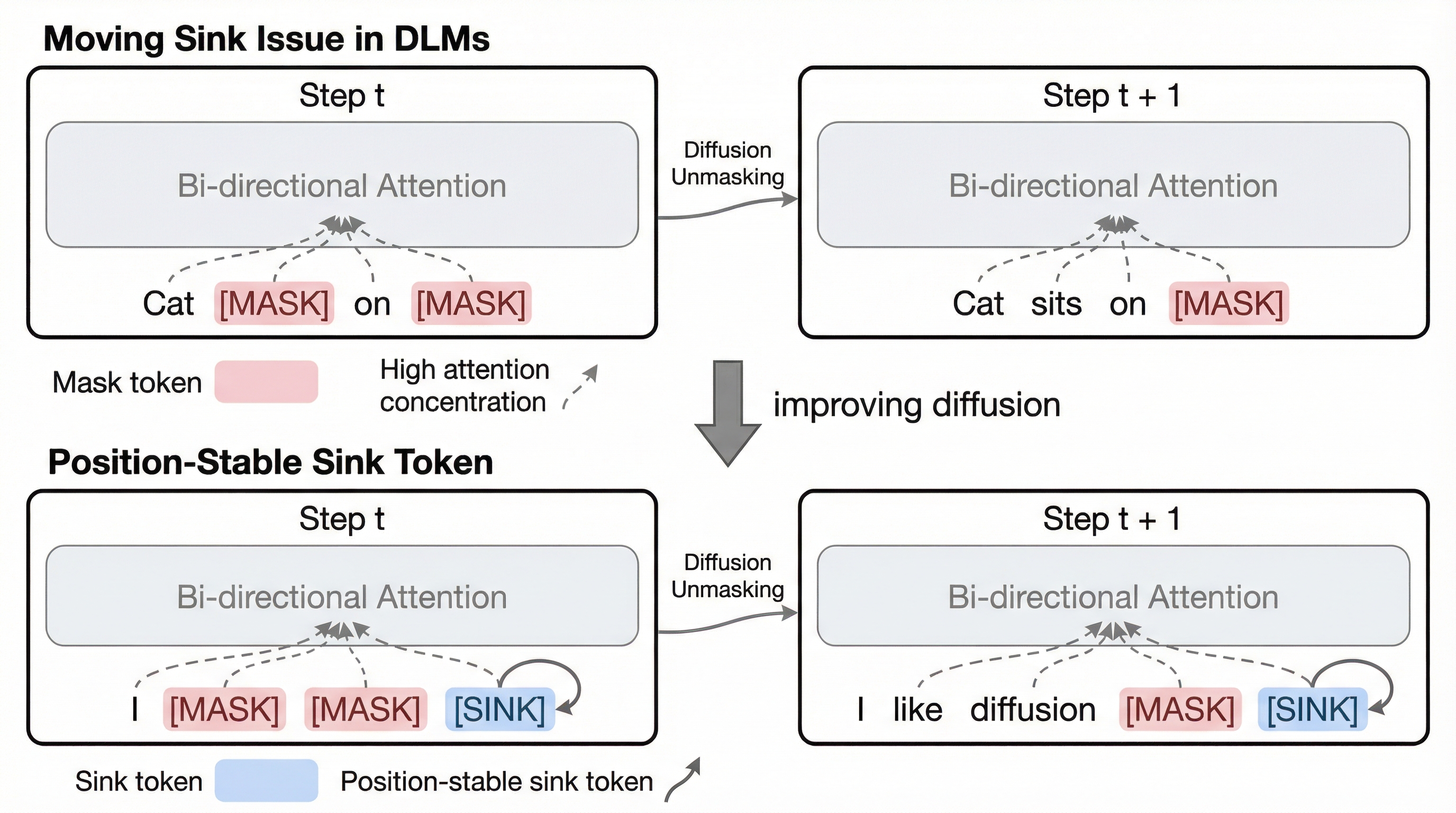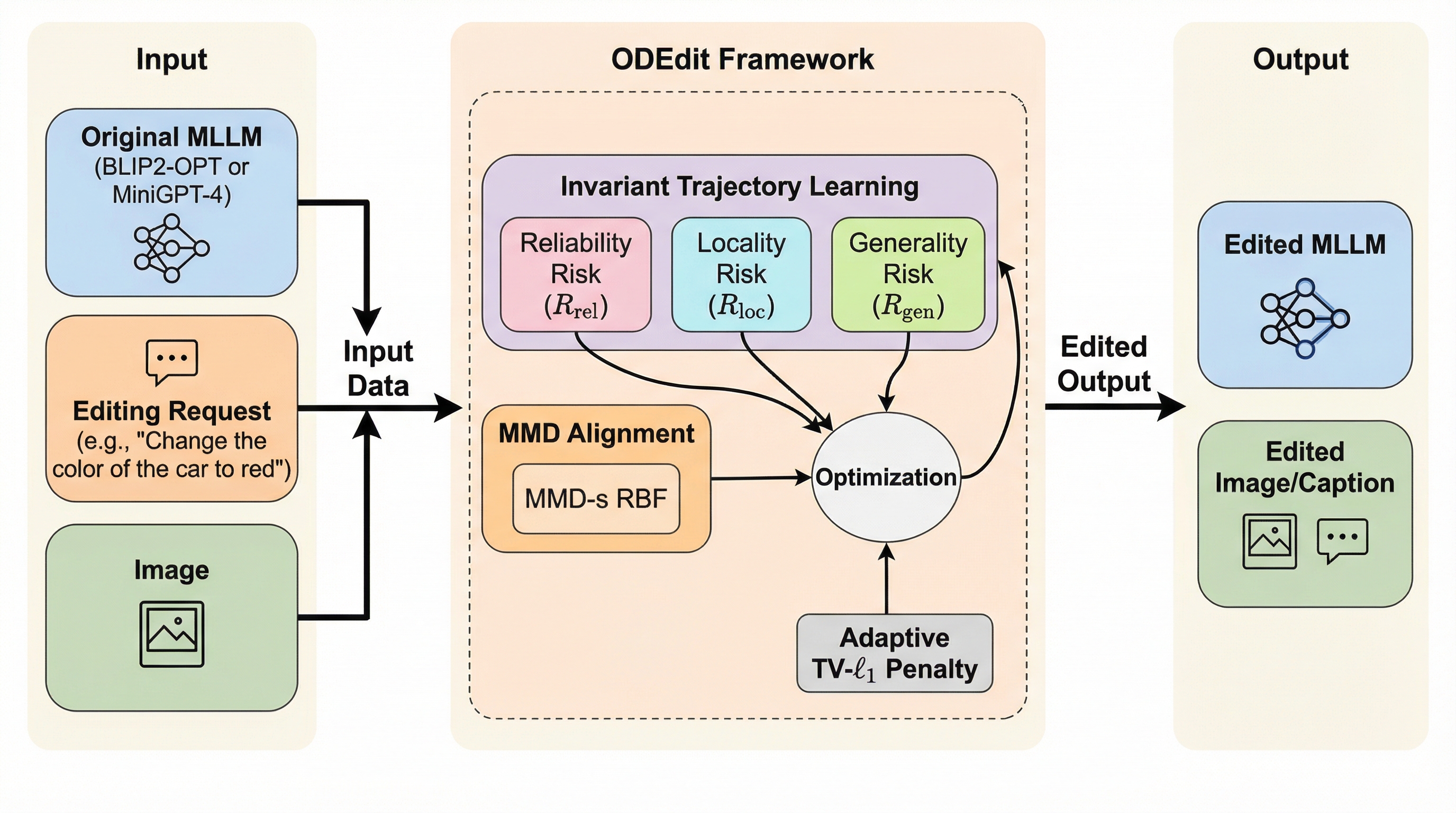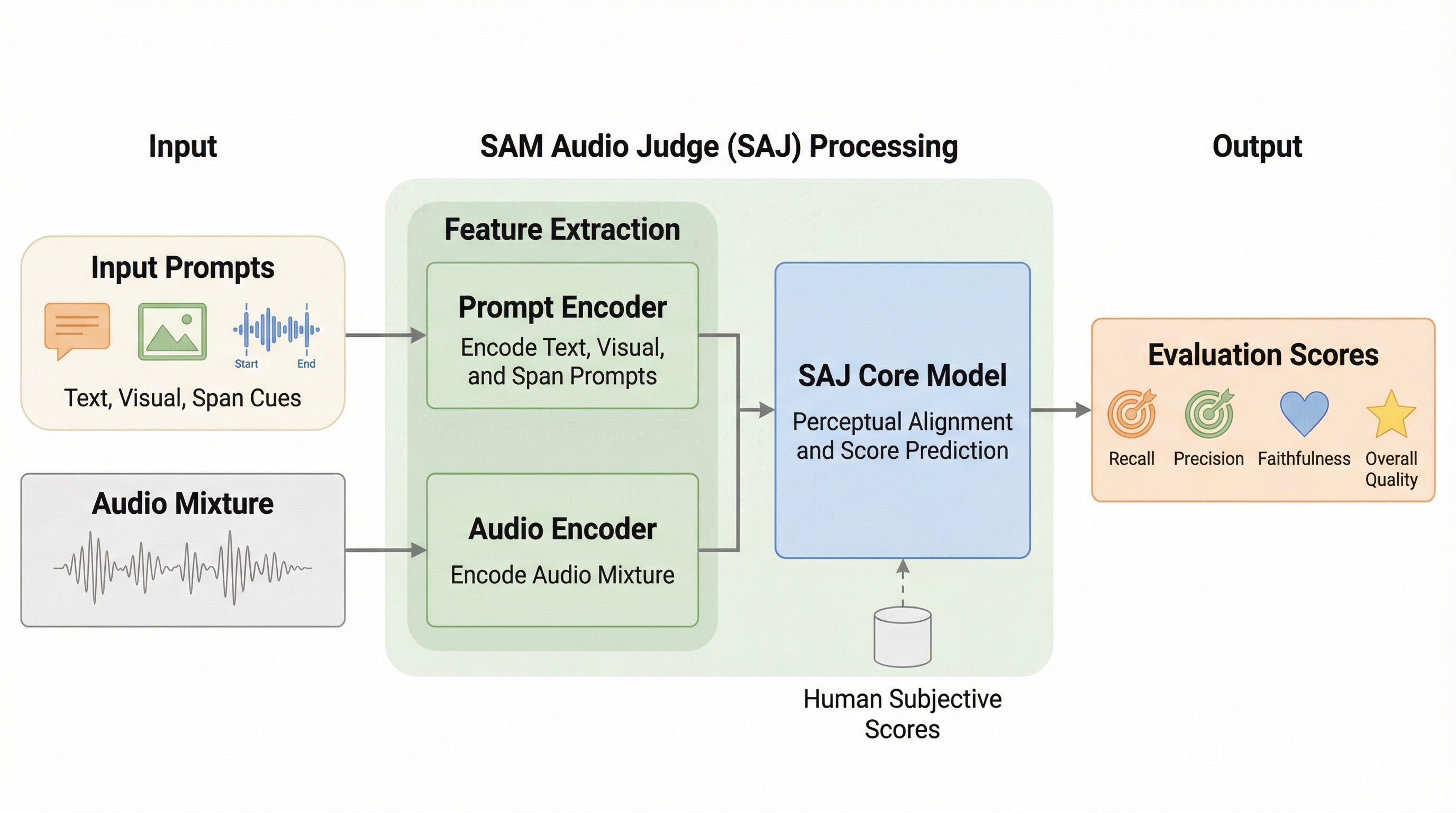