度な変更を加えることで、既存の知識構造を破壊してしまう点にあると結論付けられています。
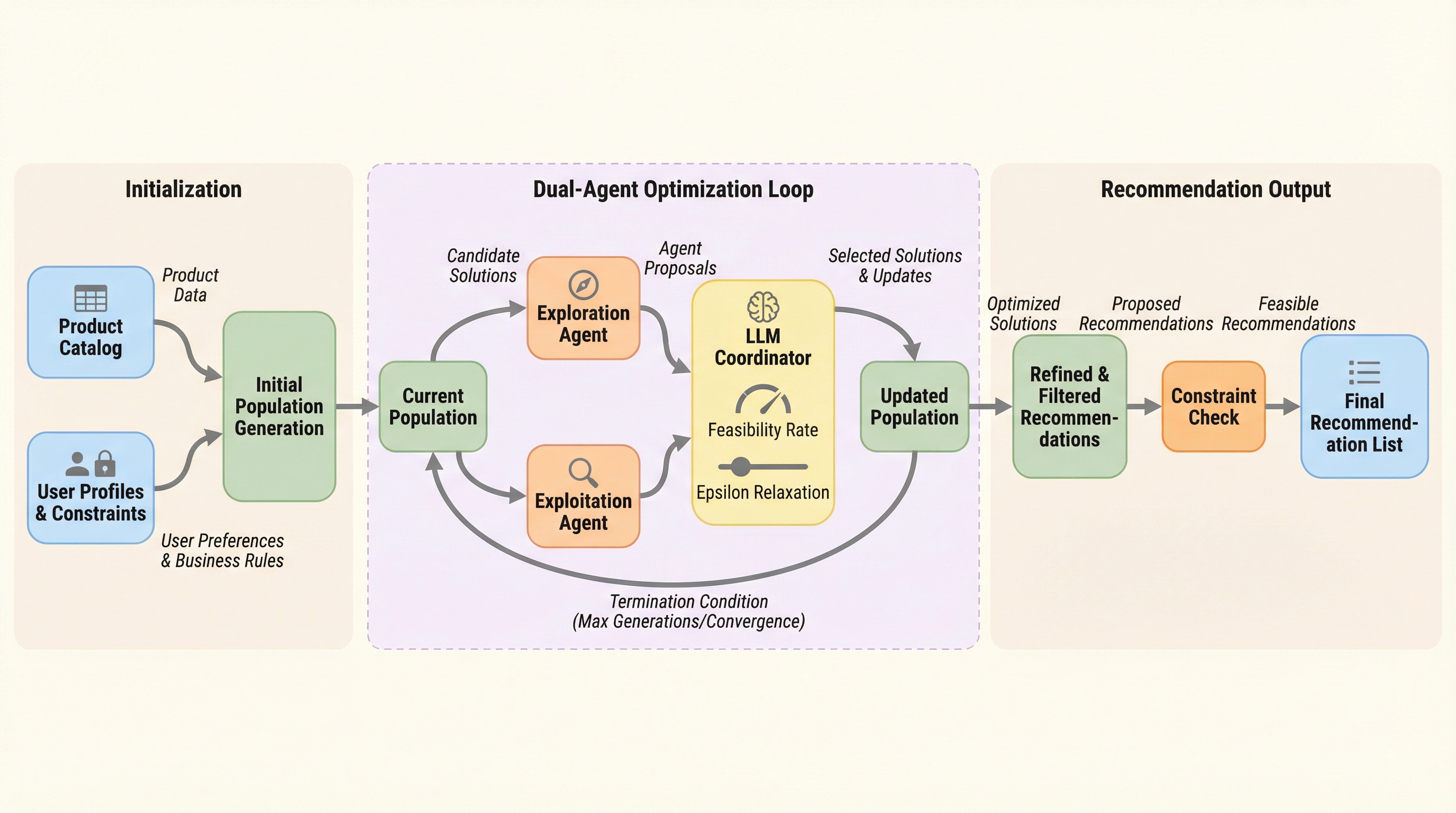
従来の推薦システムは、精度向上とビジネス上の制約(公平性や在庫露出など)の両立を「ソフトな罰則」として扱ってきたため、実運用で制約違反が頻発するという課題を抱えていました。 本研究が提案する「DualAgent-Rec」は、LLMを最適化のオーケストレーター(調整役)として配置し、精度を追求するエージェントと多様性を探索するエージェントを動的に制御する二重構造のフレームワークです。 