HESTIA: ヘシアン行列を活用した極低ビットLLM向け微分可能量子化トレーニング
大規模言語モデル(LLM)のメモリ消費を抑えるため、重みを{-1, 0, 1}の3値に圧縮する1.58ビット量子化が注目されていますが、従来の量子化手法では硬い丸め処理による勾配の不一致や、重みの更新が停滞する「デッドゾーン問題」が性能向上の大きな障壁となっていました。
TL;DR(結論)
大規模言語モデル(LLM)のメモリ消費を抑えるため、重みを{-1, 0, 1}の3値に圧縮する1.58ビット量子化が注目されていますが、従来の量子化手法では硬い丸め処理による勾配の不一致や、重みの更新が停滞する「デッドゾーン問題」が性能向上の大きな障壁となっていました。 本研究が提案する「HESTIA」は、非連続な量子化関数を温度制御されたSoftmax緩和に置き換えることで、学習初期に滑らかな勾配の流れを確保し、さらにヘシアン行列のトレースを用いて各テンソルの曲率に応じた適応的な離散化スケジュールを導入することで、情報の損失を最小限に抑えます。 Llama-3.2を用いた検証では、既存の3値量子化手法を大幅に上回る性能を記録し、1Bモデルで平均5.39%、3Bモデルで4.34%の精度向上を達成しており、1.58ビットという極限の圧縮環境下においても、フル精度モデルに極めて近い表現能力を回復できることが実証されました。
なぜこの問題か
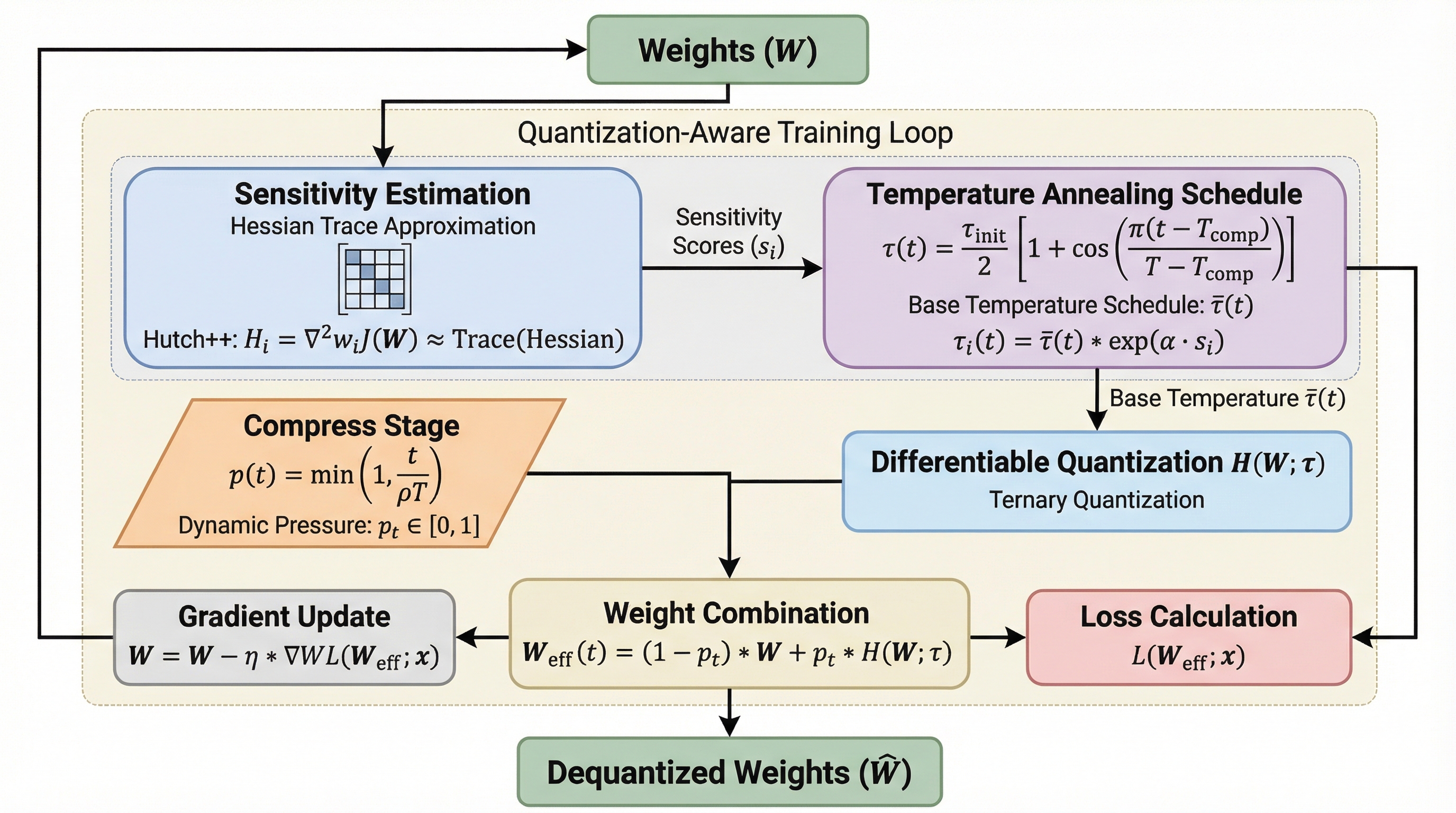
大規模言語モデル(LLM)のパラメータ数は増大の一途をたどっており、モデルの展開において「メモリの壁」と呼ばれる深刻なリソース制約が大きな課題となっています。この課題を解決するために、モデルのパラメータ精度を極限まで落とす量子化技術が不可欠となっており、特に重みを{-1, 0, 1}の3値で表現する1.58ビットアーキテクチャは、従来の複雑な積和演算(MAC)をエネルギー効率の高い整数加算に置き換えられるため、次世代の計算効率を実現する鍵として期待されています。しかし、このような極端な量子化は情報の損失が極めて大きく、標準的な学習後量子化(PTQ)ではモデルの性能が致命的に劣化するため、量子化を考慮したトレーニング(QAT)による最適化が必須となります。 従来のQAT手法の多くは、重みを離散化するために丸め処理やクリッピングを行い、その非連続な関数の勾配を近似するためにStraight-Through Estimator(STE)を利用しています。しかし、STEはフォワードパスでの離散的な信号とバックワードパスでの連続的な重み更新の間に根本的な不一致を生じさせます。…
核心:何を提案したのか
本研究では、極低ビットLLMの最適化におけるボトルネックを解消するための新しい微分可能な量子化フレームワーク「HESTIA」を提案しています。HESTIAの最大の特徴は、従来の硬いステップ関数による量子化を、温度パラメータによって制御されるSoftmax関数を用いた連続的な緩和(リラクゼーション)に置き換えた点にあります。この手法では、重みの3値状態への割り当てを離散集合上のソフトな期待値として定式化することで、潜在的な重み空間に対して全域で定義された滑らかな勾配を提供します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related