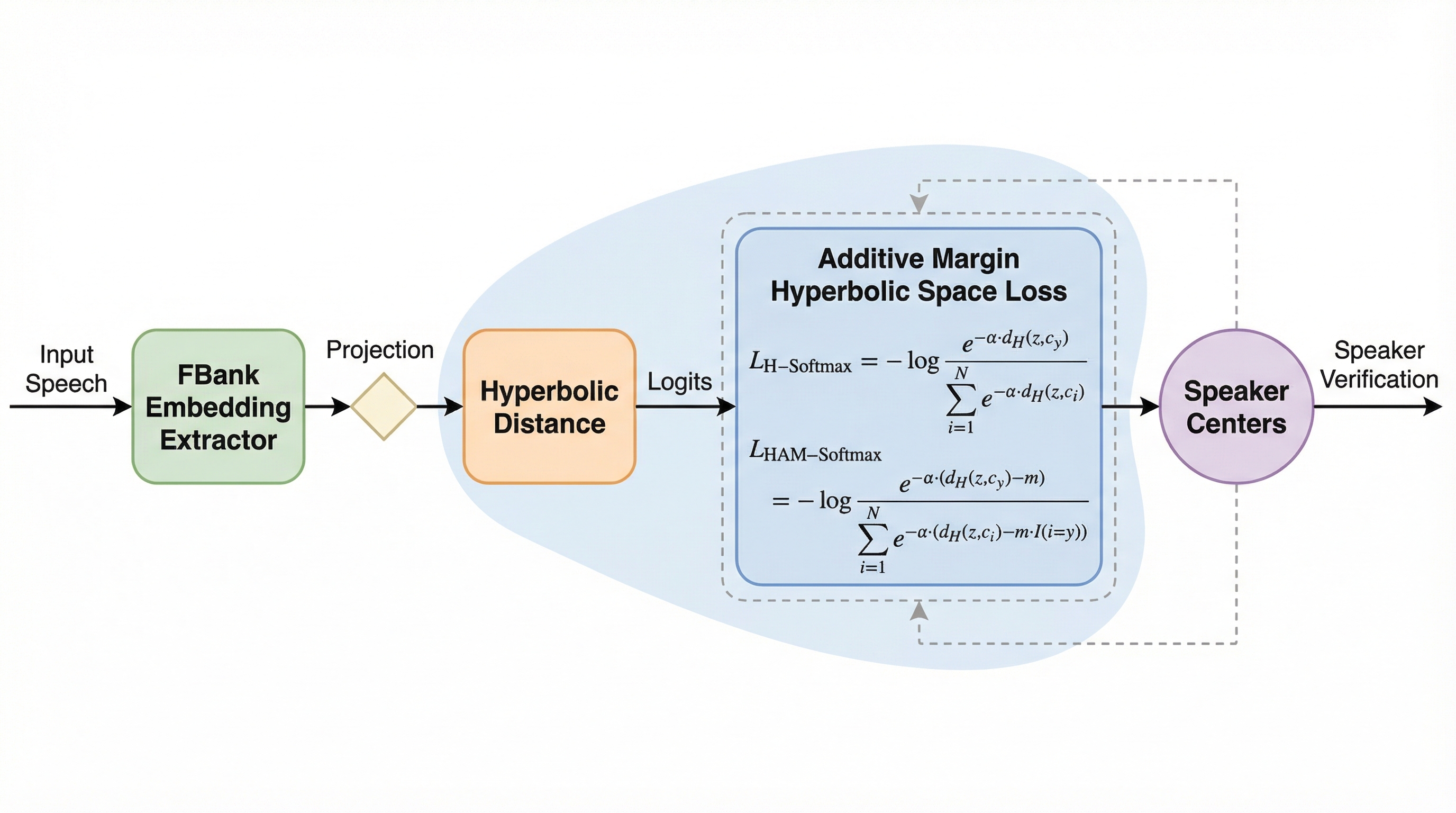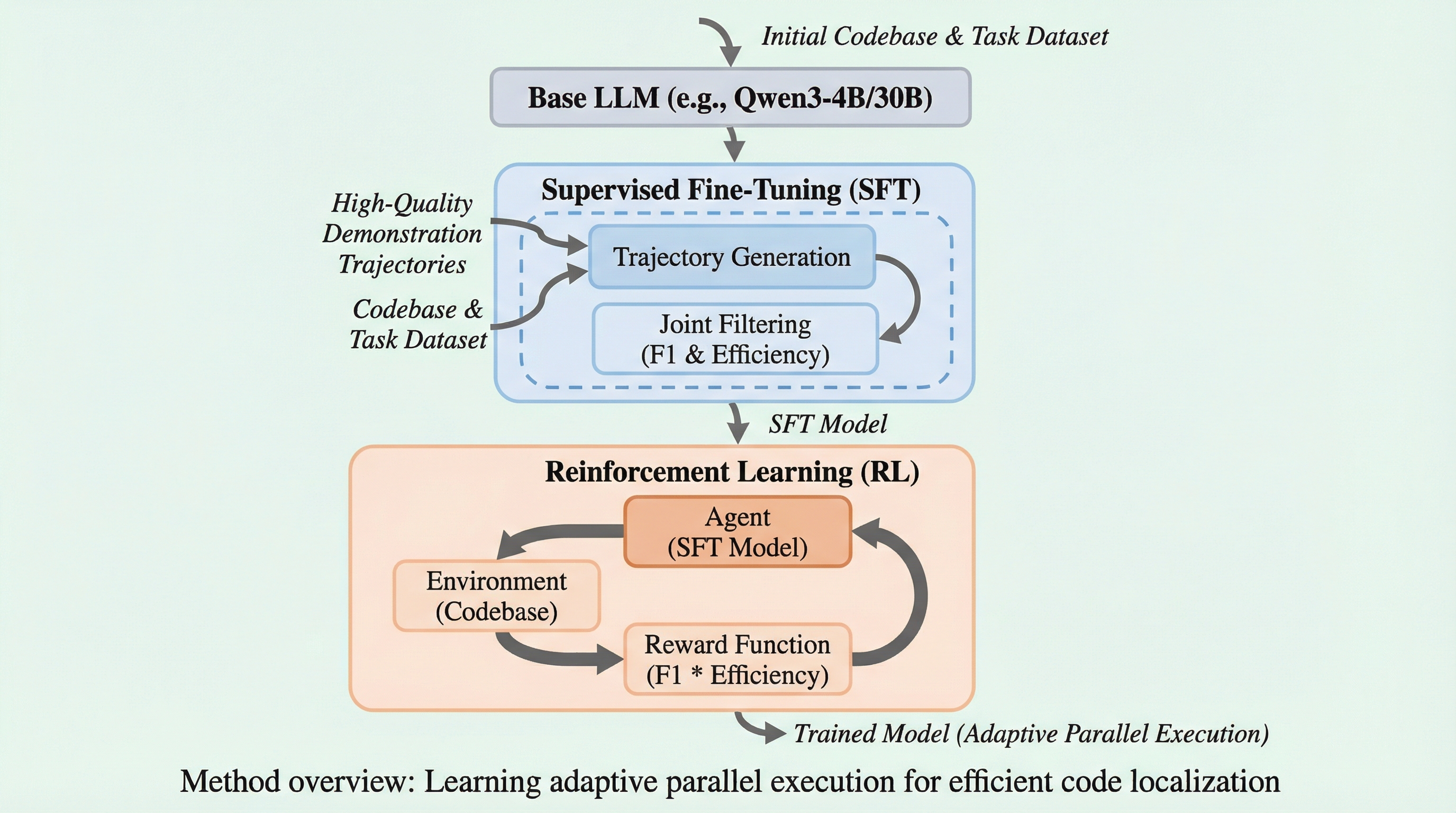
効率的なコード位置特定のための適応型並列実行の学習
ソフトウェア開発の自動化において、修正箇所を特定するコード位置特定は計算リソースの半分以上を消費する大きなボトルネックです。従来手法は逐次実行による情報不足や、固定的な並列化による34.9%もの冗長な呼び出しという課題を抱えていましたが、本研究の「FuseSearch」は情報の新規性と呼び出し回数の比率を「ツール効率」として定義し、適応的な並列実行戦略を学習しました。 検証の結果、4Bパラメータの小型モデルでありながらSWE-bench VerifiedでファイルレベルF1スコア84.7%を達成し、実行時間を93.6%、消費トークン量を68.9%削減するという、圧倒的な品質とコストパフォーマンスの両立を実現しています。 この手法は、情報の新規性を常に監視しながら並列度を動的に調整することで、冗長な信号を排除し、最終的な位置特定の精度を向上させるという相乗効果をもたらしており、実用的な自動開発エージェントの構築に向けた新たな標準を提示しています。