報酬モデルは事前学習から価値バイアスを継承する
報酬モデル(RM)は、大規模言語モデル(LLM)を人間の価値観に合わせる「アライメント」の中核を担うが、初期化に使用される事前学習済みモデルから心理的なバイアスを直接継承していることが判明した。
TL;DR(結論)
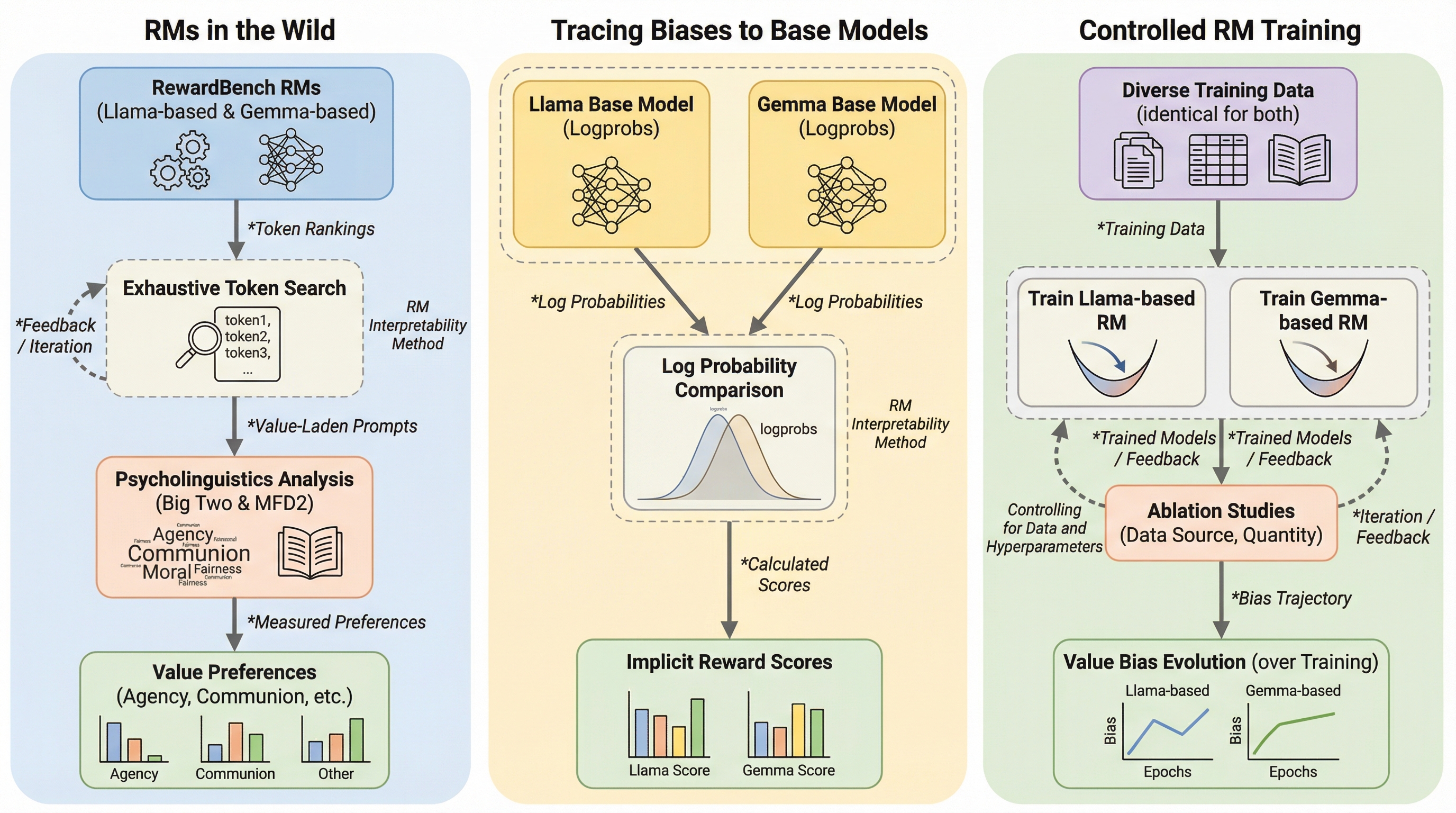
報酬モデル(RM)は、大規模言語モデル(LLM)を人間の価値観に合わせる「アライメント」の中核を担うが、初期化に使用される事前学習済みモデルから心理的なバイアスを直接継承していることが判明した。 具体的には、Llamaベースの報酬モデルは「自己主導性(Agency)」に関連する自由や成功を好む傾向があり、一方でGemmaベースのモデルは「共同体性(Communion)」に関連する愛や友情を優先する傾向が強い。 この価値観の偏りは、学習に使用する好みのデータセットや学習量を変更しても解消されにくいほど強固であり、アライメント段階だけでなく事前学習段階における安全性と価値観の設計が極めて重要であることを示唆している。
なぜこの問題か
大規模言語モデル(LLM)を人間の好みや価値観に適合させるプロセスにおいて、報酬モデル(RM)は中心的な役割を果たしている。しかし、これまでAIの安全性やアライメントに関する研究の多くは、事前学習済みモデルや事後学習後のLLMそのものに焦点を当てており、報酬モデル自体の特性については十分な注目が集まってこなかった。報酬モデルは通常、既存のLLMをベースとして初期化され、その後に人間の好みを反映したデータセットで微調整される。このため、報酬モデルはベースとなるLLMが持つ内部表現をそのまま引き継ぐことになるが、その影響の性質や範囲についてはこれまで体系的に調査されていなかった。 特に、オープンソースで公開されている主要なモデルファミリーの間で、どのような価値観の相違が存在するのかを理解することは、AIシステムの透明性と信頼性を確保する上で不可欠である。もし報酬モデルが特定の価値観に偏っているならば、それを用いて最適化された最終的なAIモデルもまた、開発者が意図しないバイアスを持つ可能性がある。…
核心:何を提案したのか
本研究は、報酬モデルが事前学習から価値観のバイアスを継承しているという仮説を検証するため、包括的な調査手法を提案した。具体的には、RewardBenchに登録されている主要な10種類のオープンウェイト報酬モデルを対象とし、心理言語学的な手法を組み合わせてその価値観を分析した。研究の核心は、報酬モデルの語彙全体に対して報酬スコアを算出する「網羅的トークン探索(Exhaustive Token Search)」という手法を用い、特定の価値観に関連する単語がどのように評価されるかを定量化した点にある。 分析には、心理学的に検証された2つのコーパスが使用された。一つは「ビッグ・ツー(Big Two)」と呼ばれる心理学的軸で、個人の目標達成や能力に関連する「自己主導性(Agency)」と、他者との関係維持や愛に関連する「共同体性(Communion)」を測定するものである。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related