$\mathbb{R}^{2k}$ is Theoretically Large Enough for Embedding-based Top-$k$ Retrieval
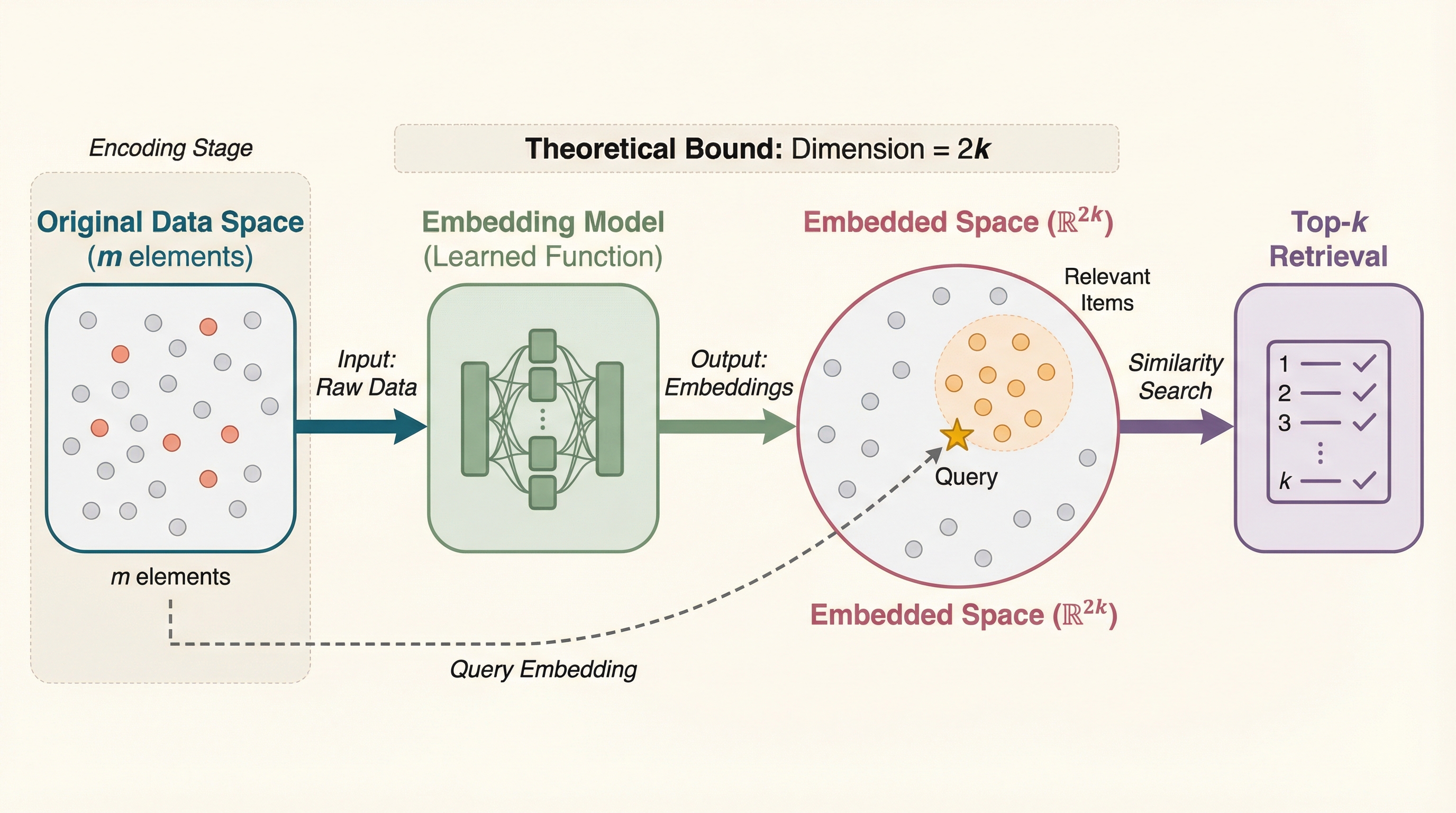
本研究は、要素数mの集合から最大k個の要素を検索するために必要な最小埋め込み次元(MED)を理論的に解明し、内積やコサイン類似度、ユークリッド距離といった主要な指標において、理論上は要素数mに依存せず2k次元あれば十分であることを数学的に証明した。
TL;DR(結論)
本研究は、要素数mの集合から最大k個の要素を検索するために必要な最小埋め込み次元(MED)を理論的に解明し、内積やコサイン類似度、ユークリッド距離といった主要な指標において、理論上は要素数mに依存せず2k次元あれば十分であることを数学的に証明した。 さらに、クエリを回答セットの重心とする制約を課した「重心設定」においても、必要な次元数は要素数mに対して対数的な増加(log m)に留まることを示し、従来の多項式的な増加が必要であるという認識を覆すとともに、低次元空間が持つ驚異的な表現能力を明らかにした。 これらの結果は、現在の検索システムの精度限界が空間の幾何学的な容量(近似可能性)にあるのではなく、最適なベクトル配置を導き出すアルゴリズムの難しさ(学習可能性)にあることを示唆しており、今後のシステム設計において次元の拡大よりも学習手法の改善が重要であることを理論と実験の両面から裏付けている。
なぜこの問題か
現代の情報検索や推薦システムにおいて、膨大なデータの中からクエリに適合する上位k個の要素を高速に抽出する手法として、要素をベクトル空間に埋め込む手法は不可欠な技術となっている。しかし、検索対象となる要素数mが数百万、数千万と増大し続ける中で、検索精度を維持するために必要な埋め込み次元dをどのように設定すべきかという問いは、長らく理論的な未解決問題であった。これまでの経験的な知見や一部の先行研究では、要素数mが増えるにつれて、必要な次元数も多項式的に増大させなければならないという予測がなされており、これが埋め込みベースの検索における幾何学的な限界であると広く信じられてきた。もしこの予測が正しければ、大規模なデータを扱うためには次元数を際限なく増やす必要があり、計算コストやメモリ使用量の増大という「次元の呪い」を避けることはできないことになる。…
核心:何を提案したのか
本論文の核心的な提案は、特定のスコアリング関数を用いて最大k個の要素を正確に検索するために必要な最小次元数(MED)を定義し、その厳密な上下界を数学的に導出したことにある。具体的には、内積、コサイン類似度、ユークリッド距離という、現在広く利用されている主要な三つの関数において、MEDは要素数mに依存せず、検索対象数kに対して線形なオーダーである2k次元(コサイン類似度の場合は2k+1次元)あれば理論上は十分であることを証明した。これは、たとえ検索対象が無限に近い数であっても、特定のk個の要素を他のすべての要素から識別して抽出するためには、kの定数倍程度の非常に低い次元数で事足りるという驚くべき事実を示している。この発見は、次元数が要素数mとともに増大しなければならないという従来の多項式的な予測を根本から覆すものであり、埋め込み空間が持つ幾何学的な容量が、我々の想定をはるかに上回るものであることを理論的に裏付けている。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related