TBDFiltering: 階層的クラスタリングを用いた効率的な学習データ選別手法
大規模言語モデル(LLM)の学習データ選別において、全文書を高コストなLLMで評価するのは不可能ですが、本手法はテキスト埋め込みによる階層的クラスタリングを活用し、品質が均一なクラスタを適応的に特定することで評価回数を劇的に削減します。
TL;DR(結論)
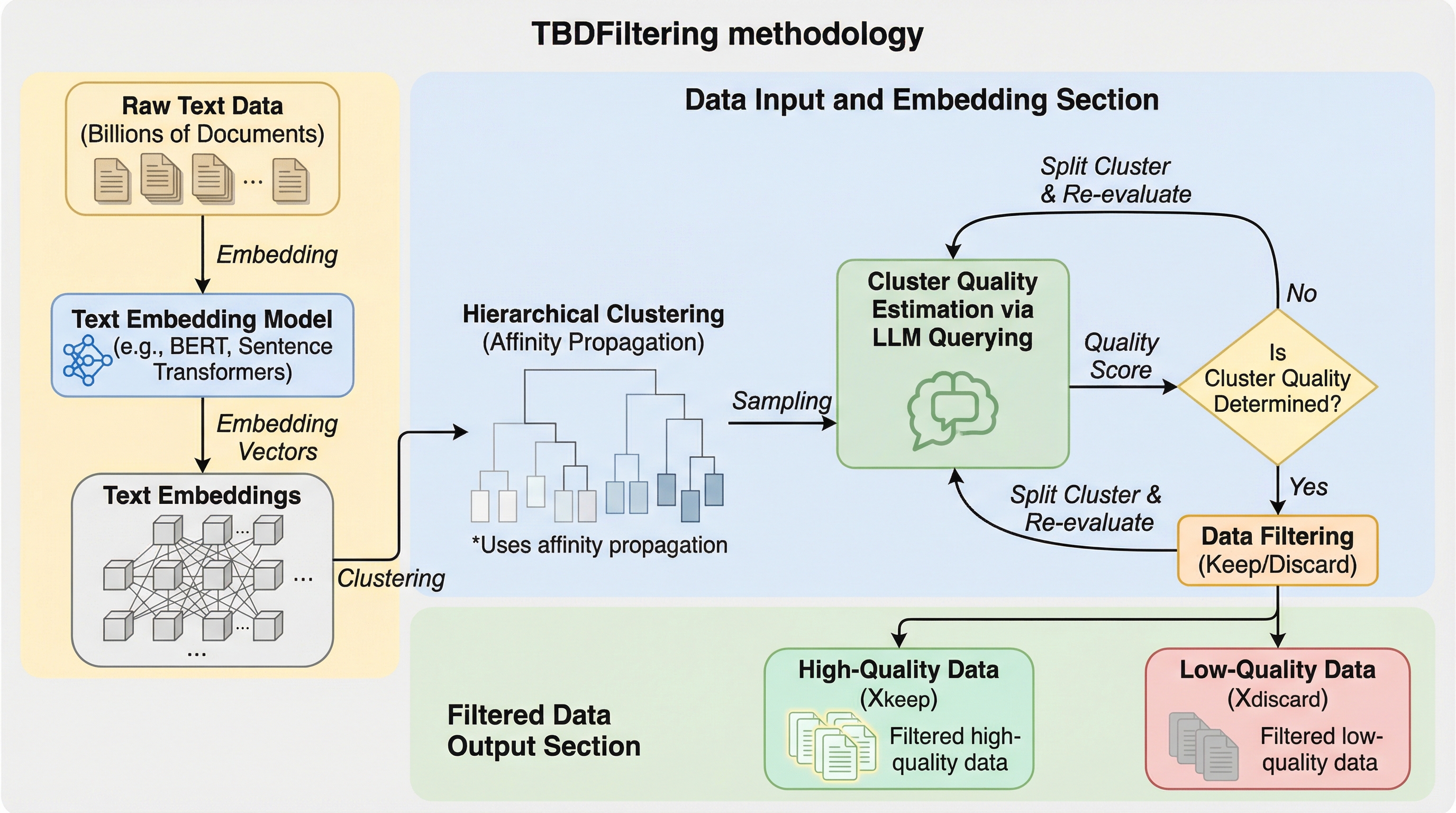
大規模言語モデル(LLM)の学習データ選別において、全文書を高コストなLLMで評価するのは不可能ですが、本手法はテキスト埋め込みによる階層的クラスタリングを活用し、品質が均一なクラスタを適応的に特定することで評価回数を劇的に削減します。 提案手法のTBDFilteringは、クラスタから少数のサンプルを抽出して品質を推定し、基準を満たしたノード以下の全データを一括で採用または棄却するアルゴリズムであり、理論的にクエリ効率の高さが証明されているだけでなく、ウェブ規模の膨大なデータセットに対しても高いスケーラビリティを備えています。 Gemma 3を用いた172Bトークンの学習実験では、ランダム抽出や既存の分類器ベースの手法と比較して、HellaSwagやMMLUなどの主要な8つのベンチマークで有意な性能向上を達成しており、高品質なデータセット構築における極めて有効なアプローチであることが示されました。
なぜこの問題か
機械学習モデルの品質は、その学習データの質に大きく依存します。特に大規模言語モデル(LLM)や基盤モデルにおいて、最もアクセスしやすく主要なデータソースはワールド・ワイド・ウェブですが、ここから得られるペタバイト級のデータはトピックや品質の面で本質的に多様すぎます。そのため、過学習を防ぐための重複削除、多様性を確保するためのトピック分類、そして正確性を担保するための品質フィルタリングが不可欠な工程となっています。しかし、処理すべきデータ量が数十億文書という膨大な規模であること、そして安価で信頼性の高い品質指標が不足していることが、このプロセスにおける最大の課題です。 歴史的に、データのフィルタリングはルールベースのヒューリスティックな手法で行われてきました。例えば、C4データセットでは言語識別や末尾の句読点の有無、n-gramを用いた重複削除などが適用されました。より最近のFineWebやDolmaといった大規模な取り組みでは、URLフィルタリングや有害コンテンツの除去、個人情報の特定など、多段階の複雑なパイプラインが採用されています。…
核心:何を提案したのか
本論文では、テキスト埋め込みに基づいた階層的クラスタリングを活用し、LLMによって評価すべき文書を適応的に選択する「TBDFiltering(Tree-Based Data Filtering)」という手法を提案しています。この手法の最大の特徴は、従来のパラメトリックな分類器モデルを学習させるアプローチとは異なり、クラスタリングに基づいたノンパラメトリックな手法である点にあります。具体的には、埋め込み空間における距離を用いてデータをクラスタリングし、各クラスタ内の文書品質を推定することで、高品質なクラスタに属する文書のみを効率的に抽出します。 この手法は、階層的クラスタリングの構造を利用することで、計算コストを大幅に削減します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related