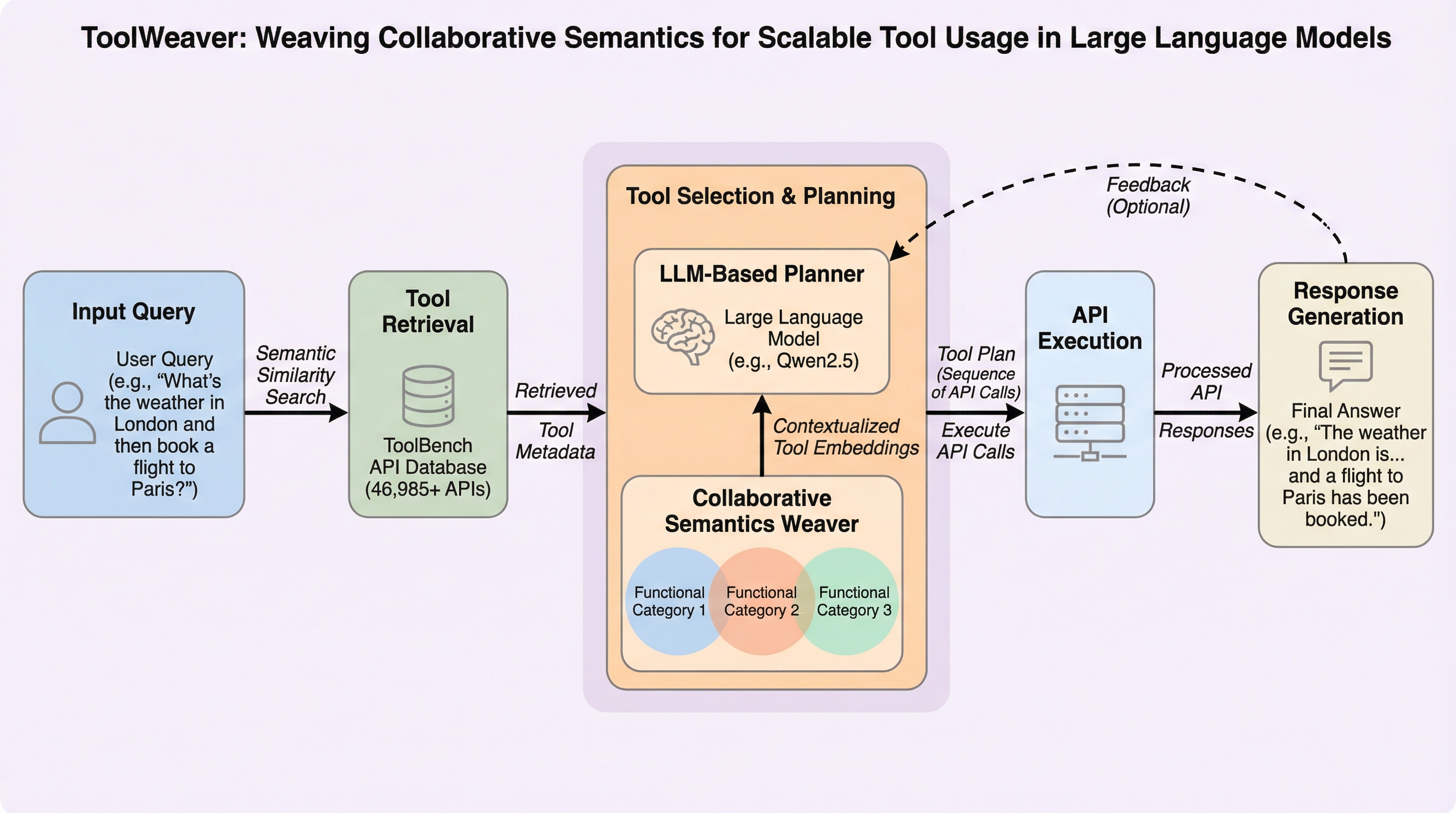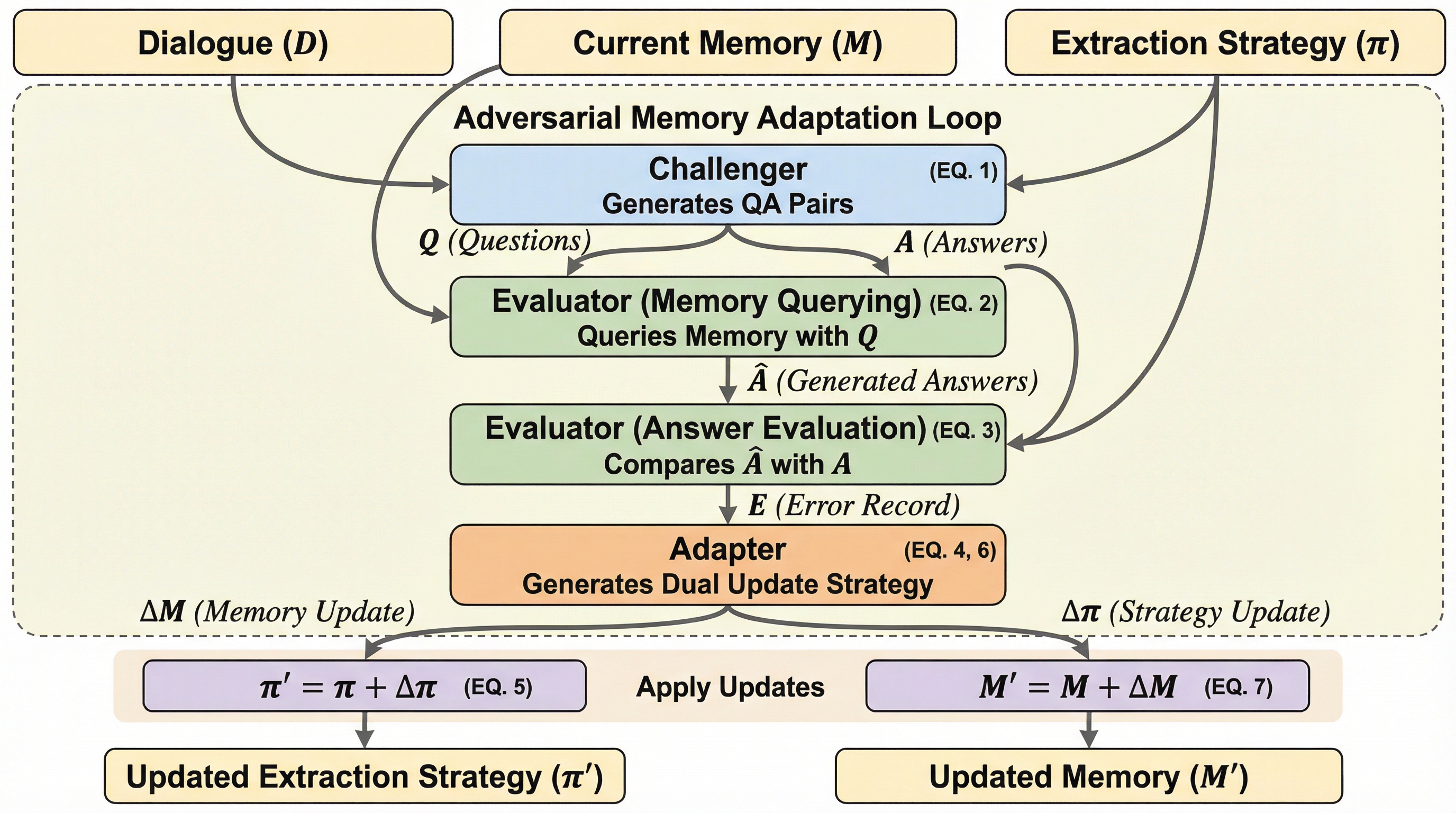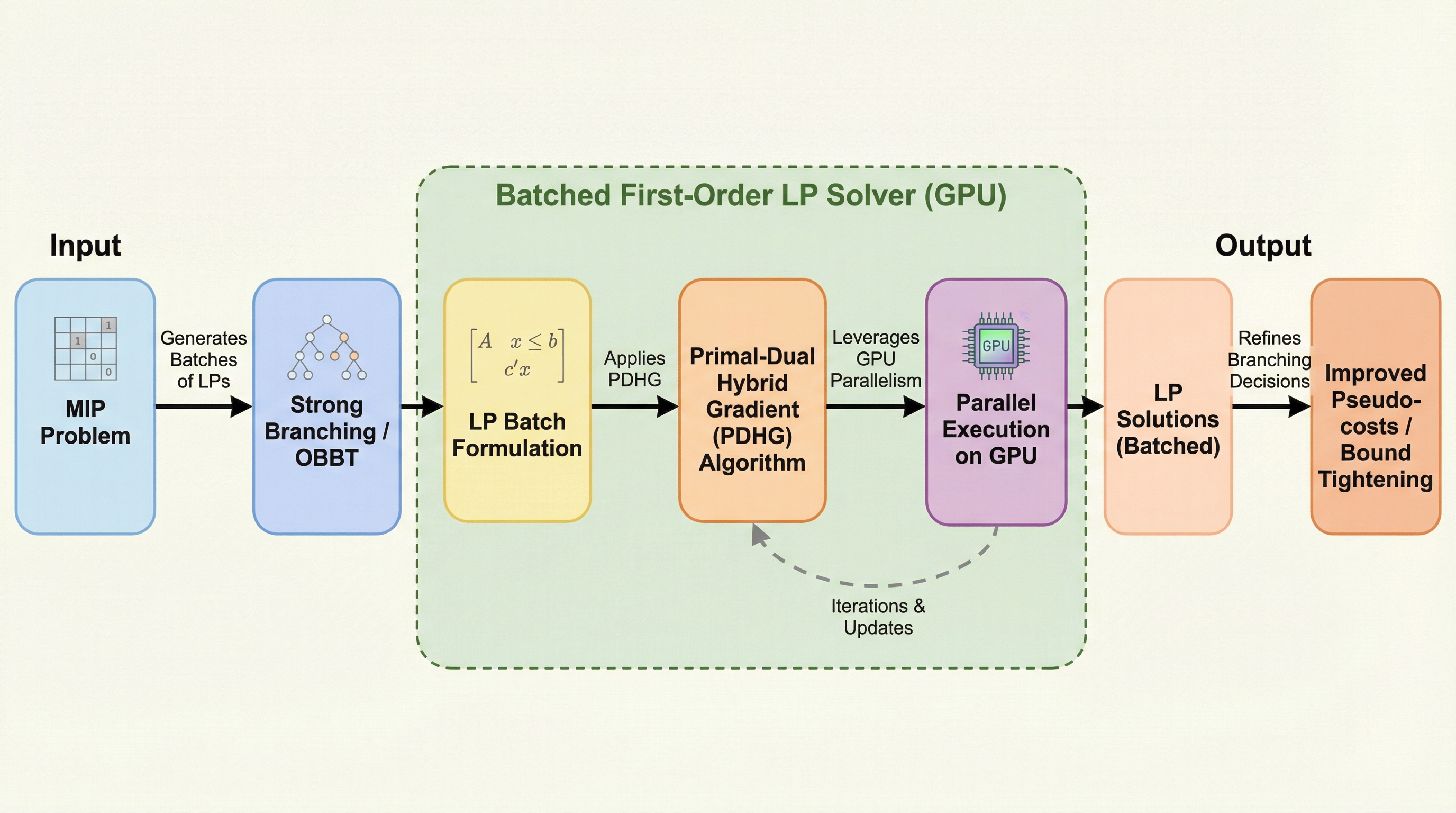