効率的なコード位置特定のための適応型並列実行の学習
ソフトウェア開発の自動化において、修正箇所を特定するコード位置特定は計算リソースの半分以上を消費する大きなボトルネックです。従来手法は逐次実行による情報不足や、固定的な並列化による34.9%もの冗長な呼び出しという課題を抱えていましたが、本研究の「FuseSearch」は情報の新規性と呼び出し回数の比率を「ツール効率」として定義し、適応的な並列実行戦略を学習しました。 検証の結果、4Bパラメータの小型モデルでありながらSWE-bench VerifiedでファイルレベルF1スコア84.7%を達成し、実行時間を93.6%、消費トークン量を68.9%削減するという、圧倒的な品質とコストパフォーマンスの両立を実現しています。 この手法は、情報の新規性を常に監視しながら並列度を動的に調整することで、冗長な信号を排除し、最終的な位置特定の精度を向上させるという相乗効果をもたらしており、実用的な自動開発エージェントの構築に向けた新たな標準を提示しています。
TL;DR(結論)
ソフトウェア開発の自動化において、修正箇所を特定するコード位置特定は計算リソースの半分以上を消費する大きなボトルネックです。従来手法は逐次実行による情報不足や、固定的な並列化による34.9%もの冗長な呼び出しという課題を抱えていましたが、本研究の「FuseSearch」は情報の新規性と呼び出し回数の比率を「ツール効率」として定義し、適応的な並列実行戦略を学習しました。 検証の結果、4Bパラメータの小型モデルでありながらSWE-bench VerifiedでファイルレベルF1スコア84.7%を達成し、実行時間を93.6%、消費トークン量を68.9%削減するという、圧倒的な品質とコストパフォーマンスの両立を実現しています。 この手法は、情報の新規性を常に監視しながら並列度を動的に調整することで、冗長な信号を排除し、最終的な位置特定の精度を向上させるという相乗効果をもたらしており、実用的な自動開発エージェントの構築に向けた新たな標準を提示しています。
なぜこの問題か
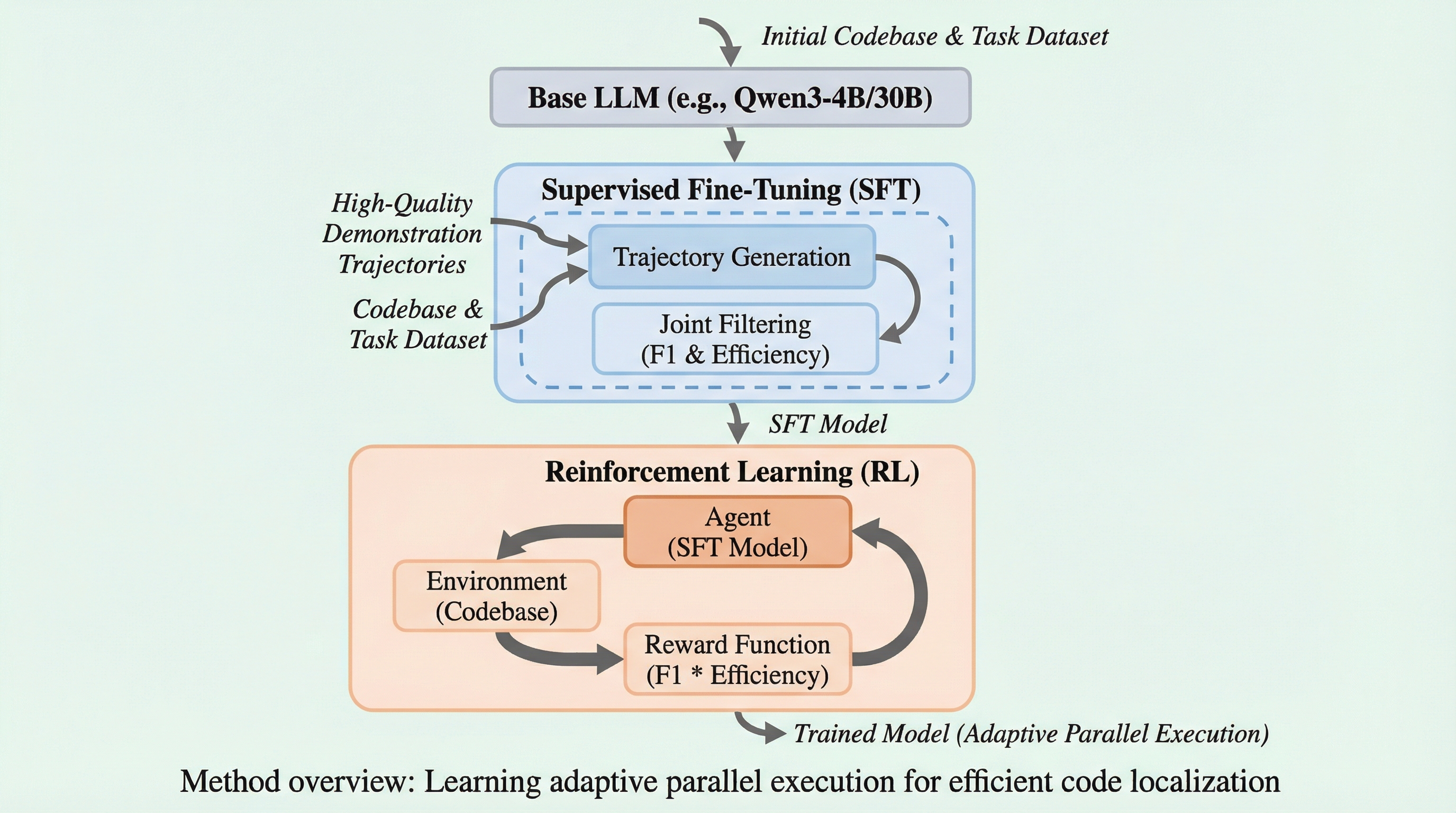
現代のソフトウェア開発プロセスにおいて、バグの修正や新機能の実装を行う際に、膨大なコードベースの中から修正が必要な具体的なファイルや関数を特定する「コード位置特定」は、自動化パイプライン全体の効率を左右する極めて重要な工程です。しかし、最新のエージェントを用いた調査によれば、この位置特定タスクだけで計算リソースの50%以上が費やされており、開発サイクル全体の大きなボトルネックとなっているのが現状です。従来のエージェントは、コードの検索や解析ツールを1ターンに1つずつ実行する逐次的な対話パラダイムに依存してきましたが、ここには深刻なトレードオフが存在します。実用的な開発環境では、計算コストや応答時間の制約からエージェントに許容される対話ターン数には厳しい制限が課されますが、少ないターン数では十分な文脈情報を収集できずに精度が著しく低下する「情報飢餓」という現象が発生してしまいます。 この問題を解決するために、1ターンに複数のツールを同時に実行する並列化が検討されてきましたが、単に固定された数のツールを呼び出すだけの手法では、全呼び出しの34.9%が既に取得済みの情報を繰り返すだけの冗長なものになることが判明しました。…
核心:何を提案したのか
本論文では、並列コード位置特定を単なるツールの同時実行ではなく、「品質と効率の共同最適化タスク」として再定義した革新的なエージェント「FuseSearch」を提案しています。FuseSearchの核心的なアイデアは、固定された並列度を用いるのではなく、探索の進捗やタスクの文脈に応じて並列実行の幅を動的に調整する「適応型並列実行」を学習によって獲得させることにあります。この学習を実現するために、本研究では新たに「ツール効率」という独自の指標を導入しました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related