構造的および論理的洗練を用いたマルチエージェントによる手続き型グラフ抽出
自然言語からワークフローを抽出する際、従来の大型言語モデルでは構造的な不備や論理的な誤解が生じやすいという課題に対し、本研究ではグラフ構築、構造シミュレーション、論理整合性確認の3段階を繰り返すマルチエージェントフレームワーク「text2flow」を提案しました。
TL;DR(結論)
自然言語からワークフローを抽出する際、従来の大型言語モデルでは構造的な不備や論理的な誤解が生じやすいという課題に対し、本研究ではグラフ構築、構造シミュレーション、論理整合性確認の3段階を繰り返すマルチエージェントフレームワーク「text2flow」を提案しました。 この手法は、シミュレーションによる実行経路の検証と原文との意味的な照合を組み合わせ、外部フィードバックに基づく反復的な推論プロセスを導入することで、追加の学習を必要とせずにグラフの構造的正確性と論理的一貫性を大幅に向上させることに成功しました。 具体的には、シミュレーションで検出された実行不可能な経路や、原文の条件と矛盾するゲートウェイ設定を自然言語のフィードバックとしてモデルに返し、優先順位付けされた修正指示を通じて、複雑な非線形構造を持つ手続き型グラフを高い信頼性で生成することを可能にしました。
なぜこの問題か
自然言語で記述された文書から手続き型グラフを抽出することは、業務プロセスのデジタル化や自動コンプライアンスチェック、知能システムへの構造的知識の提供において極めて重要な役割を果たします。しかし、このタスクは従来のエンティティ抽出や知識グラフ構築とは本質的に異なり、単なる静的な関係性だけでなく、条件分岐や並列実行といった動的な実行フローを正確にモデル化する必要があります。既存の情報抽出技術はエンティティ間の意味的関係に焦点を当てており、手続き型文書に固有の条件付きロジックや反復ループを明示的に扱うことが困難でした。また、ルールベースの手法や特定のニューラルネットワーク構造を用いた手法では、複雑で非線形なシナリオへの汎用性が低く、多様な表現に対応できないという限界がありました。 近年の大型言語モデル(LLM)は構造化データの抽出において高い可能性を示していますが、一度のプロンプト入力による生成では、実行不可能な経路を含む不完全な構造を出力したり、ゲートウェイの論理を誤認したりすることが頻繁に発生します。…
核心:何を提案したのか
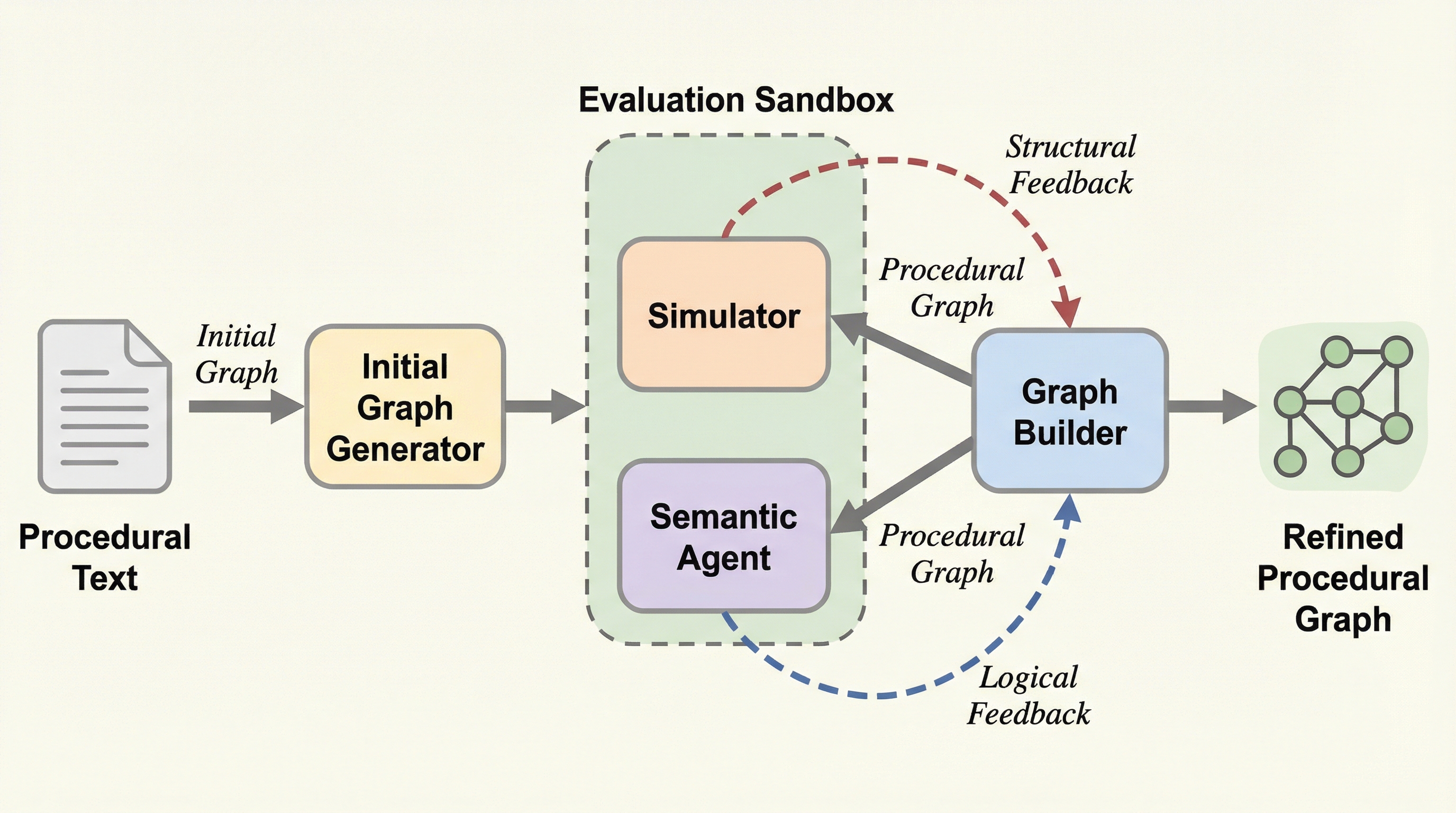
本研究では、手続き型グラフの抽出をマルチラウンドの推論プロセスとして定式化したマルチエージェントフレームワーク「text2flow」を提案しています。このフレームワークの核心は、グラフの抽出プロセスを「グラフ構築」「構造的フィードバック」「論理的フィードバック」の3つの反復的なステージに分離した点にあります。具体的には、まずグラフ構築エージェントが初期のグラフを生成し、次にシミュレーションエージェントがグラフのトポロジー的な問題を診断し、最後に意味エージェントがフローの論理と原文の言語的ヒントを照合します。 これらのエージェントは、モデルの内部状態に依存しない外部的な検証結果に基づいて、自然言語による解釈可能なフィードバックを生成します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related