選好データからのノンパラメトリックなLLM評価手法「DMLEval」
従来のLLM評価はBradley-Terryモデルなどのパラメトリックな手法に依存しており、モデルの誤設定によるバイアスの発生や、複雑な機械学習モデルを用いた際の不確実性の定量化が困難であるという課題があった。
TL;DR(結論)
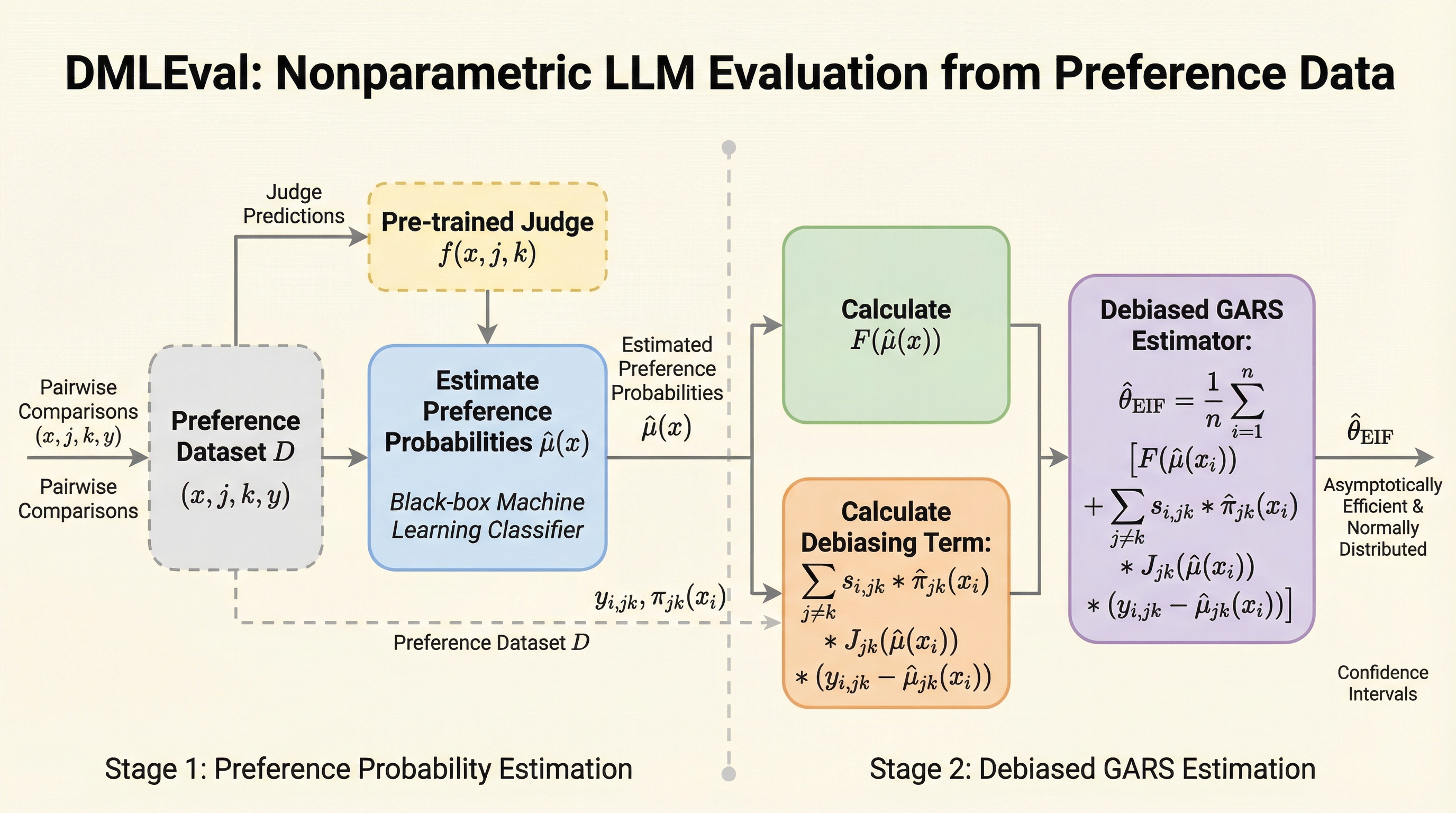
従来のLLM評価はBradley-Terryモデルなどのパラメトリックな手法に依存しており、モデルの誤設定によるバイアスの発生や、複雑な機械学習モデルを用いた際の不確実性の定量化が困難であるという課題があった。 本研究が提案する「DMLRANK」は、デバイアス機械学習(DML)を活用したノンパラメトリックな統計的枠組みであり、勝率やランク・セントラリティなどの多様な指標を統合した「一般化平均ランキングスコア(GARS)」を導入している。 この手法は、ブラックボックスな機械学習モデルやLLM-as-a-judgeとの組み合わせが可能であり、統計的に効率的な推定と妥当な信頼区間の算出を実現するとともに、予算制約下での最適なデータ収集方針を提示することで評価コストの削減にも寄与する。
なぜこの問題か
大規模言語モデル(LLM)の性能を評価し、信頼できるリーダーボードを作成するためには、人間による選好データの活用が不可欠である。一般的に、個別の出力に対して絶対的な品質スコアを割り当てるよりも、二つの回答を比較してどちらが優れているかを判断する方が、人間にとって単純で信頼性が高いとされる。このため、LM Arenaなどの主要なベンチマークでは一対比較データが広く利用されている。しかし、選好データは相対的な情報しか含んでいないため、そこから各モデルの絶対的なランキングスコアを推定するには、高度な統計的手法が必要となる。 現在、多くのリーダーボードではBradley-Terry(BT)モデルが採用されている。このモデルは、各モデルの根底にあるスコアがロジットスケールで選好確率を決定するというパラメトリックな仮定に基づいている。しかし、このアプローチにはいくつかの重大な限界が存在する。第一に、実際のデータ生成過程がBTモデルの仮定と一致しない場合、推定結果にバイアスが生じる可能性がある。例えば、選好関係に循環(サイクル)が含まれる場合、パラメトリックなモデルではその複雑さを十分に捉えきれない。…
核心:何を提案したのか
本論文では、上述の課題を解決するために「DMLRANK」と呼ばれるノンパラメトリックな統計的枠組みを提案している。この枠組みの核心は、ランキングの対象を文脈に応じた選好確率の関数として直接定義することにある。これにより、特定のパラメトリックなモデルの仮定に縛られることなく、多様なランキング指標を統一的に扱うことが可能となった。このアプローチは、モデルの誤設定によるバイアスを回避し、よりデータに忠実な評価を実現する。 具体的には、「一般化平均ランキングスコア(GARS)」という概念を導入している。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related