TS-Debate:ゼロショット時系列推論のためのマルチモーダル協調ディベート
大規模言語モデル(LLM)を用いた時系列データ推論において、数値の正確性の欠如やモダリティ間の干渉、そして体系的な統合の難しさが大きな課題となっている。本研究では、テキスト、視覚、数値の各モダリティに特化した専門エージェントが協調して議論を行う、ゼロショット時系列推論のための新しいフレームワーク「TS-Debate」を提案する。 この手法は、事前にドメイン知識を抽出した上で、各エージェントが独自の視点から観察と推論を行い、その主張をコード実行や数値検索ツールを備えたレビュー担当者が検証する仕組みを持つ。検証・対立・較正(VCC)プロトコルにより、モダリティ間の矛盾を明示的に解消し、数値的なハルシネーションを抑制しながら、信頼性の高い回答を導き出す。 3つの公開ベンチマークに含まれる20のタスクで評価を行った結果、既存の強力なベースラインと比較して大幅な性能向上を達成し、特に時系列データの構造理解と数値的忠実度の両立において優れた成果を示した。タスク固有の微調整を必要とせず、推論時の構造化された対話のみで、複雑な時系列推論を堅牢に実行できることが実証された。
TL;DR(結論)
大規模言語モデル(LLM)を用いた時系列データ推論において、数値の正確性の欠如やモダリティ間の干渉、そして体系的な統合の難しさが大きな課題となっている。本研究では、テキスト、視覚、数値の各モダリティに特化した専門エージェントが協調して議論を行う、ゼロショット時系列推論のための新しいフレームワーク「TS-Debate」を提案する。 この手法は、事前にドメイン知識を抽出した上で、各エージェントが独自の視点から観察と推論を行い、その主張をコード実行や数値検索ツールを備えたレビュー担当者が検証する仕組みを持つ。検証・対立・較正(VCC)プロトコルにより、モダリティ間の矛盾を明示的に解消し、数値的なハルシネーションを抑制しながら、信頼性の高い回答を導き出す。 3つの公開ベンチマークに含まれる20のタスクで評価を行った結果、既存の強力なベースラインと比較して大幅な性能向上を達成し、特に時系列データの構造理解と数値的忠実度の両立において優れた成果を示した。タスク固有の微調整を必要とせず、推論時の構造化された対話のみで、複雑な時系列推論を堅牢に実行できることが実証された。
