SokoBench:大規模言語モデルにおける長期的な計画と推論の評価
SokoBenchは、大規模言語モデル(LLM)の長期的な計画能力を評価するために、倉庫番パズルを直線的な廊下状のマップに簡略化した新しいベンチマークである。空間的な複雑さを排除し、純粋に手順の長さ(ホライゾン)がモデルの内部的な推論や状態保持に与える影響を測定した結果、解決に25手以上を要する課題では正確性が急激に低下することが判明した。 外部の計画言語(PDDL)ツールを組み合わせるLLM-Modulo手法を導入しても性能向上は限定的であり、モデル内部の空間推論や逐次的な論理構築における根本的な限界が浮き彫りになった。本研究は、現在の推論モデルが単純な記号操作の積み重ねにおいてさえ、長期的な一貫性を維持できないというシステム的な欠陥を明らかにしている。 最新の推論モデルであっても、分岐のない単純な環境においてステップ数が増加するだけで論理的な破綻を来すことが示されており、これはモデル内部での状態保持や計数能力がステップ数の増加に伴って指数関数的に劣化するためである。この結果は、現在のモデルが持つ前方計画の容量には物理的または構造的な限界が存在することを示唆している。
TL;DR(結論)
SokoBenchは、大規模言語モデル(LLM)の長期的な計画能力を評価するために、倉庫番パズルを直線的な廊下状のマップに簡略化した新しいベンチマークである。空間的な複雑さを排除し、純粋に手順の長さ(ホライゾン)がモデルの内部的な推論や状態保持に与える影響を測定した結果、解決に25手以上を要する課題では正確性が急激に低下することが判明した。 外部の計画言語(PDDL)ツールを組み合わせるLLM-Modulo手法を導入しても性能向上は限定的であり、モデル内部の空間推論や逐次的な論理構築における根本的な限界が浮き彫りになった。本研究は、現在の推論モデルが単純な記号操作の積み重ねにおいてさえ、長期的な一貫性を維持できないというシステム的な欠陥を明らかにしている。 最新の推論モデルであっても、分岐のない単純な環境においてステップ数が増加するだけで論理的な破綻を来すことが示されており、これはモデル内部での状態保持や計数能力がステップ数の増加に伴って指数関数的に劣化するためである。この結果は、現在のモデルが持つ前方計画の容量には物理的または構造的な限界が存在することを示唆している。