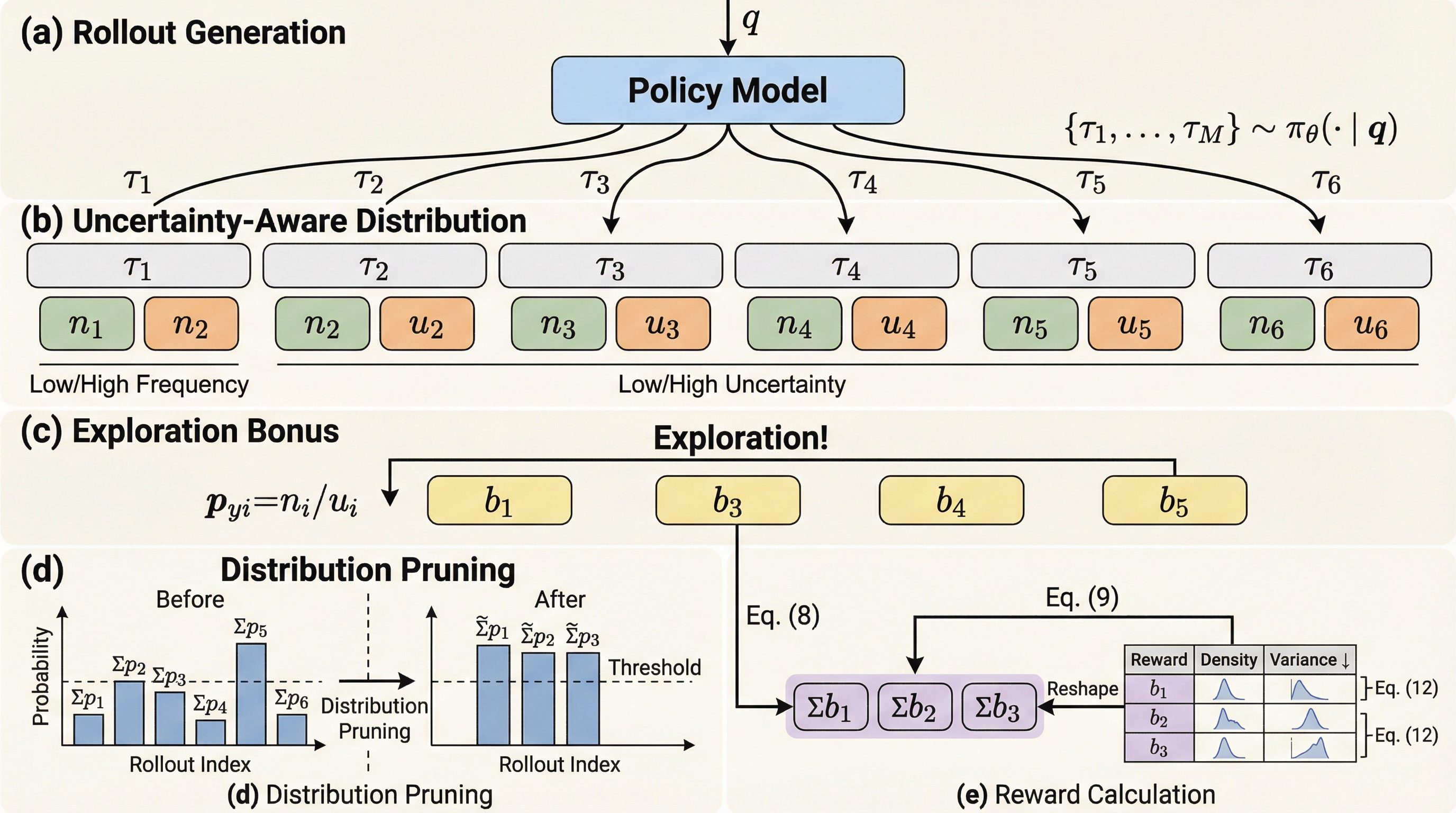
KID: 知識注入とデュアルヘッド学習による有害ミーム検出の最先端フレームワーク
インターネット上のミームは比喩や文化的背景に深く依存しており、従来のモデルでは表面的な情報の処理に留まり、潜在的な有害性を見逃す「知識と文脈の断絶」という課題がありました。本研究が提案するKIDフレームワークは、視覚的エンティティに背景知識を紐付ける「エンティティ・アンカー型知識注入」と、意味生成と分類を同時に最適化する「デュアルヘッド学習」により、複雑な推論を可能にします。英語、中国語、ベンガル語の5つのデータセットを用いた実験の結果、既存の最先端手法を2.1%から19.7%上回る性能を記録し、多言語や低リソースな環境においても極めて高い汎用性と堅牢性を示しました。