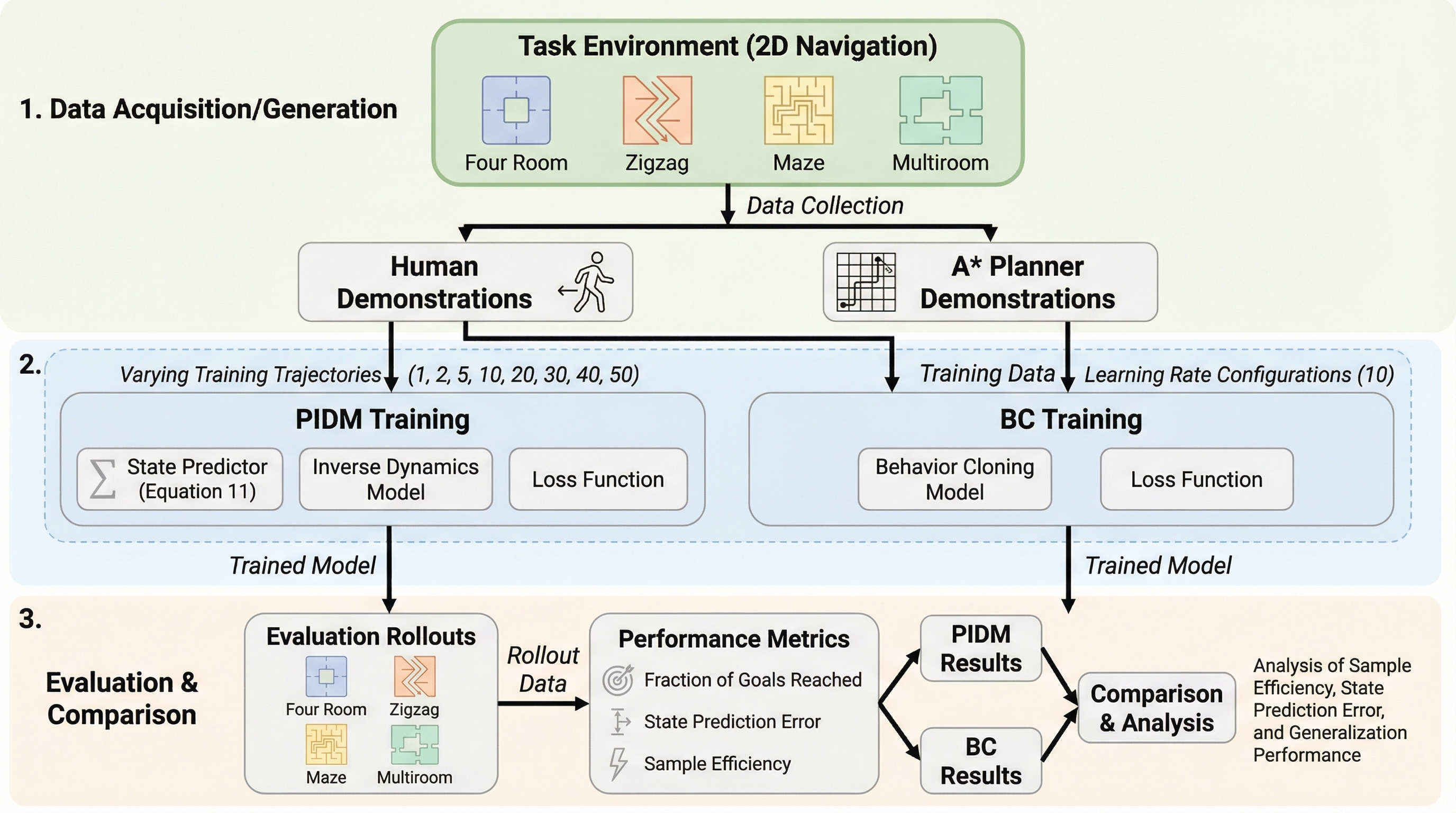
予測逆ダイナミクスはいつ行動クローニングを凌駕するのか?