Amazonのデータセットを用いた実験では、ビジネス制約を100%遵守しながら、既存の手法と比較してパレート・ハイパーボリュームを4〜6%向上させ、実用的な精度と多様性のトレードオフを実現しました。
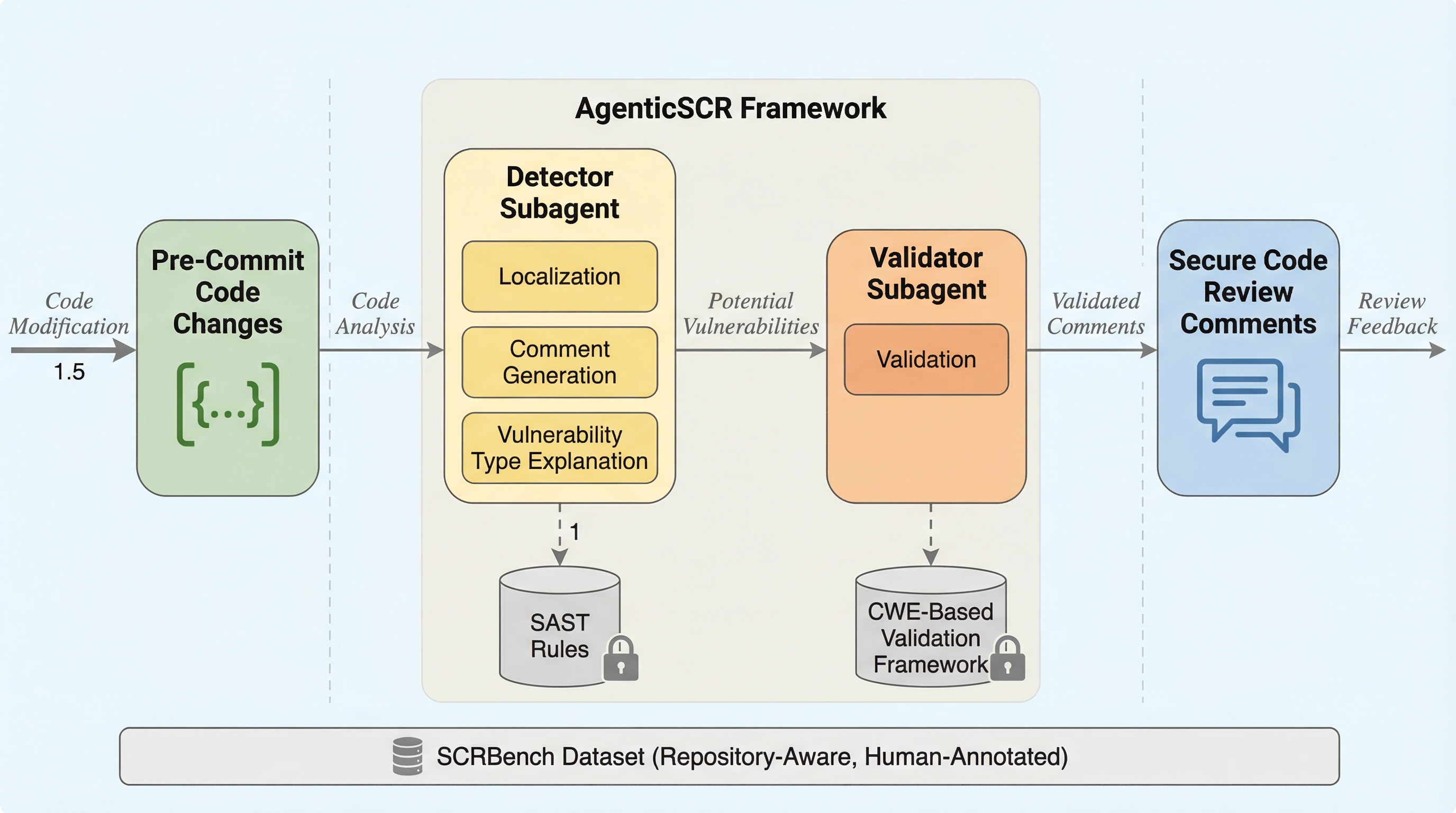
AgenticSCRは、開発者がコードをコミットする前の段階で、不完全かつ文脈に依存する「未成熟な脆弱性」を検出するために設計された、自律的な意思決定とツール呼び出し能力を備えたAIエージェントフレームワークである。
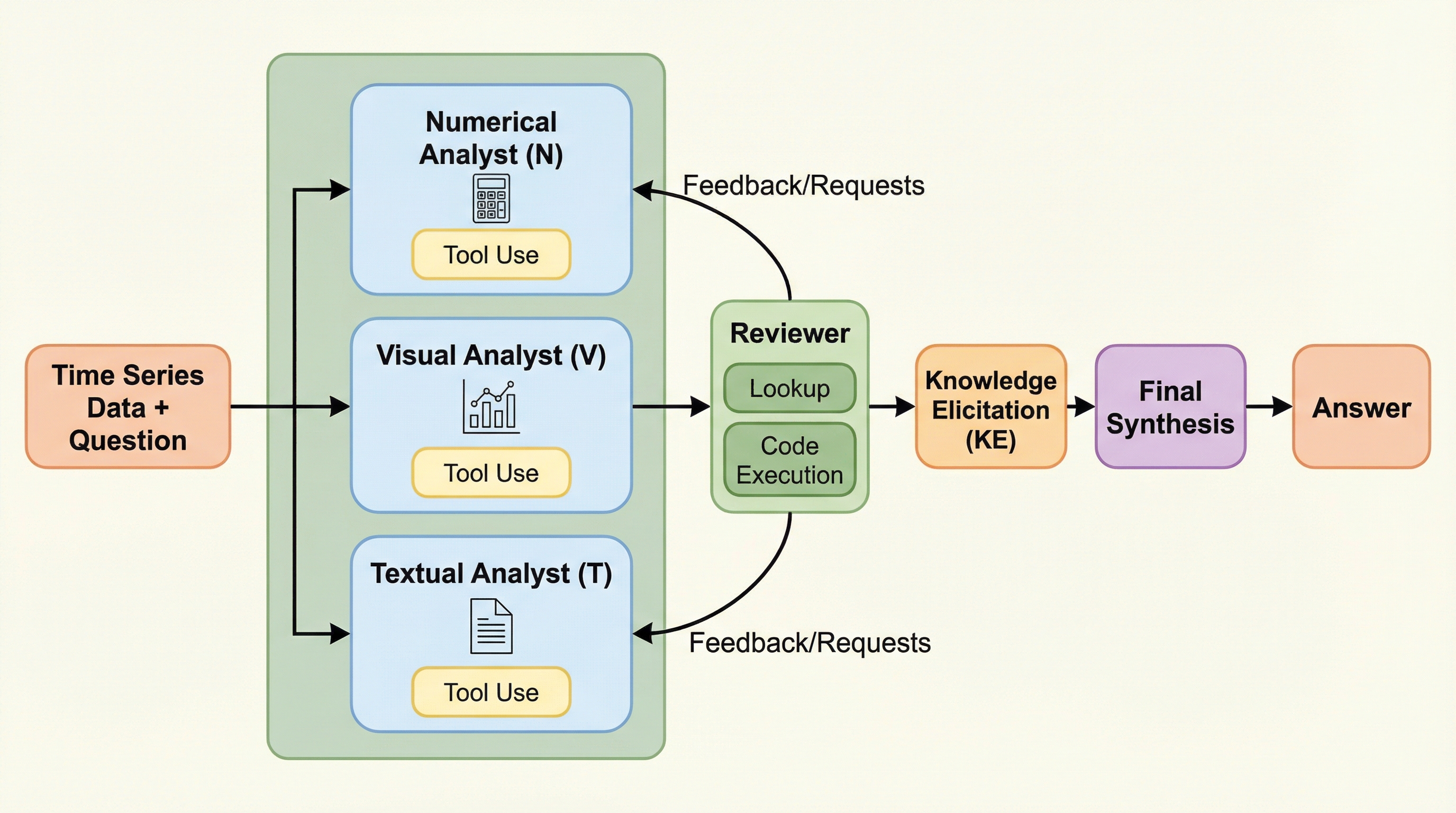