なぜこの問題か
大規模言語モデル(LLM)は、自然言語理解や知識検索、マルチモーダルなパターン認識において目覚ましい進歩を遂げているが、長期的な計画(Long-horizon planning)能力については十分に解明されていない。自動計画は、特定の目標を達成するための一連のアクションを生成するタスクであり、推論、理解、そして効率的な状態空間の探索といった高度な認知能力を必要とする。これまでの研究では、LLMが計画タスクにおいて限界に直面することが指摘されており、特に制約のある環境での空間探索のように、逐次的な状態情報を正確に維持する必要がある問題で苦戦していることが示されている。モデル内部の推論プロセスは、体系的な探索というよりも、解空間を目的もなく彷徨っているような状態に近いという指摘もあり、これが長期的な一貫性を損なう要因となっている。 このような背景から、モデルが外部の記憶やフィードバックに頼らず、自身の内部状態表現だけでどれほど一貫した計画を維持できるかを評価することが重要となっている。…
核心:何を提案したのか
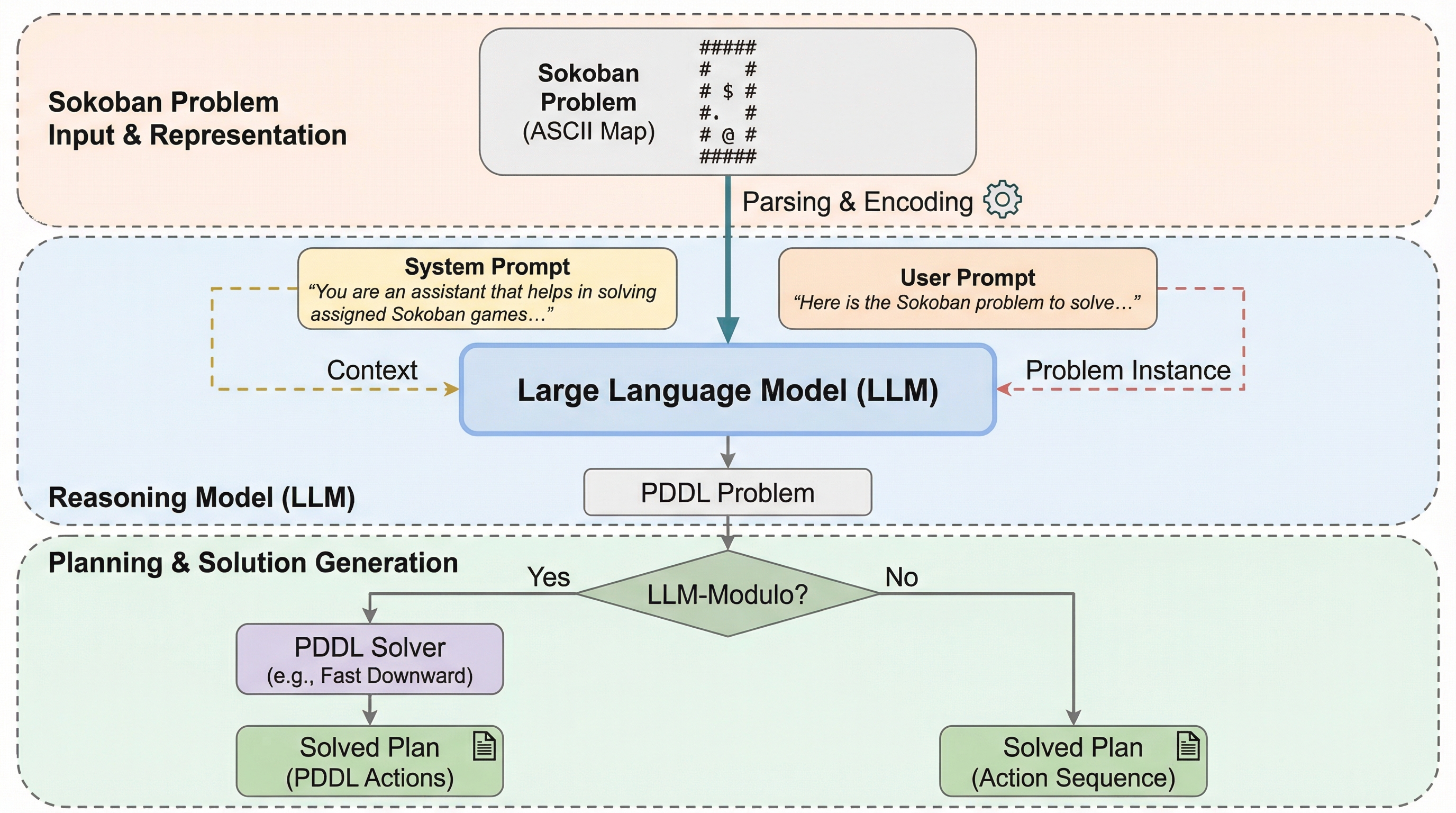
本研究では、倉庫番(Sokoban)パズルを極限まで簡略化した新しいベンチマークである「SokoBench」を提案した。倉庫番は本来、空間的な制約の中で箱を目的地に運ぶNP困難かつPSPACE完全な問題であるが、本ベンチマークではあえて構造的な複雑さを最小限に抑えている。具体的には、幅が1で高さが1、長さが$\ell$の直線的な廊下状のマップを使用し、その中にプレイヤー、箱、ゴールをそれぞれ1つずつ配置する構成とした。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related