失敗プレフィックス条件付けによる飽和問題での推論モデルの学習
検証可能な報酬を用いた強化学習(RLVR)において、モデルが問題をほぼ完璧に解けるようになる「飽和状態」では学習信号が消失し、性能向上が停滞するという課題がある。 本研究は、稀に発生する誤った推論の断片(失敗プレフィックス)を問題文に付与して学習を開始させる「失敗プレフィックス条件付け」を提案し、意図的に失敗しやすい状態から探索させることで学習信号を回復させる。 実験の結果、飽和した問題のみを用いても中難易度の問題で学習した場合と同等の性能向上を達成し、推論の堅牢性が向上するとともに、トークン効率を維持したまま反復的な学習によってさらなる改善が可能であることを示した。
TL;DR(結論)
検証可能な報酬を用いた強化学習(RLVR)において、モデルが問題をほぼ完璧に解けるようになる「飽和状態」では学習信号が消失し、性能向上が停滞するという課題がある。 本研究は、稀に発生する誤った推論の断片(失敗プレフィックス)を問題文に付与して学習を開始させる「失敗プレフィックス条件付け」を提案し、意図的に失敗しやすい状態から探索させることで学習信号を回復させる。 実験の結果、飽和した問題のみを用いても中難易度の問題で学習した場合と同等の性能向上を達成し、推論の堅牢性が向上するとともに、トークン効率を維持したまま反復的な学習によってさらなる改善が可能であることを示した。
なぜこの問題か
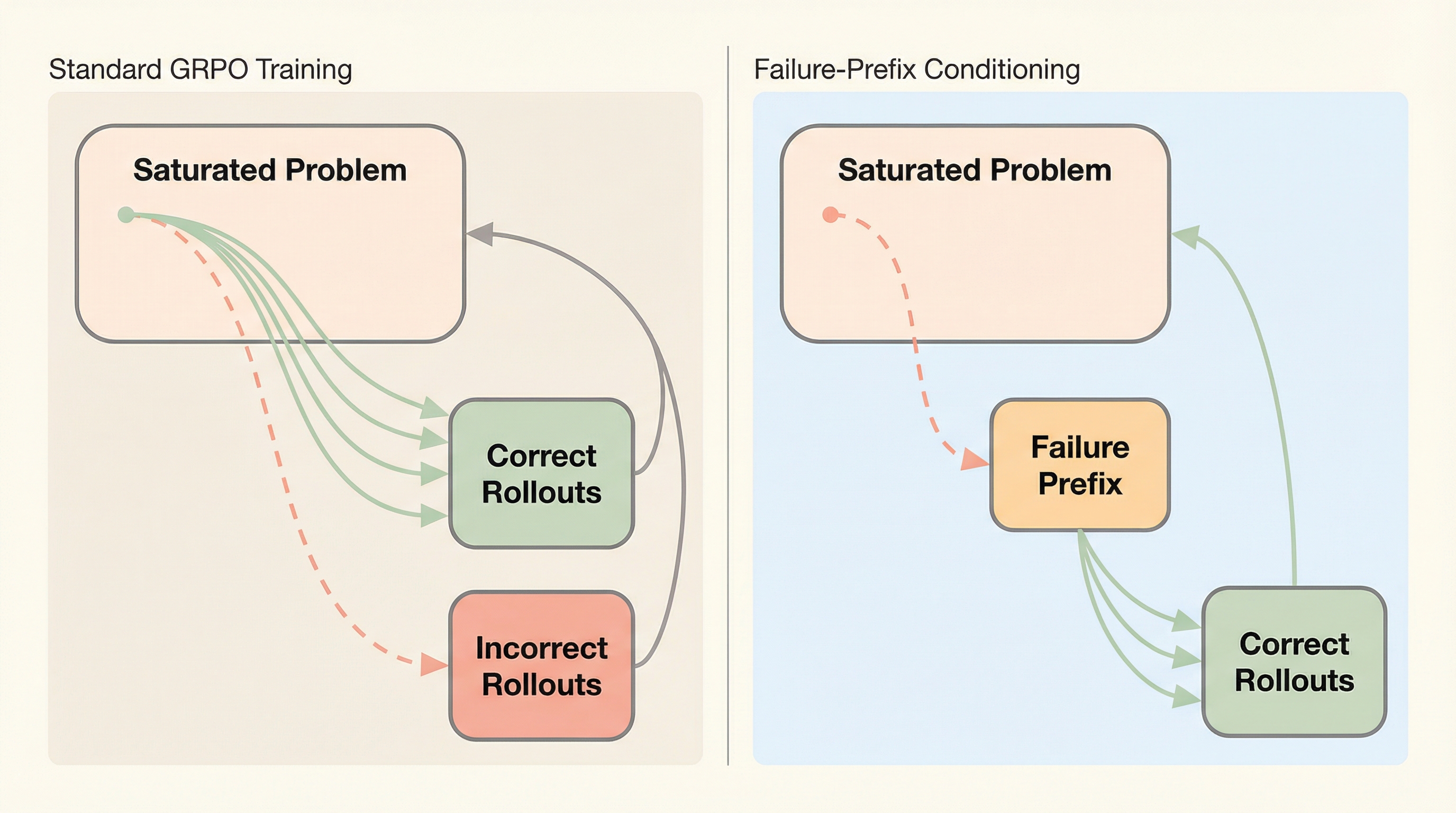
検証可能な報酬を用いた強化学習(RLVR)は、大規模言語モデル(LLM)の推論能力を大幅に向上させてきたが、学習が進むにつれて「飽和問題」と呼ばれる現象に直面する。飽和問題とは、モデルが特定のトレーニング問題をほぼ全ての試行(ロールアウト)で正解してしまう状態を指す。このような問題では、報酬がほぼ決定論的に正解(1)となるため、報酬の分散が消失し、強化学習の勾配がゼロに近づいて学習が停滞してしまう。先行研究では、学習信号を最大化するためには正解率が50%程度の中難易度の問題が理想的であるとされているが、モデルが進化するほど既存のデータセット内の多くの問題が飽和し、利用可能な学習信号が枯渇していくという課題があった。 しかし、飽和した問題であっても、モデルの推論空間には依然として誤った推論の軌跡が存在している。標準的なサンプリング手法では、これらの「有益な失敗」に遭遇する確率が極めて低いため、学習リソースの大部分が冗長な正解の生成に費やされてしまう。つまり、飽和問題における根本的な課題は、有益な失敗が存在しないことではなく、それらへの「アクセスの悪さ」にある。…
核心:何を提案したのか
本研究は、飽和した問題から学習信号を効率的に回収するためのシンプルかつ効果的な手法として「失敗プレフィックス条件付け(Failure-Prefix Conditioning)」を提案した。この手法の核心は、元の問題文から推論を開始するのではなく、モデルが過去に生成した「稀な誤答」の冒頭部分(プレフィックス)を問題文の直後に結合し、そこから推論を継続させる点にある。これにより、モデルは意図的に失敗しやすい推論状態に置かれ、そこから正解にたどり着くための探索を強制される。このアプローチは、探索の範囲を推論空間内の不確実性が高い領域、すなわち失敗が発生しやすい領域へと再配分する役割を果たす。 具体的には、まず飽和した問題に対してモデルが生成した稀な誤答を特定し、それを複数の長さの断片に分割する。次に、それぞれの断片をプレフィックスとして与えた場合の正解率を測定し、学習信号が最大化されるターゲット正解率(例えば0.…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related