オフライン模倣学習において、未来の状態予測と逆ダイナミクスを組み合わせた予測逆ダイナミクスモデル(PIDM)が、従来の行動クローニング(BC)よりも高いサンプル効率を実現する理由を理論と実験の両面で解明しました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
オフライン模倣学習において、未来の状態予測と逆ダイナミクスを組み合わせた予測逆ダイナミクスモデル(PIDM)が、従来の行動クローニング(BC)よりも高いサンプル効率を実現する理由を理論と実験の両面で解明しました。
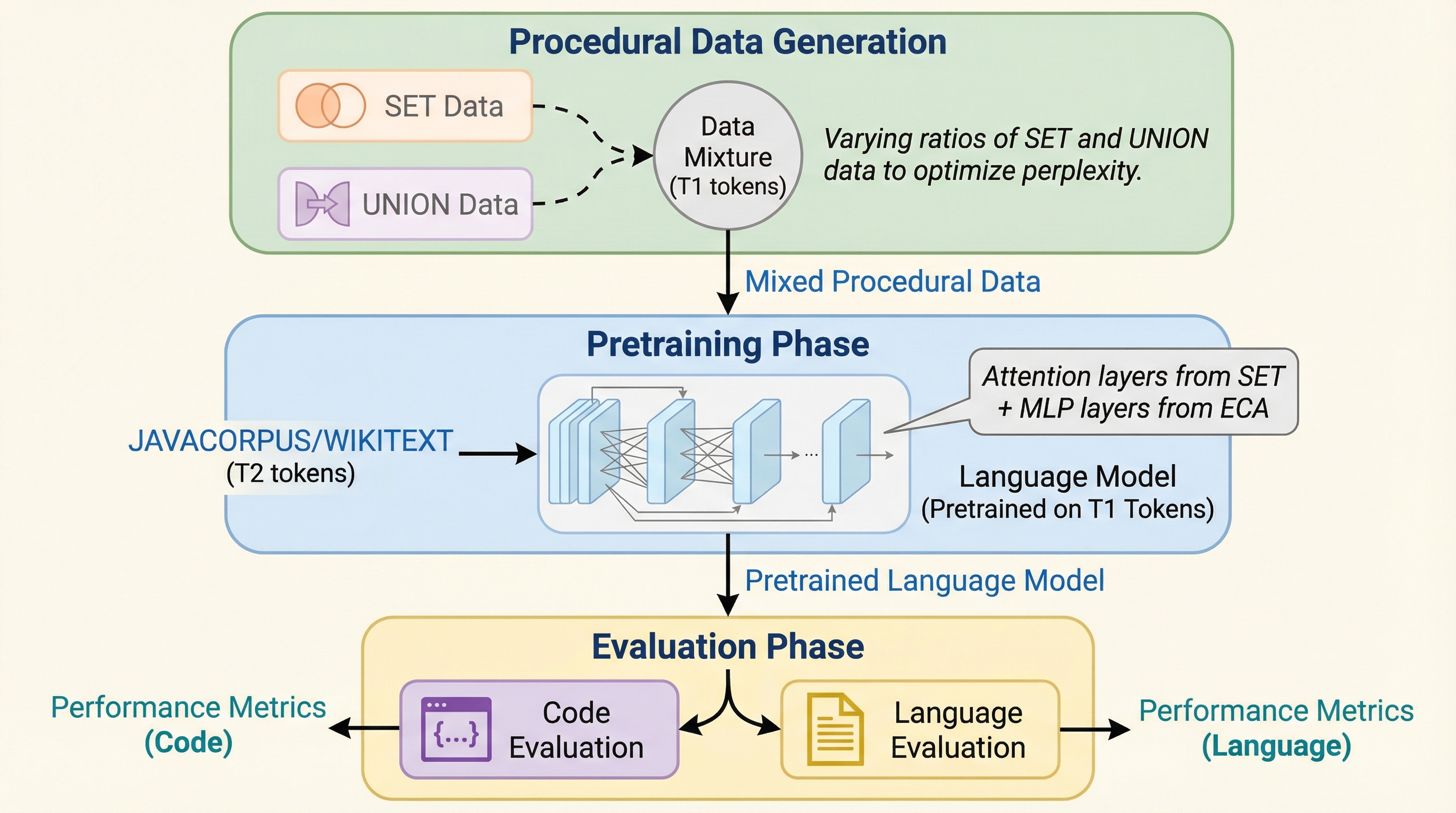
大規模言語モデルの事前学習において、自然言語やコードなどの意味を持つデータに触れる前に、アルゴリズムによって生成された抽象的な構造データ(手続き型データ)を学習させる「手続き型事前学習」という手法を提案した。
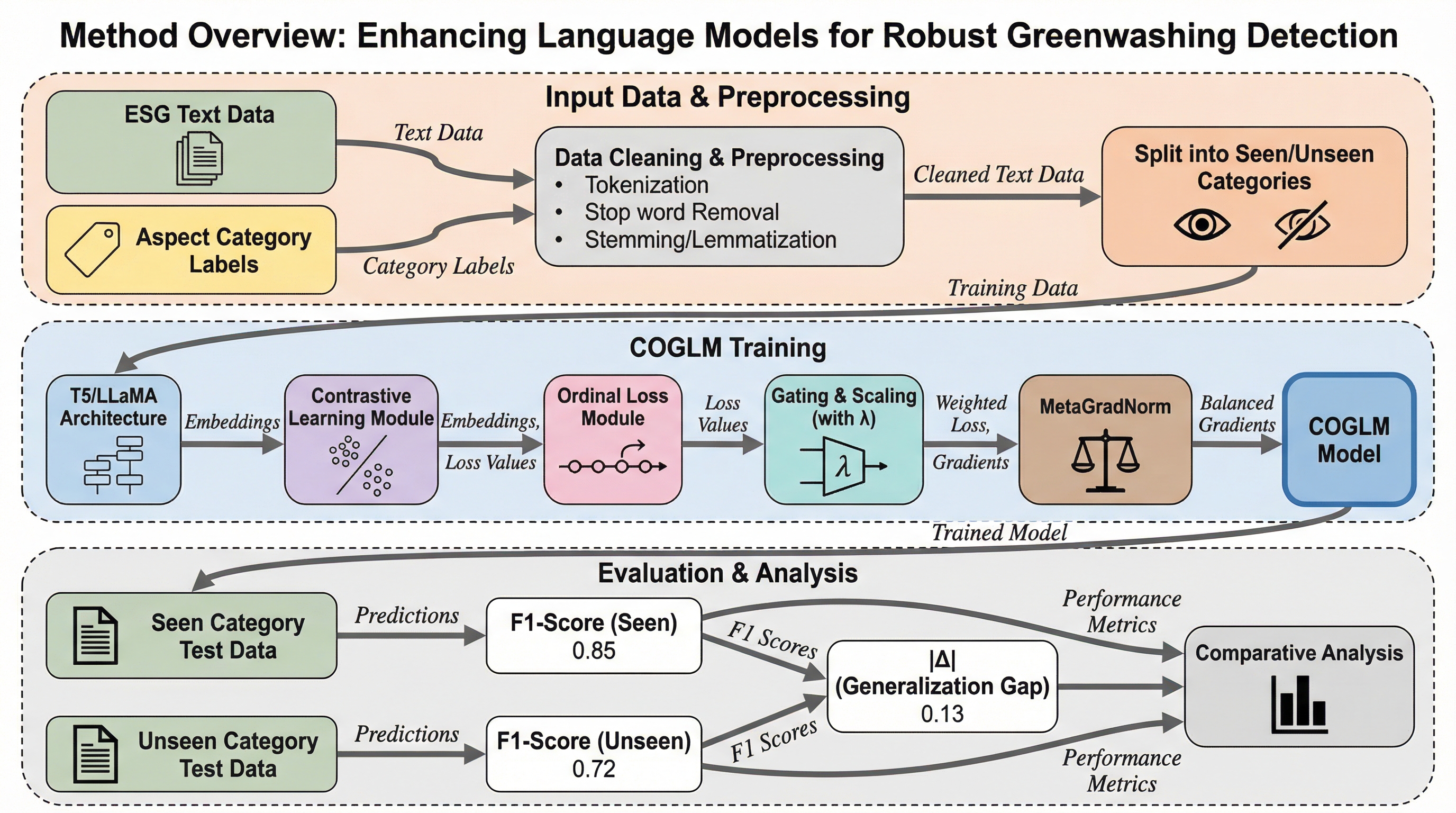
