進化戦略はLLMにおける破滅的忘却を引き起こす
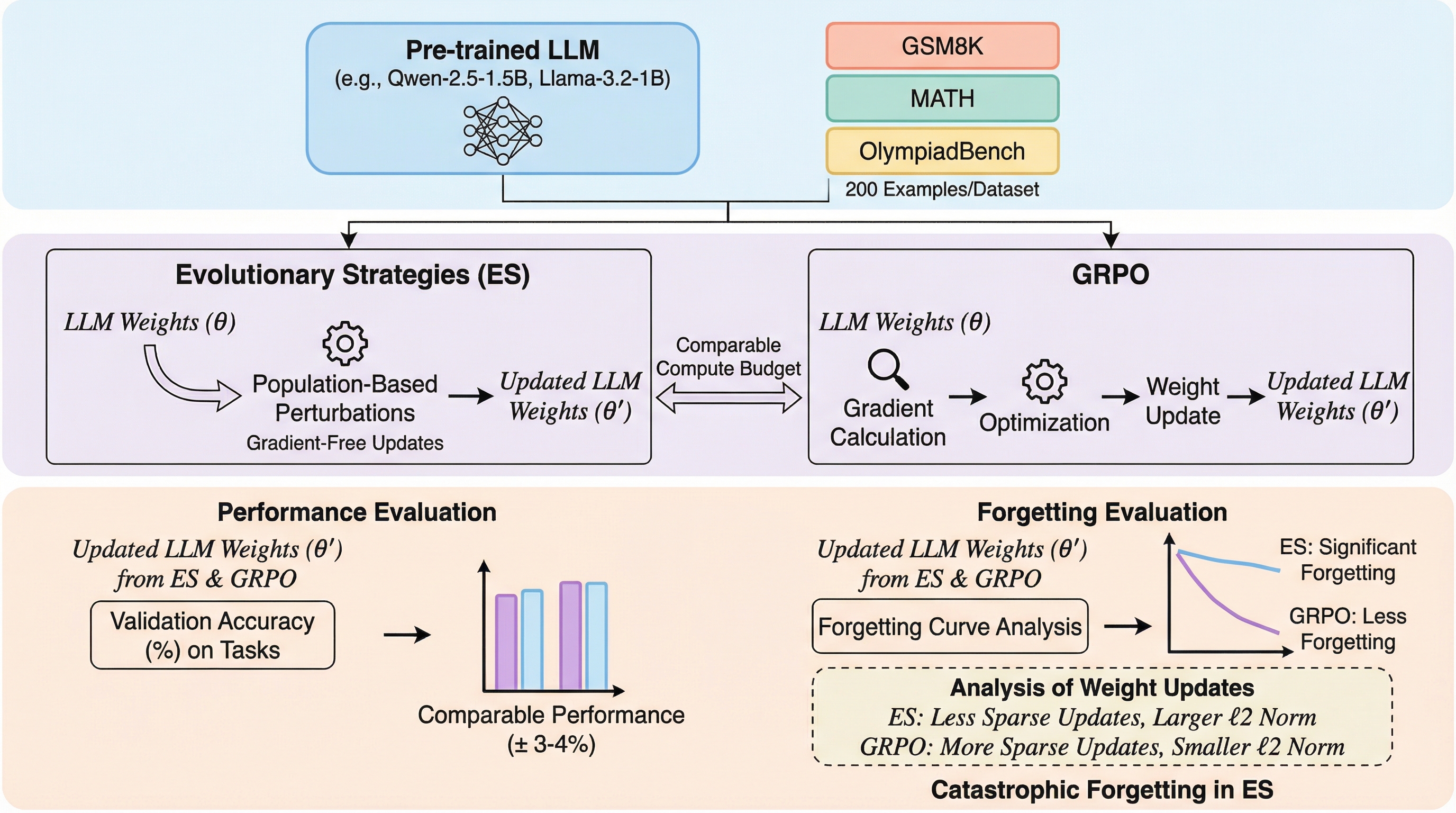
進化戦略(ES)は、従来の勾配ベースの手法であるGRPOと比較して、数学や推論タスクにおいて同等の性能を達成しつつ、メモリ消費を大幅に抑えられる可能性を秘めています。 しかし、本研究の分析により、ESを用いた学習はモデルが既に持っていた既存の知識を急速に失わせる「破滅的忘却」を引き起こし、特定のタスクに特化する一方で汎用性が著しく低下することが判明しました。 この忘却の原因は、ESによるパラメータ更新がGRPOに比べて1000倍も大きなノルムを持ち、かつモデル全体にわたる高密度な変更を加えることで、既存の知識構造を破壊してしまう点にあると結論付けられています。
TL;DR(結論)
進化戦略(ES)は、従来の勾配ベースの手法であるGRPOと比較して、数学や推論タスクにおいて同等の性能を達成しつつ、メモリ消費を大幅に抑えられる可能性を秘めています。 しかし、本研究の分析により、ESを用いた学習はモデルが既に持っていた既存の知識を急速に失わせる「破滅的忘却」を引き起こし、特定のタスクに特化する一方で汎用性が著しく低下することが判明しました。 この忘却の原因は、ESによるパラメータ更新がGRPOに比べて1000倍も大きなノルムを持ち、かつモデル全体にわたる高密度な変更を加えることで、既存の知識構造を破壊してしまう点にあると結論付けられています。
なぜこの問題か
現在のAIシステム、特に大規模言語モデル(LLM)における最大の欠如の一つは、デプロイ後に継続的に学習する能力が不足していることです。 多くの実世界のシナリオにおいて、モデルは新しいタスクやユーザーの好み、あるいは変化するデータ分布に適応する必要がありますが、現在の主要な学習手法はデプロイ後の継続的な更新には向いていません。 その主な理由として、現在のLLMの適応手法がSFT、RLHF、DPO、GRPOといった「勾配ベース」のアルゴリズムに限定されていることが挙げられます。 これらの手法は非常に効果的ではありますが、学習中に勾配、オプティマイザの状態、あるいは中間的なアクティベーションを保存しておく必要があり、膨大なメモリオーバーヘッドが発生します。 このメモリ要件の高さが、リソースが限られた環境やリアルタイムでのモデル更新を困難にする大きな障壁となっています。 そこで、バックプロパゲーション(誤差逆伝播法)を必要としない「勾配不要(Gradient-free)」な学習アルゴリズムとして、進化戦略(Evolutionary Strategies, ES)が再び注目を集めています。…
核心:何を提案したのか
本研究では、LLMのファインチューニングにおける進化戦略(ES)の包括的な実証分析を提案し、特に「継続学習」と「忘却」の観点からその特性を評価しました。 具体的には、最新の勾配ベースの強化学習アルゴリズムであるGRPO(Group Relative Policy Optimization)を比較対象として設定しました。 複数の数学および推論のベンチマークタスクを用いて、ESとGRPOの学習曲線および忘却曲線を詳細に比較検討しています。 先行研究ではESが特定のタスクでGRPOを上回ると報告されていましたが、本研究ではより広範なタスクセットと厳密な評価プロトコルを用いて、その主張を再検証しました。 さらに、単に新しいタスクの正解率を追うだけでなく、学習が進むにつれてモデルの既存能力がどのように変化するかを追跡する「忘却曲線」の導入が本研究の核心的なアプローチです。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related