なぜこの問題か
時系列データは、金融、気候学、産業モニタリングなどの重要な意思決定の基盤となっている。近年、大規模言語モデル(LLM)を時系列分析に応用する試みが進んでいるが、単なる予測を超えた「推論」を中心とした問いに答えることは依然として困難である。例えば、「この異常の原因は何か」「過去のどのパターンが現在の軌跡と一致するか」「現在のトレンドの根本原因は持続するか」といった質問に答えるには、数値的な精度、時間的構造の把握、そしてドメイン知識の統合が必要となる。現在のLLMは、慎重に設計されたコンテキストが与えられれば時間的構造を推論できる可能性を示しているものの、数値的な忠実度の低さや、異なるモダリティ間での干渉、そして原則に基づいたクロスモーダルな統合の欠如という脆弱性を抱えている。 時系列推論は本質的にマルチモーダルな性質を持つ。視覚的なプロンプティングは、長い数値配列をチャートに圧縮することで、マルチモーダルLLMが効率的に解析できるようにし、トークンコストを削減しながらパターン認識を向上させる。また、時間領域や周波数領域の可視化は、テキストや数値のみのプロンプトでは見落とされがちな顕著な時間構造を明らかにする。…
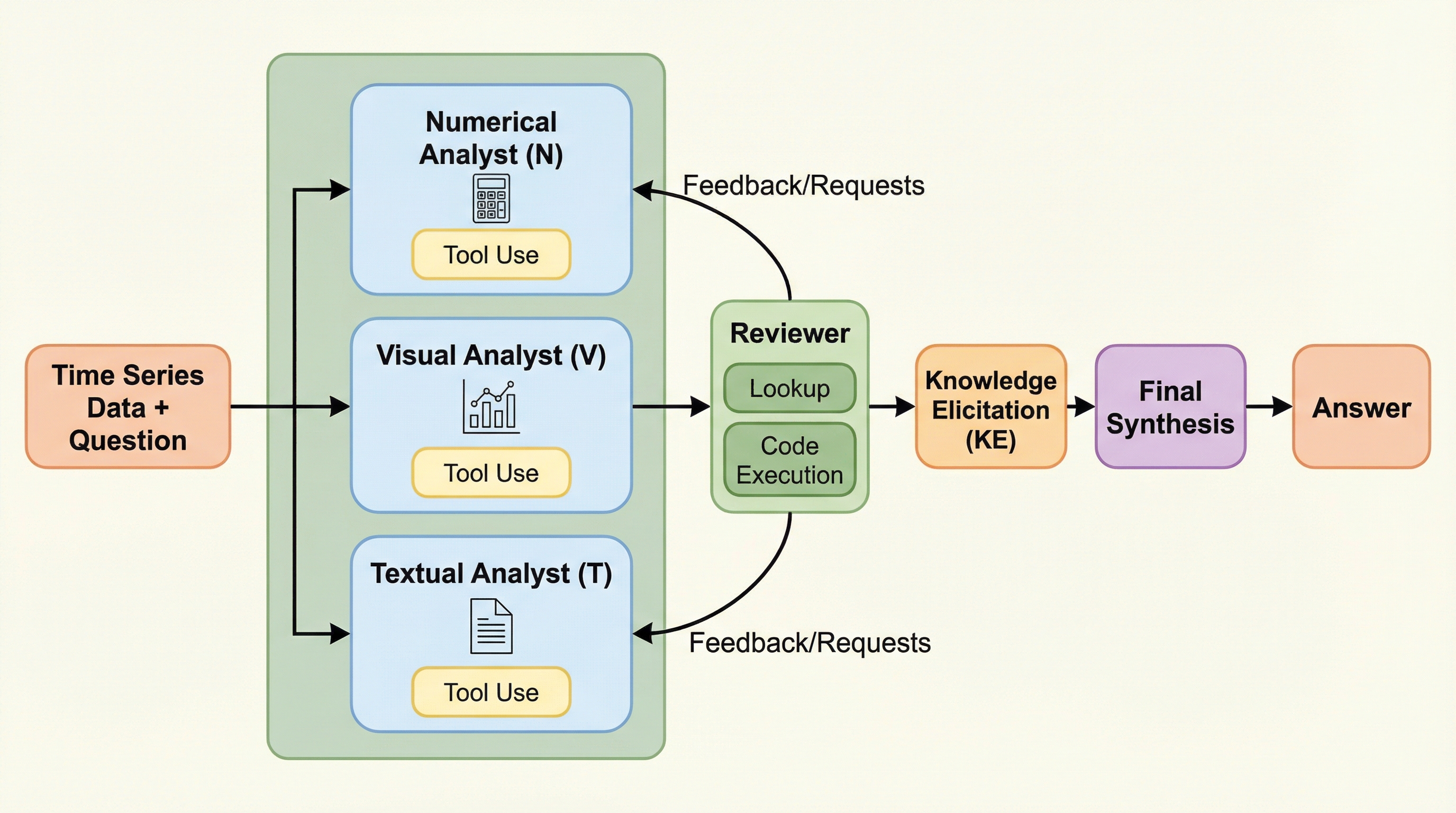
核心:何を提案したのか
本研究では、ゼロショット時系列推論のためのマルチモーダル協調ディベート・フレームワークである「TS-Debate」を提案する。このフレームワークの核心は、モダリティごとに専門化されたエージェントを配置し、それらを敵対的ではなく協力的なチームとして機能させる点にある。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related