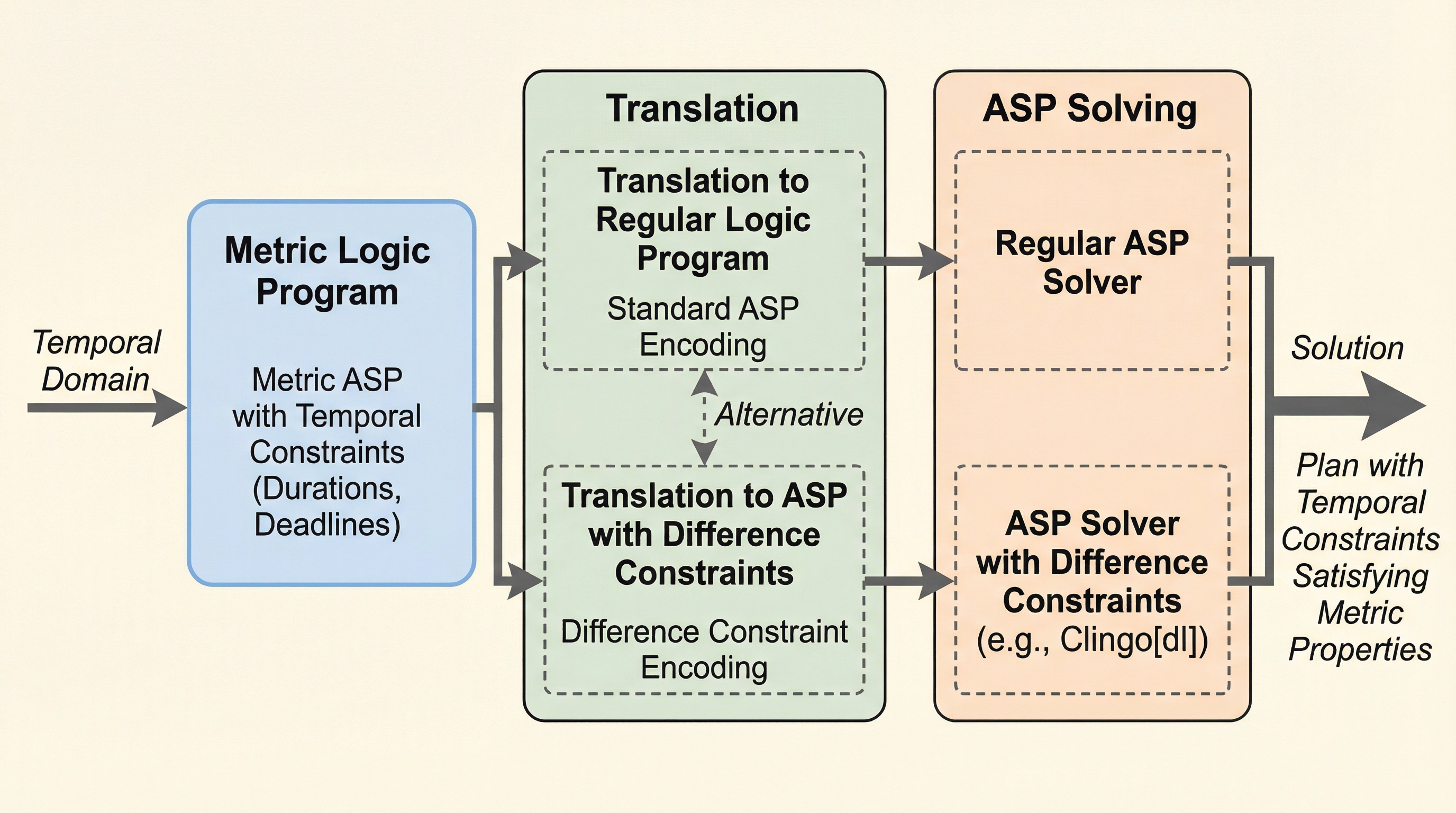
計量時相回答セットプログラミングの実装
回答セットプログラミング(ASP)において、期間や締め切りといった定量的な時間制約を扱う際、時間の精度を上げると接地(グラウンディング)の負荷が爆発的に増大する問題がありました。 / 本研究では、差分制約という簡略化された線形制約を導入して時間処理を外部化することで、時間の粒度に依存しないスケーラブルな計算手法を提案し、その論理的な正当性を証明しました。 / 具体的には、メトリック論理プログラムを通常の論理プログラムや差分制約付きプログラムへ変換する二つの翻訳手法を開発し、時間の最大値や精度に関わらず、プログラムの規模をトレースの長さに比例する範囲に抑えることを可能にしました。