最大36倍の高速化:MLLMにおけるキー情報抽出のためのマスクベース並列推論パラダイム
視覚的に豊かな文書(VrD)からのキー情報抽出(KIE)において、従来のマルチモーダル大規模言語モデル(MLLM)が抱えていた自己回帰的な逐次トークン生成による推論速度のボトルネックを解消するため、ターゲットとなる値を「[mask]」トークンで置き換えて一括生成する並列推論パラダイム「PIP」が提案されました。
TL;DR(結論)
視覚的に豊かな文書(VrD)からのキー情報抽出(KIE)において、従来のマルチモーダル大規模言語モデル(MLLM)が抱えていた自己回帰的な逐次トークン生成による推論速度のボトルネックを解消するため、ターゲットとなる値を「[mask]」トークンで置き換えて一括生成する並列推論パラダイム「PIP」が提案されました。 この手法では、双方向アテンションを活用したマスク事前学習と、大規模な構造化データセットを用いた教師あり微調整を組み合わせることで、モデルが文書内の各領域に独立して注目し、単一のフォワードパスで全ての情報を同時に抽出することを可能にしています。 実験の結果、PIPは従来の自己回帰モデルと比較して、性能の低下を最小限に抑えながら5倍から最大36倍という劇的な推論速度の向上を達成し、SROIEやCORDといった主要なベンチマークにおいて新たな最先端(SOTA)の精度を記録するなど、実用的な大規模文書処理への道を切り拓きました。
なぜこの問題か
請求書やフォーム、領収書といった視覚的に豊かな文書(VrD)から、名前、日付、金額などの重要な情報を抽出して構造化するキー情報抽出(KIE)は、ビジネスの自動化において極めて重要なタスクです。近年、大規模言語モデル(LLM)やマルチモーダル大規模言語モデル(MLLM)の発展により、これらのタスクの精度は飛躍的に向上しました。しかし、既存のモデルの多くは「自己回帰的推論」という仕組みに依存しています。これは、次の単語を予測するために直前の単語を順番に生成していく方式であり、生成するトークン数が増えるほど処理時間が長くなるという本質的な課題を抱えています。 特にKIEタスクにおいては、抽出対象となる複数のフィールド(例えば「商品名」と「価格」)は、意味的に互いに独立していることが多いという特徴があります。それにもかかわらず、従来のモデルはこれらを一つずつ順番に生成しなければならず、これがリアルタイム処理や大規模な文書処理における大きな効率性の障壁となっていました。…
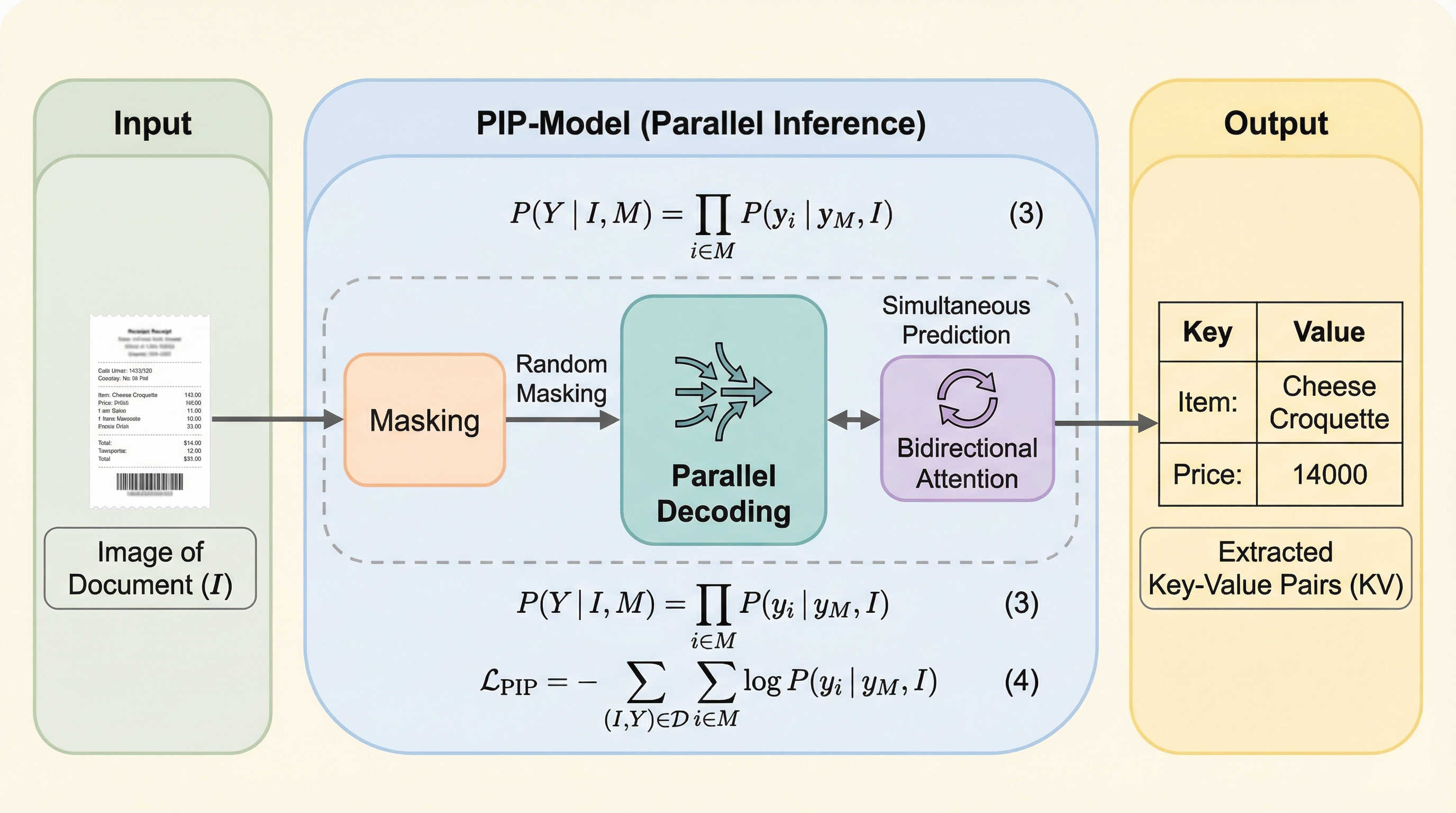
核心:何を提案したのか
本研究では、KIEのためのシンプルかつ効果的な並列推論パラダイムである「PIP(Parallel Inference Paradigm)」を提案しました。PIPの最大の特徴は、従来の自己回帰的な生成プロセスを、マスクされた位置を同時に予測する並列的なプロセスへと再定式化した点にあります。具体的には、プロンプト内のターゲットとなる値の部分を「[mask]」トークンというプレースホルダーで置き換えます。例えば、「価格:[mask][mask]」のように入力することで、モデルはこれらのマスクされた位置にあるべき文字や数値を、一度の計算(フォワードパス)で全て同時に導き出すことができます。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related