R^3:LLM強化学習のためのリプレイ、リフレクション、およびランキング報酬
大規模言語モデルの強化学習において、グループ内の回答がすべて正解または不正解になり学習信号が消失する「アドバンテージの崩壊」を解決するため、過去の履歴を活用するリプレイ(CCR)、自己反省を促すリフレクション(ISR)、未完の回答をエントロピーで評価するランキング報酬(SERR)を組み合わせた新手法「R³」を提案しました。 この手法をDeepSeek-R1-Distill-Qwen-1.5Bに適用した結果、数学ベンチマークにおいて従来の1.5Bモデルを大幅に上回るだけでなく、パラメータ数が数倍大きい7B規模の既存モデルをも凌駕する性能を達成し、より少ない推論トークン数で効率的に正解に到達できることが実証されました。 具体的には、数学の難問セットであるAIME24において、ベースモデルの28.12から47.50へとスコアをほぼ倍増させ、さらに学習プロセスにおいて人間によるプロセス報酬の注釈を必要としない教師なしの報酬設計を実現することで、計算リソースの効率化と推論能力の深化を両立させています。
TL;DR(結論)
大規模言語モデルの強化学習において、グループ内の回答がすべて正解または不正解になり学習信号が消失する「アドバンテージの崩壊」を解決するため、過去の履歴を活用するリプレイ(CCR)、自己反省を促すリフレクション(ISR)、未完の回答をエントロピーで評価するランキング報酬(SERR)を組み合わせた新手法「R³」を提案しました。 この手法をDeepSeek-R1-Distill-Qwen-1.5Bに適用した結果、数学ベンチマークにおいて従来の1.5Bモデルを大幅に上回るだけでなく、パラメータ数が数倍大きい7B規模の既存モデルをも凌駕する性能を達成し、より少ない推論トークン数で効率的に正解に到達できることが実証されました。 具体的には、数学の難問セットであるAIME24において、ベースモデルの28.12から47.50へとスコアをほぼ倍増させ、さらに学習プロセスにおいて人間によるプロセス報酬の注釈を必要としない教師なしの報酬設計を実現することで、計算リソースの効率化と推論能力の深化を両立させています。
