たった一つのトークンで十分:シンクトークンによる拡散言語モデルの改良
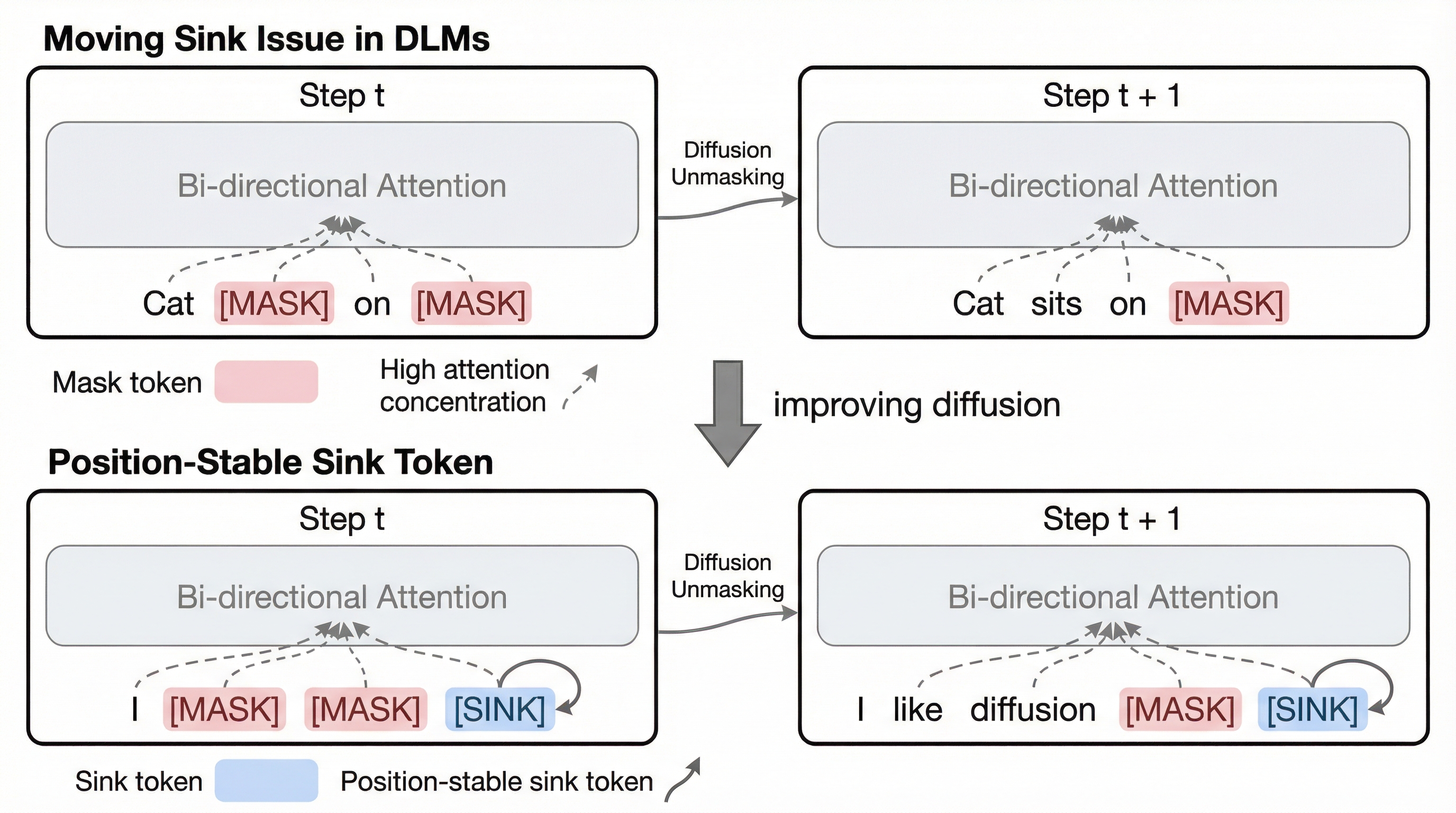
拡散言語モデル(DLM)において、注意が特定のトークンに過度に集中する「シンク現象」が、推論ステップごとに予測不能に移動する「移動シンク現象」を特定し、これがモデルの不安定性を引き起こす課題を明らかにした。
TL;DR(結論)
拡散言語モデル(DLM)において、注意が特定のトークンに過度に集中する「シンク現象」が、推論ステップごとに予測不能に移動する「移動シンク現象」を特定し、これがモデルの不安定性を引き起こす課題を明らかにした。 この問題に対し、自身のみを参照しつつ全トークンから参照可能な独立した「シンクトークン」を1つ追加するだけで、注意の集中先を構造的に固定し、情報の過剰な混ざり合いを抑制する極めてシンプルな手法を提案した。 実験の結果、0.5Bから1.5B規模のモデルにおいて、既存のゲート付きアテンションよりも安定した性能向上を確認し、トークンの位置に関わらず推論の堅牢性が大幅に向上することを、多様な言語タスクのベンチマークを通じて実証した。
なぜこの問題か
拡散言語モデル(DLM)は、自己回帰型(AR)アプローチに代わる強力な選択肢として登場し、並列的なテキスト生成を可能にしている。しかし、標準的なTransformerバックボーンを使用するDLMには、特有の不安定性が存在する。それが「移動シンク(moving sink)」現象である。自己回帰型モデルでは、因果マスク(causal mask)を通じて最初のトークンに過剰な注意を固定することで、この現象を意図せず安定させている。対照的に、DLMには一貫した開始トークンや因果マスクといった構造的制約が存在しない。その結果、注意が集中するシンクの位置が、デノイジングのステップやネットワークの層を跨いで不規則にシフトしてしまうのである。 本研究の分析によれば、DLMにおけるシンクトークンは、Transformerのバリュースペースにおいて一貫して低いL2ノルムを示すことが明らかになった。具体的には、LLaDAではシンクトークンの平均L2ノルムが2.36であるのに対し、通常のトークンは7.60であった。Dreamにおいても、シンクトークンは3.15、通常トークンは7.79という顕著な差が見られた。…
核心:何を提案したのか
本研究では、拡散言語モデルの不安定な移動シンク問題を解決するために、位置が固定された専用の「追加シンクトークン(extra sink token)」を導入することを提案した。この手法は、入力シーケンスの先頭に1つの特別なトークンを付加するという、非常にシンプルかつ効果的なアーキテクチャの変更である。このトークンの主な目的は、過剰な注意の重みを吸収するための安定した、低情報のターゲットとして機能することにある。これにより、モデルは意味のあるコンテンツトークンに無理に注意を割り当てる必要がなくなり、情報の純度を保つことが可能になる。 このシンクトークンの役割を厳密に強制し、意味的な情報が集約されるのを防ぐために、修正されたアテンションマスクを適用する。具体的には、2つの制約を設けている。第一に、シンクトークンは自分自身のみに注意を向けるように制限される。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related