GMS-CAVP:マルチスケールの対照学習および生成的事前学習による視聴覚対応の改善
GMS-CAVPは、映像と音声の間の意味的・時間的な対応関係を高度にモデル化するため、マルチスケールでの対照学習と拡散モデルベースの生成学習を統合した新しい視聴覚事前学習フレームワークである。 従来の単一スケールによるグローバルな整列の限界を克服するため、階層的な空間・時間構造を捉える「マルチスケール空間・時間整列(MSA)」と、モダリティ間の翻訳能力を高める「マルチスケール空間・時間拡散(MSD)」を導入している。 VGGSound、AudioSet、Panda70Mを用いた大規模な実験において、映像からの音声生成および双方向検索の双方で従来手法を大幅に上回る世界最高水準の性能を達成し、高い同期性と音響品質を証明した。
TL;DR(結論)
GMS-CAVPは、映像と音声の間の意味的・時間的な対応関係を高度にモデル化するため、マルチスケールでの対照学習と拡散モデルベースの生成学習を統合した新しい視聴覚事前学習フレームワークである。 従来の単一スケールによるグローバルな整列の限界を克服するため、階層的な空間・時間構造を捉える「マルチスケール空間・時間整列(MSA)」と、モダリティ間の翻訳能力を高める「マルチスケール空間・時間拡散(MSD)」を導入している。 VGGSound、AudioSet、Panda70Mを用いた大規模な実験において、映像からの音声生成および双方向検索の双方で従来手法を大幅に上回る世界最高水準の性能を達成し、高い同期性と音響品質を証明した。
なぜこの問題か
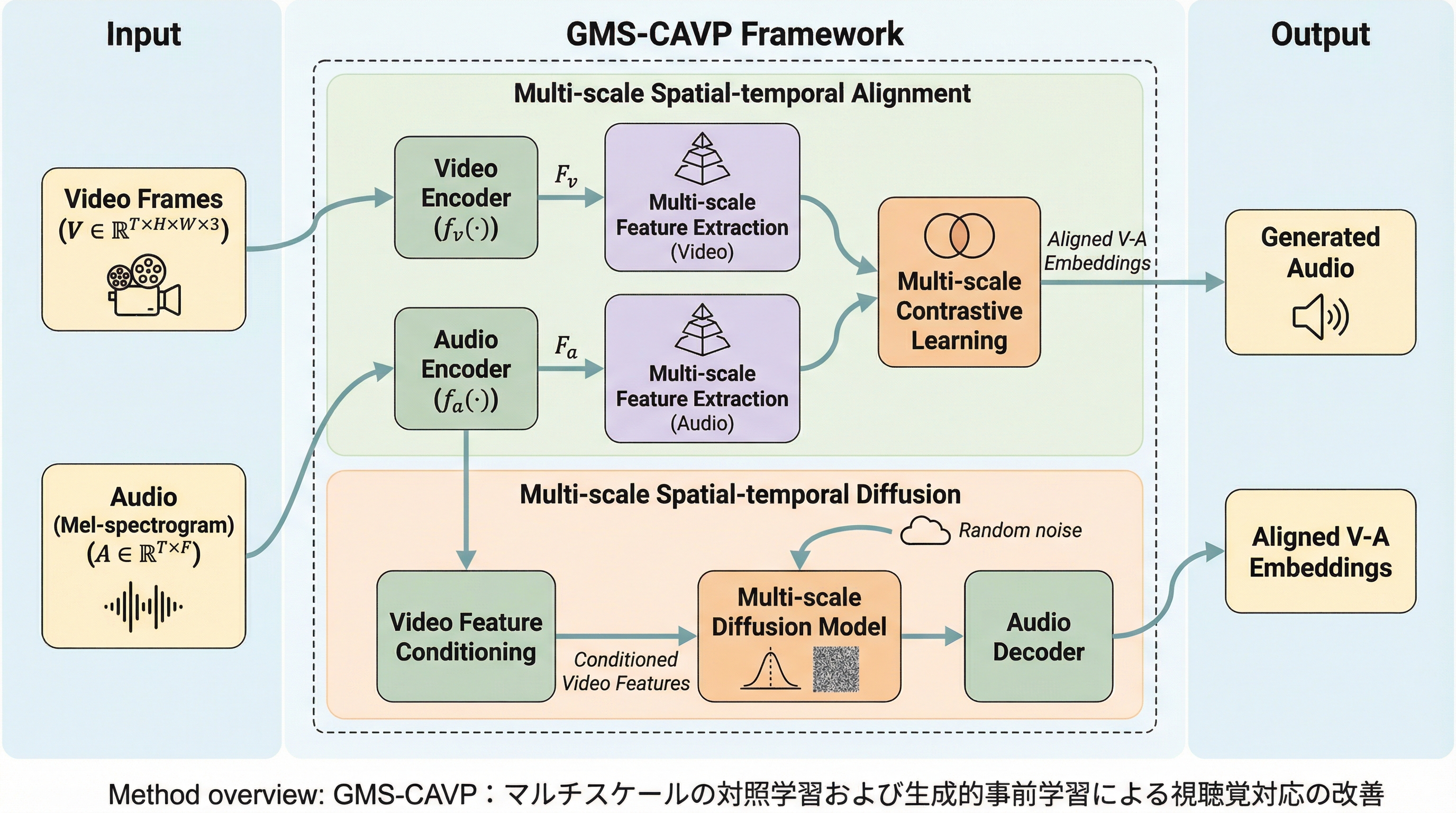
映像と音声の相互理解および生成技術において、両モダリティを共通の潜在空間に埋め込む技術は、クロスモーダル検索や生成タスクの根幹を成している。特に、対照学習を用いた視聴覚事前学習(CAVP)は、映像と音声の対応関係を学習する上で大きな成果を上げてきた。しかし、既存の手法には二つの重大な限界が存在する。第一に、現在の事前学習の目的関数は主に対照学習、つまり「識別的」な側面に特化している点である。映像から音声を合成するような生成タスクにおいては、一方のモダリティから他方へ情報を変換する「翻訳能力」が不可欠であるが、識別的な損失関数のみで学習されたモデルは、生成的な設定において最適なパフォーマンスを発揮できない。映像は高次元で空間的な構造を持ち、音声は連続的で強い周波数依存性を持つという構造的な差異があるため、これらを橋渡しする生成的なマッピングを直接学習することが極めて重要である。 第二に、映像と音声という信号が持つ「高密度かつマルチスケールな性質」が十分に活用されていない点である。…
核心:何を提案したのか
本研究では、上述の課題を抜本的に解決するために、マルチスケールの対照学習と生成学習を一つの枠組みで統合した「GMS-CAVP」を提案している。このフレームワークの核心は、識別的な学習と生成的な学習を調和させることで、検索タスクに必要な「識別力」と生成タスクに必要な「翻訳能力」を同時に獲得させる点にある。具体的には、二つの主要なメカニズムを導入している。一つ目は「マルチスケール空間・時間整列(Multi-scale Spatial-temporal Alignment, MSA)」である。これは、映像と音声の対応関係を複数の解像度で捉えるための仕組みであり、局所的な細かい依存関係から大局的なセマンティクスまでを階層的に学習することを可能にする。これにより、単一スケールの表現では捉えきれなかった微細な視聴覚の同期をモデル化できる。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related