企業のサステナビリティ報告書におけるグリーンウォッシュや曖昧な主張を特定するため、大規模言語モデルの潜在空間を構造化する新しいパラメータ効率の良い学習フレームワーク「COGLM」が提案されました。
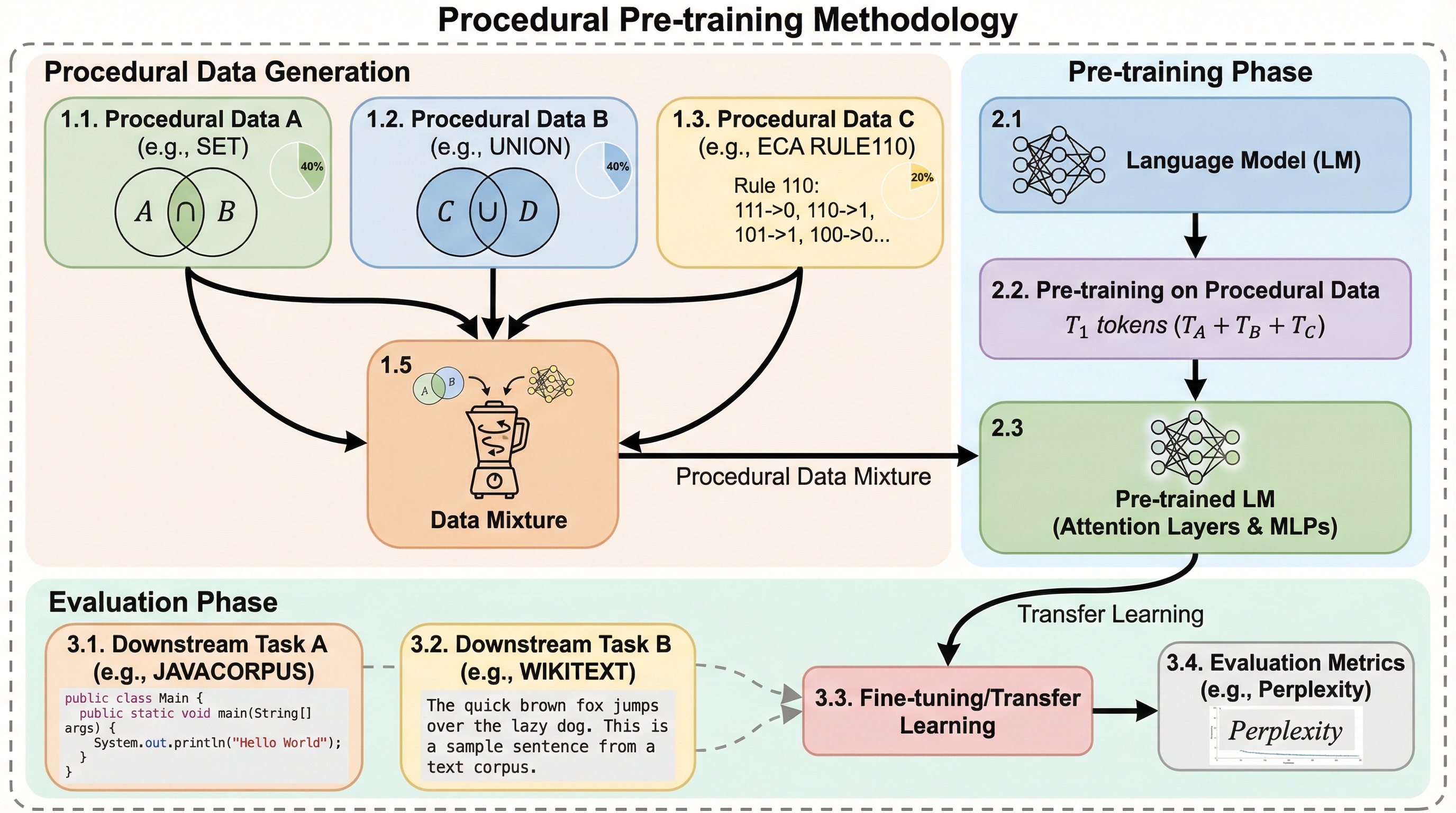
大規模言語モデルの学習において、自然言語の前に抽象的な構造を持つ「手続き型データ」を学習させる「手続き型事前学習」という手法が提案されました。