大規模言語モデル(LLM)を用いた時系列データ推論において、数値の正確性の欠如やモダリティ間の干渉、そして体系的な統合の難しさが大きな課題となっている。本研究では、テキスト、視覚、数値の各モダリティに特化した専門エージェントが協調して議論を行う、ゼロショット時系列推論のための新しいフレームワーク「TS-Debate」を提案する。 この手法は、事前にドメイン知識を抽出した上で、各エージェントが独自の視点から観察と推論を行い、その主張をコード実行や数値検索ツールを備えたレビュー担当者が検証する仕組みを持つ。検証・対立・較正(VCC)プロトコルにより、モダリティ間の矛盾を明示的に解消し、数値的なハルシネーションを抑制しながら、信頼性の高い回答を導き出す。 3つの公開ベンチマークに含まれる20のタスクで評価を行った結果、既存の強力なベースラインと比較して大幅な性能向上を達成し、特に時系列データの構造理解と数値的忠実度の両立において優れた成果を示した。タスク固有の微調整を必要とせず、推論時の構造化された対話のみで、複雑な時系列推論を堅牢に実行できることが実証された。
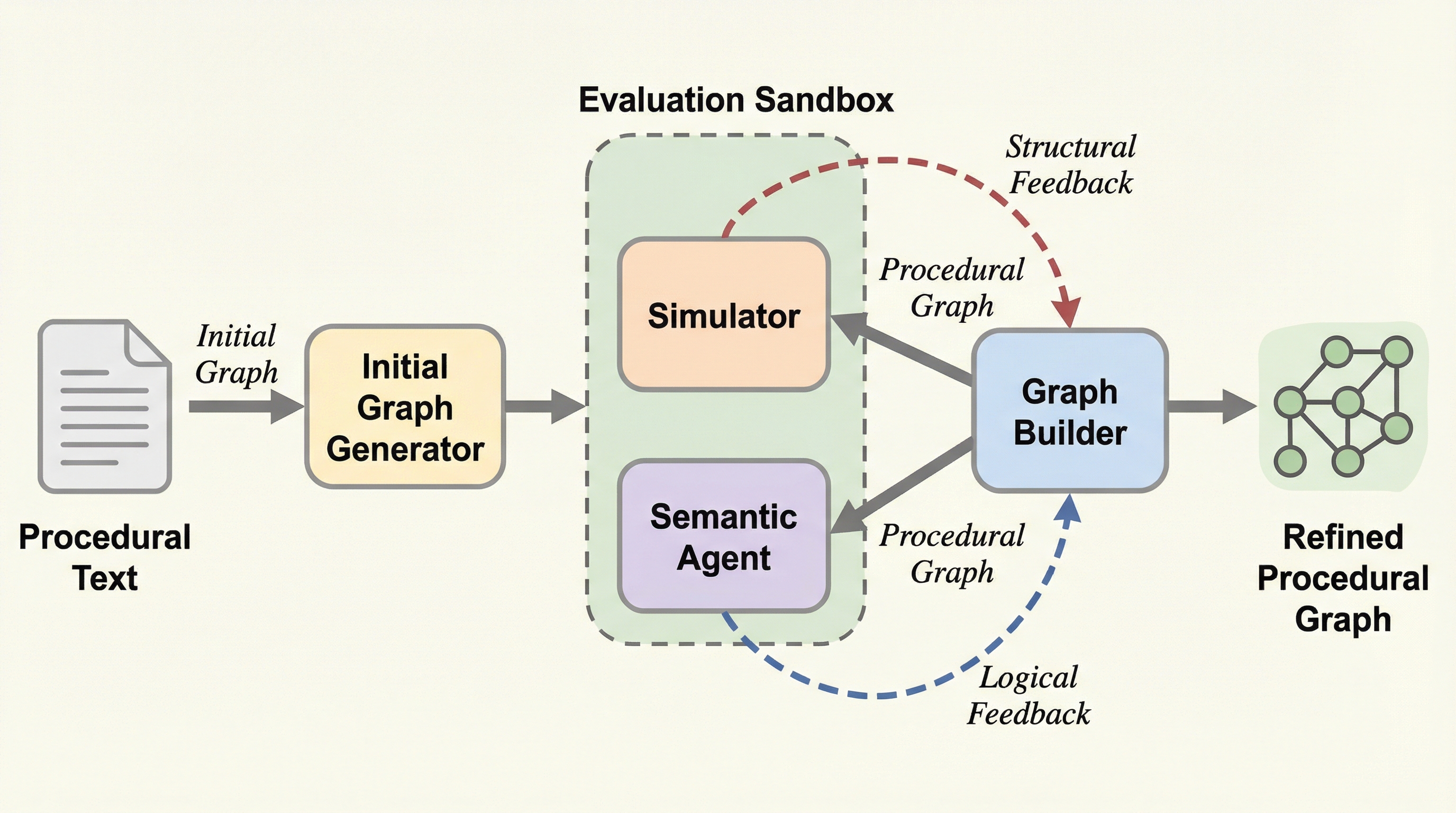
