自己蒸留による強化学習:リッチなフィードバックを密な学習信号へ変換する新手法「SDPO」
現在の強化学習(RLVR)は、成功か失敗かというスカラー値の報酬のみに依存しており、なぜ失敗したかという詳細な情報を学習に活かせないボトルネックがある。本研究が提案するSDPOは、実行エラーや判定結果などの「リッチなフィードバック」をモデル自身に読み込ませ、自己教師として過去の回答を再評価させることで、密度の高い学習信号を生成する手法である。検証の結果、科学的推論やプログラミングにおいて、既存手法のGRPOを大幅に上回る学習効率と精度を達成し、特に難易度の高い課題では3倍少ない試行回数で正解に到達することが確認された。
TL;DR(結論)
現在の強化学習(RLVR)は、成功か失敗かというスカラー値の報酬のみに依存しており、なぜ失敗したかという詳細な情報を学習に活かせないボトルネックがある。本研究が提案するSDPOは、実行エラーや判定結果などの「リッチなフィードバック」をモデル自身に読み込ませ、自己教師として過去の回答を再評価させることで、密度の高い学習信号を生成する手法である。検証の結果、科学的推論やプログラミングにおいて、既存手法のGRPOを大幅に上回る学習効率と精度を達成し、特に難易度の高い課題では3倍少ない試行回数で正解に到達することが確認された。
なぜこの問題か
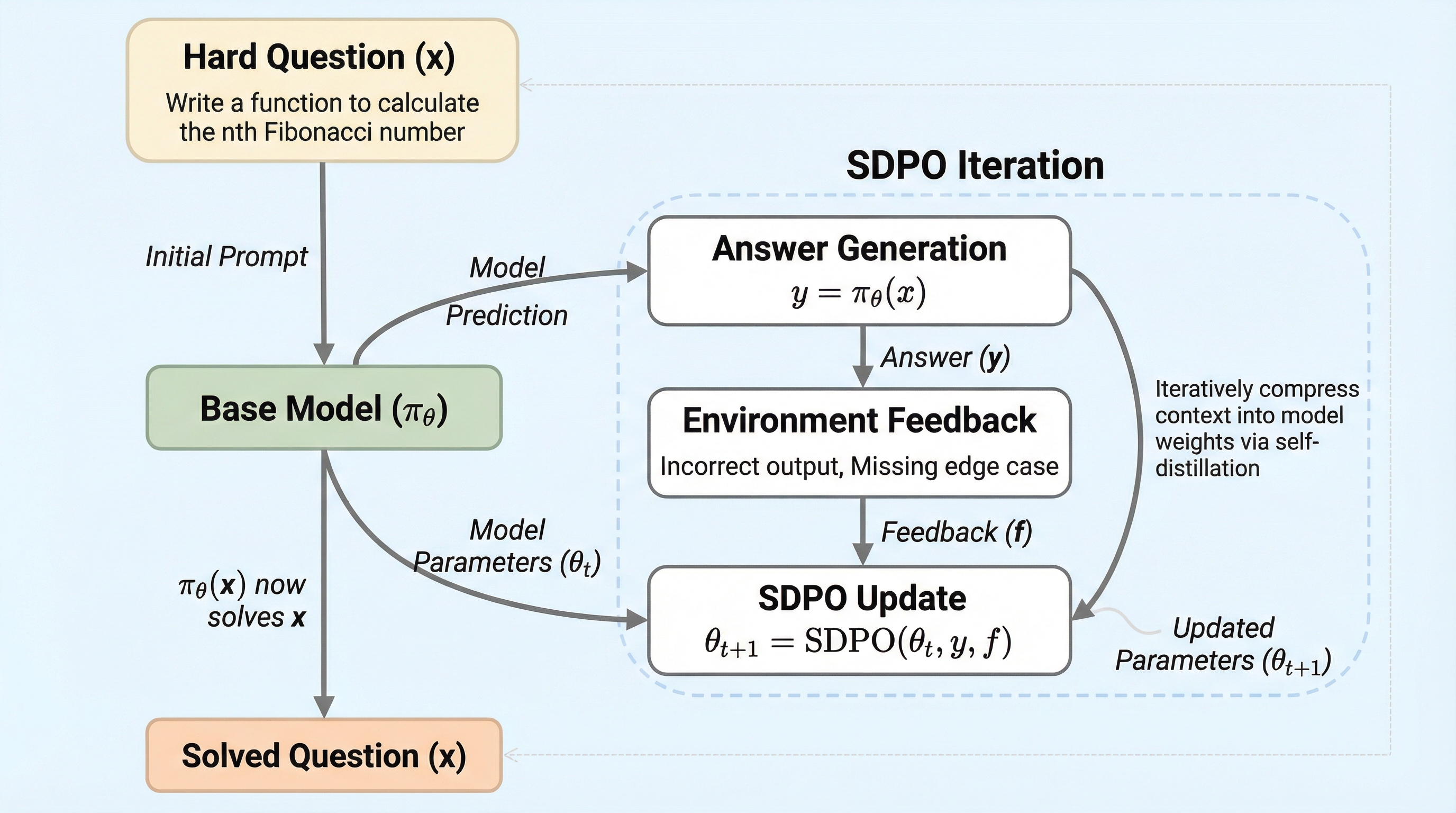
大規模言語モデルのポストトレーニングにおいて、コード生成や数学などの検証可能な領域での強化学習は非常に重要な役割を果たしている。しかし、現在主流となっている手法の多くは、各試行に対して「正解」か「不正解」かというスカラー値の報酬のみを受け取る設定(RLVR)に限定されている。この設定では、モデルがなぜその回答を導き出したのか、あるいはどこで間違えたのかという詳細なプロセスが、単一の数値の中に埋もれてしまうという課題がある。これはクレジット割り当てにおける深刻なボトルネックとなり、学習の効率を著しく低下させる要因となっている。特に、すべての試行が失敗して報酬がゼロになった場合、学習が停滞してしまうという欠点がある。 一方で、実際の検証環境には、単なる数値以上の豊かな情報が含まれていることが多い。例えば、プログラミング環境であればランタイムエラーの内容やメモリ制限の超過、論理的な推論であれば外部の判定器による詳細な評価コメントなどが存在する。これらの情報は、単に失敗したという事実だけでなく、失敗の「理由」を説明するテキストデータとして提供される。…
核心:何を提案したのか
本研究が提案する「自己蒸留ポリシー最適化(SDPO)」は、モデル自身のコンテキスト内学習能力を活用して、環境からのフィードバックを直接的な学習信号に変換するアルゴリズムである。SDPOの最大の特徴は、外部の教師モデルを一切必要とせず、現在のポリシー自身を「自己教師」として利用する点にある。具体的には、モデルが生成した回答に対して環境から得られたリッチなフィードバックを、同じモデルにプロンプトとして入力する。これにより、モデルは自身の過去の過ちを振り返り、どこを修正すべきかを事後的に判断することが可能になる。 このプロセスにおいて、モデルは二つの役割を果たす。一つは、最初の回答を生成する「生徒」としての役割であり、もう一つは、フィードバックを基にその回答を再評価する「教師」としての役割である。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related