なぜこの問題か
大規模言語モデル(LLM)に複雑な推論能力を習得させる手法として、DeepSeek-R1などで採用されているGRPO(Group Relative Policy Optimization)が注目を集めています。GRPOは、同一の質問から生成された複数の回答(グループ)内での相対的な報酬の差を利用してモデルを更新するため、従来の強化学習で必要だった複雑な価値モデルを省略できるという利点があります。しかし、この手法には「アドバンテージの崩壊」という致命的な弱点が存在します。これは、グループ内のすべての回答が「すべて正解」あるいは「すべて不正解」になってしまった場合、報酬の分散がゼロになり、モデルがどの方向に学習を進めるべきかという信号(アドバンテージ)が得られなくなる現象です。 特に数学や論理パズルのような難易度の高いタスクでは、モデルの学習が不十分な初期段階において、生成されるすべての回答が不正解になることが頻繁に起こります。このような状況では、モデルは何を改善すべきかの指針を失い、学習プロセスが停滞してしまいます。…
核心:何を提案したのか
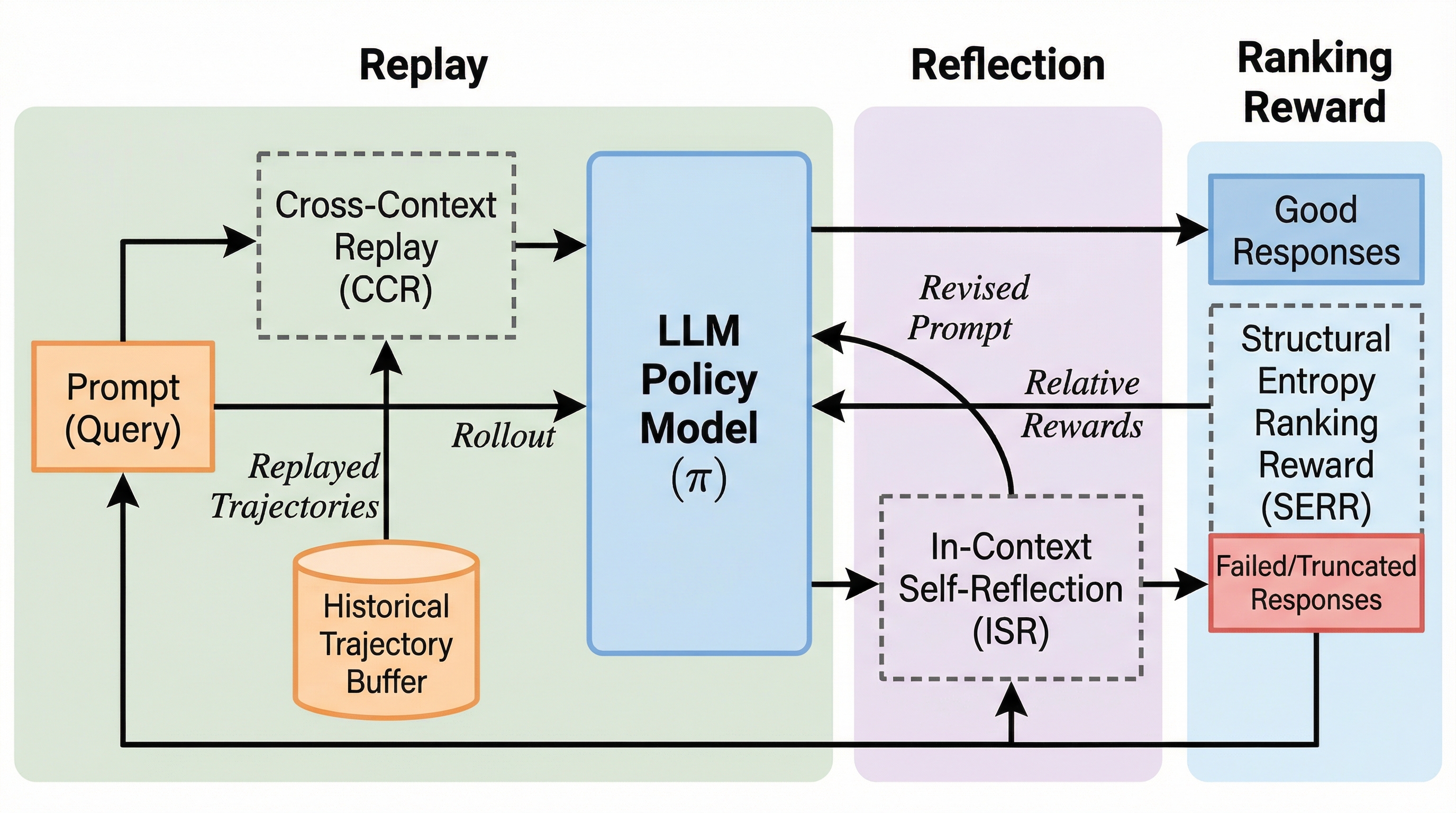
本研究では、上述の課題を根本から解決するために「R³(Replay, Reflection, and Ranking Rewards)」と呼ばれる新しい強化学習フレームワークを提案しました。このフレームワークは、外部からの介入と内部的な自己最適化を組み合わせることで、アドバンテージの崩壊を防ぎ、学習効率を劇的に向上させることを目的としています。R³は、以下の3つの主要なコンポーネントで構成されています。 第一の柱は、クロスコンテキスト・リプレイ(CCR)です。これは学習中に生成された過去の回答とその報酬を保存しておく「サンプルバッファ」を活用する戦略です。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related