自然言語からワークフローを抽出する際、従来の大型言語モデルでは構造的な不備や論理的な誤解が生じやすいという課題に対し、本研究ではグラフ構築、構造シミュレーション、論理整合性確認の3段階を繰り返すマルチエージェントフレームワーク「text2flow」を提案しました。
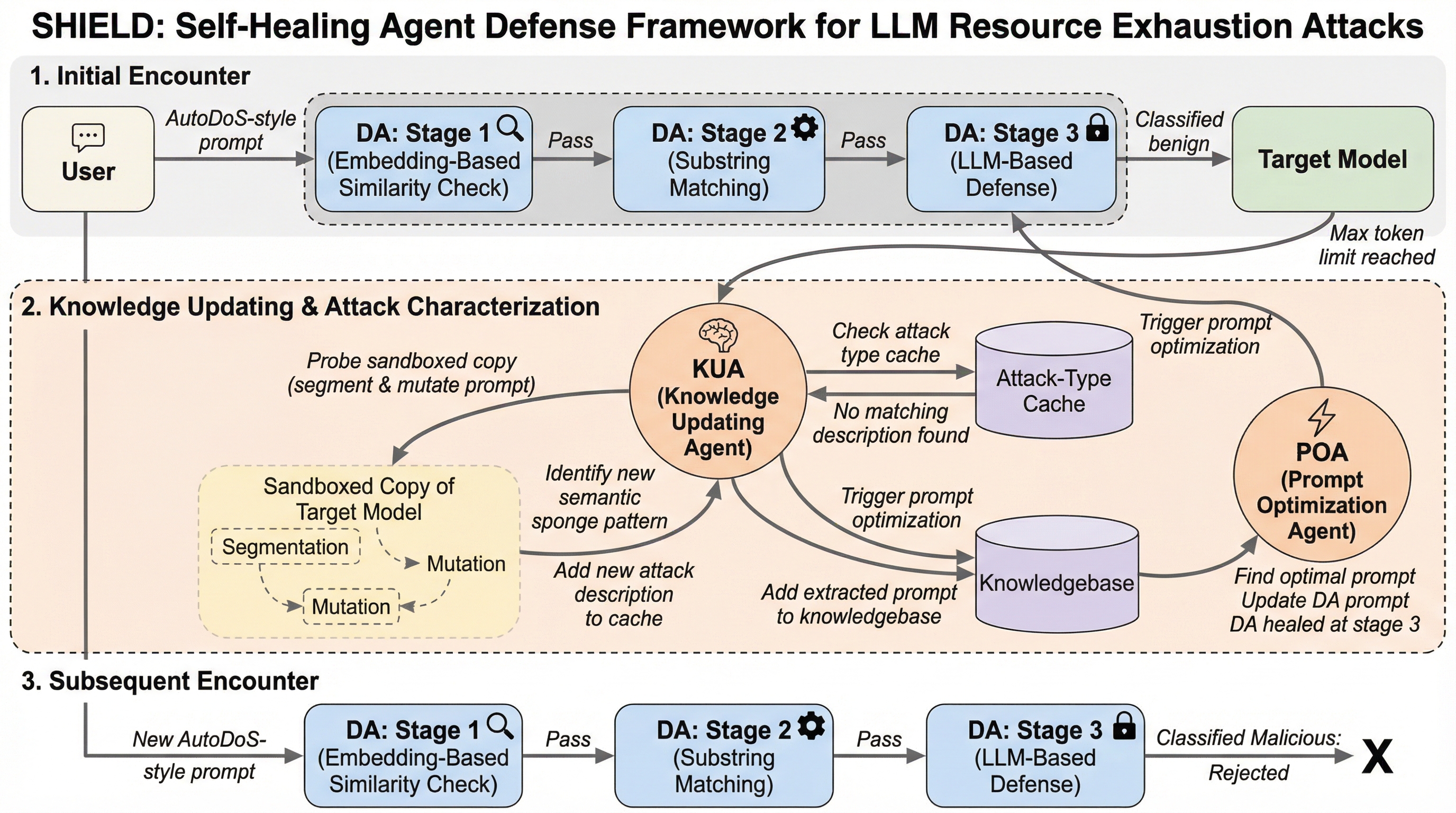
大規模言語モデル(LLM)の計算リソースを過剰に消費させ、サービス停止(DoS)を引き起こす「スポンジ攻撃」に対し、3段階の防御パイプラインと自己修復機能を備えたマルチエージェントフレームワーク「SHIELD」が提案されました。