方策事前分布を用いた安全な探索
強化学習エージェントが実世界で学習する際、壊滅的な失敗を避けるための「安全な探索」が不可欠であり、本研究ではオフラインデータやシミュレータから得られる不完全だが保守的な「方策事前分布」を活用する新しいアルゴリズムであるSOOPERを提案した。
TL;DR(結論)
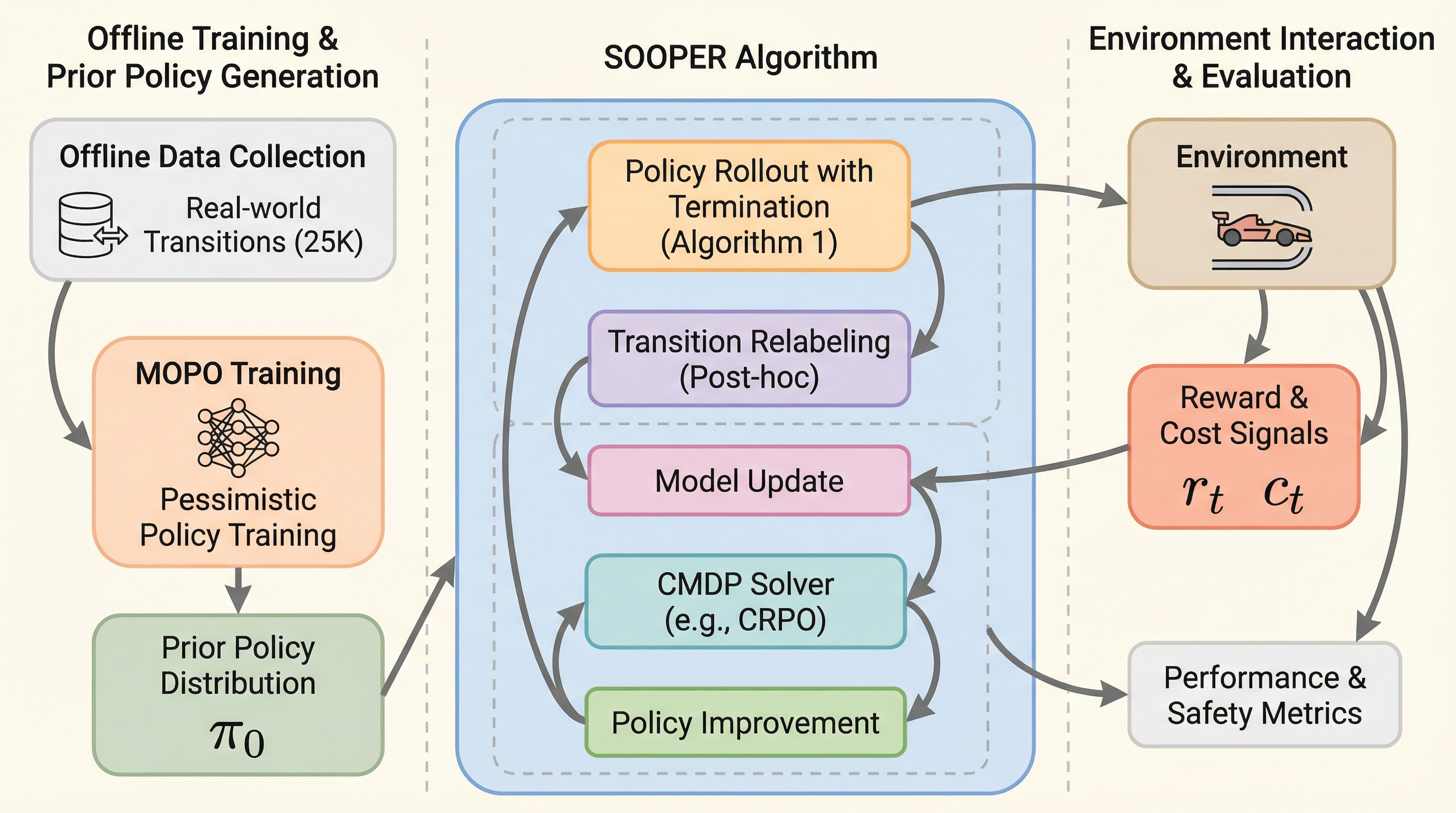
強化学習エージェントが実世界で学習する際、壊滅的な失敗を避けるための「安全な探索」が不可欠であり、本研究ではオフラインデータやシミュレータから得られる不完全だが保守的な「方策事前分布」を活用する新しいアルゴリズムであるSOOPERを提案した。 SOOPERは確率的なダイナミクスモデルを用い、現在の行動が安全予算を超えると予測された場合にのみ保守的な事前方策へと悲観的に切り替える仕組みを持ち、制約付きマルコフ決定過程を終了条件付きの制約なし問題へと再定式化することで、標準的な深層強化学習手法との互換性を保ちつつ累積リグレットの上限を証明した。 実験ではRWRLやSafetyGymといったベンチマークにおいて既存の最先端手法を安全性と性能の両面で大幅に上回り、さらに実際のハードウェアを用いたオンライン学習においても、シミュレーションと現実のギャップが存在する中で安全制約を破ることなく未知の環境に適応できる有効性が確認された。
なぜこの問題か
知性の本質的な定義の一つは、オンラインで得られる情報のストリームを継続的に利用し、時間をかけて学習し適応する能力である。強化学習(RL)は、教師なしでオンライン学習を行うための強力な枠組みを提供し、これまで多くの実世界アプリケーションを牽引してきた。しかし、物理世界において強化学習を本格的に解禁するためには、安全性の確保が極めて重要な鍵となる。強化学習エージェントは、環境に関する完全な知識を欠いている学習の初期段階であっても、壊滅的な結果を招くような行動をとるリスクを冒すことは許されない。したがって、エージェントは安全に探索を行い、タスクを解決するための新しい安全な行動を、リスクを最小限に抑えながら徐々に発見していく必要がある。 実用上の大きな課題として、理論的な安全保証と実用的なスケーラビリティの両立が挙げられる。これまでの研究において、厳密な理論的安全性を持つ手法は、複雑で汎用的なタスクへのスケールアップが困難な場合が多かった。一方で、深層学習などを活用したスケーラビリティを重視する手法は、学習中の安全性を確実に維持することに失敗するのが一般的である。…
核心:何を提案したのか
本研究では、SOOPER(Safe Online Optimism for Pessimistic Expansion in RL)と呼ばれる、モデルベースの強化学習アルゴリズムを提案した。SOOPERは、連続的な状態空間および行動空間における安全な探索のためのスケーラブルな手法であり、少量のオフラインデータや、現実とは異なる設定のシミュレーションで訓練された不完全な方策を「安全な事前分布(セーフ・プライア)」として最大限に活用する。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related