SHIELD:LLMリソース枯渇攻撃に対する自己修復型エージェント防御フレームワーク
大規模言語モデル(LLM)の計算リソースを過剰に消費させ、サービス停止(DoS)を引き起こす「スポンジ攻撃」に対し、3段階の防御パイプラインと自己修復機能を備えたマルチエージェントフレームワーク「SHIELD」が提案されました。
TL;DR(結論)
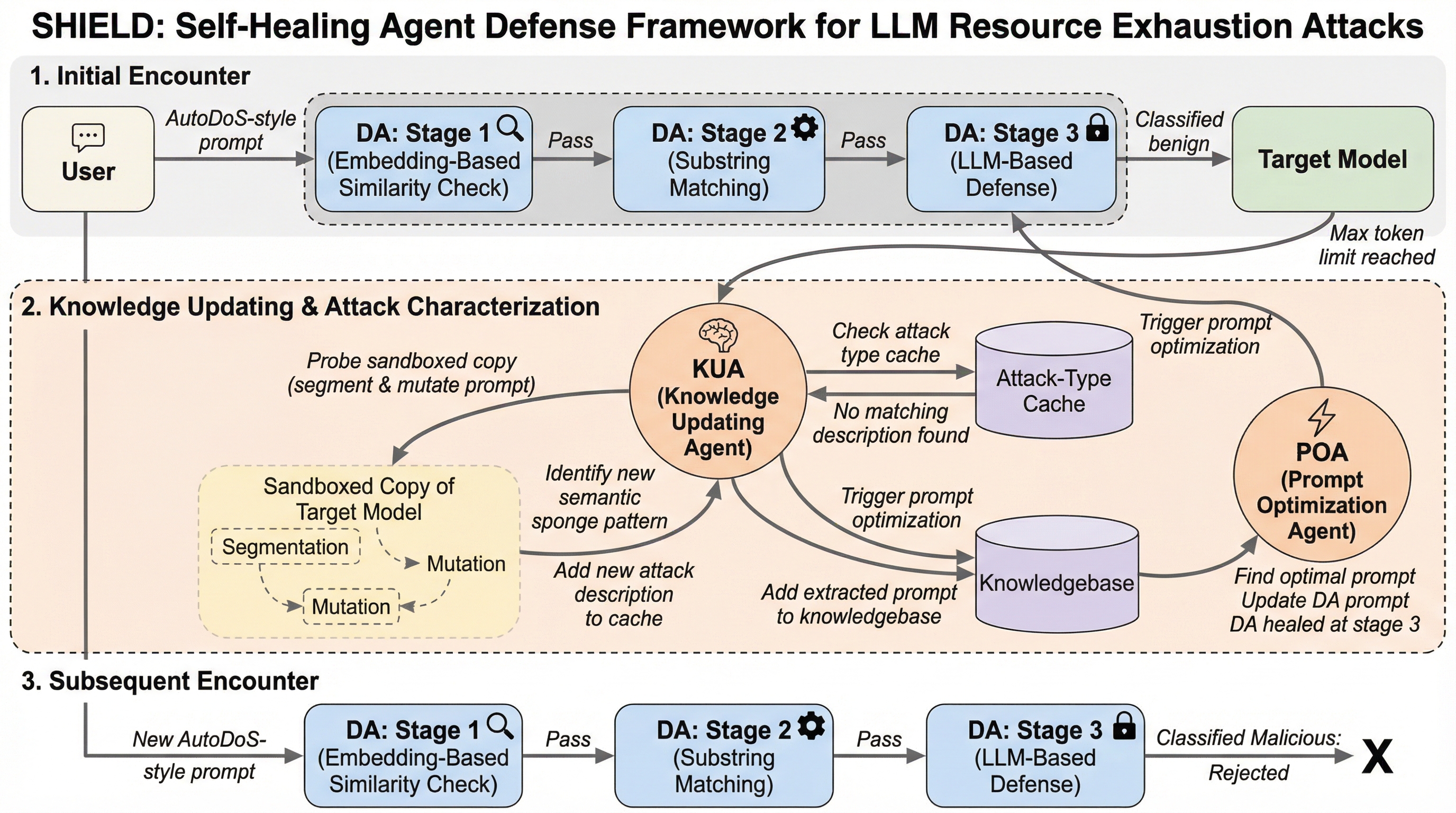
大規模言語モデル(LLM)の計算リソースを過剰に消費させ、サービス停止(DoS)を引き起こす「スポンジ攻撃」に対し、3段階の防御パイプラインと自己修復機能を備えたマルチエージェントフレームワーク「SHIELD」が提案されました。 このシステムは、意味的類似性の検索、部分文字列の照合、LLMによる推論を組み合わせることで、従来の統計的フィルタでは検知が困難であった自然な文章を装う高度な攻撃も高精度に遮断し、既存手法を最大14%上回る性能を達成しています。 攻撃が防御を突破した際には、知識更新エージェントとプロンプト最適化エージェントが自動で失敗を分析して知識ベースを更新し、モデルの再学習なしに防御プロンプトを洗練させることで、未知の脅威に対しても自律的に適応し続けることが可能です。
なぜこの問題か
大規模言語モデル(LLM)は、自律的な意思決定や複雑な推論を必要とするミッションクリティカルなアプリケーションにおいて、その採用が急速に広がっています。しかし、システムの複雑さが増すにつれて、悪意のある操作に対する脆弱性も拡大しており、特に「スポンジ攻撃」と呼ばれるリソース枯渇型の攻撃が深刻な脅威となっています。この攻撃は、意図的に過剰な計算を誘発したり、異常なトークン生成を引き起こしたりすることで、システムの遅延を大幅に増大させ、最終的にはサービス拒否(DoS)状態に陥らせるものです。一見すると単純なプロンプトであっても、LLMの内部で非常に長い推論プロセスを強制するように設計されている場合、単一のクエリがGPUリソースを独占し、他の正当なユーザーの利便性を著しく損なう可能性があります。 従来の防御策としては、トークンの分布を統計的に分析するパープレキシティ(Perplexity)ベースのフィルタリングが存在しますが、これは意味を持たないトークンの羅列には有効なものの、文脈的に自然な言葉の中に悪意を潜ませた高度な攻撃には対応できません。…
核心:何を提案したのか
本論文では、LLMスポンジ攻撃に対抗するための世界初の自己修復型エージェント防御フレームワークである「SHIELD(Self-Healing Intelligent Evolving LLM Defense)」を提案しています。SHIELDの最大の特徴は、防御パイプラインと知識更新パイプラインという、密接に連携する2つの主要なコンポーネントで構成されている点にあります。このフレームワークは、モデルの再学習を一切必要としない「トレーニングフリー」な設計を採用しており、既存のブラックボックスなLLMシステムにも容易に導入できる柔軟性を備えています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related