この手法は、特定のアルゴリズムタスク(コンテキスト想起など)の精度を10%から98%へ劇的に向上させ、標準的な自然言語やコードの学習を大幅に加速させる効果があります。
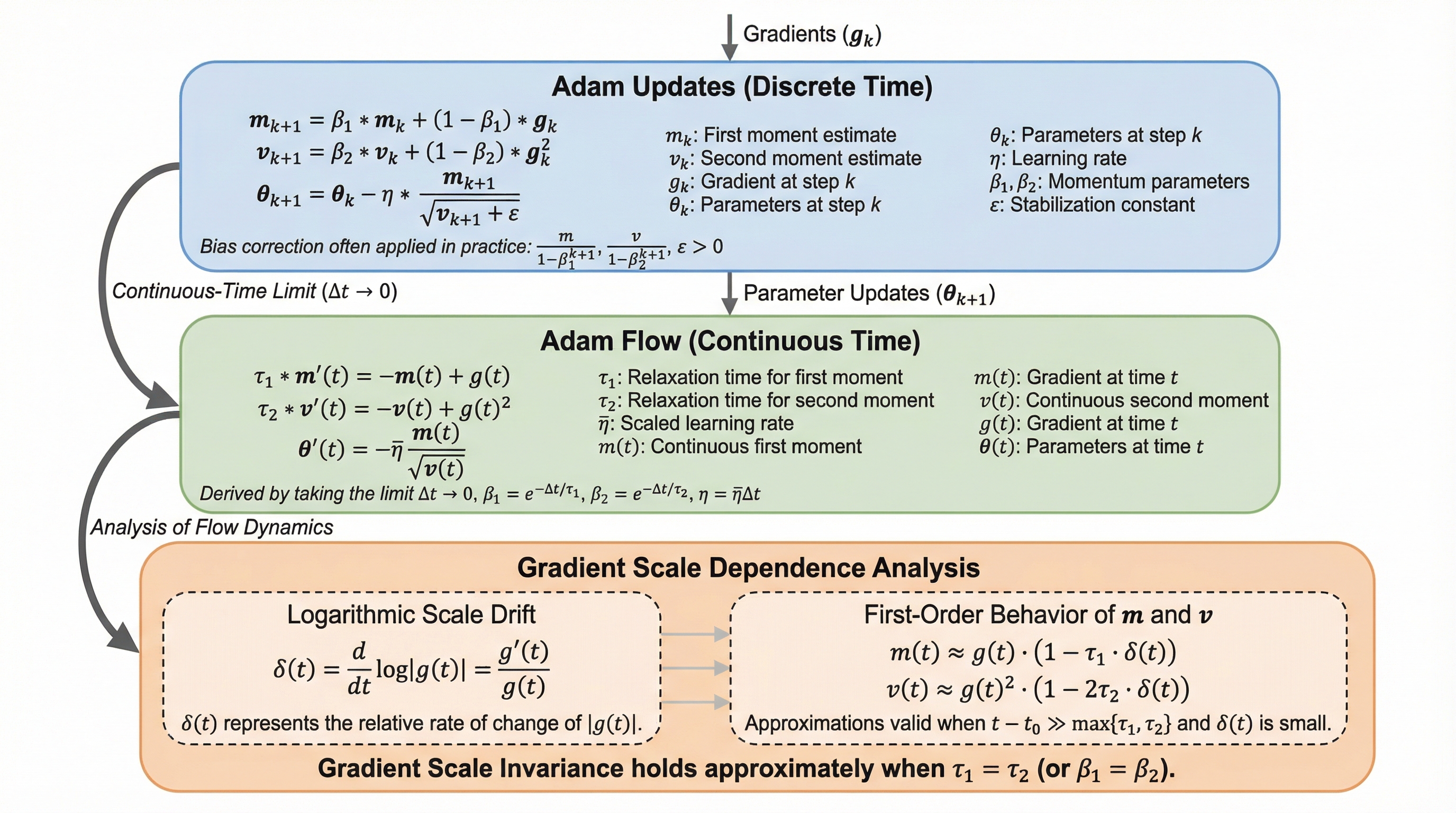
Adamのハイパーパラメータである$\beta1$と$\beta2$を等しく設定することで、訓練の安定性と精度が向上するという経験的事実に対し、「勾配スケール不変性」という新たな理論的枠組みを導入して数学的な解明を行った。
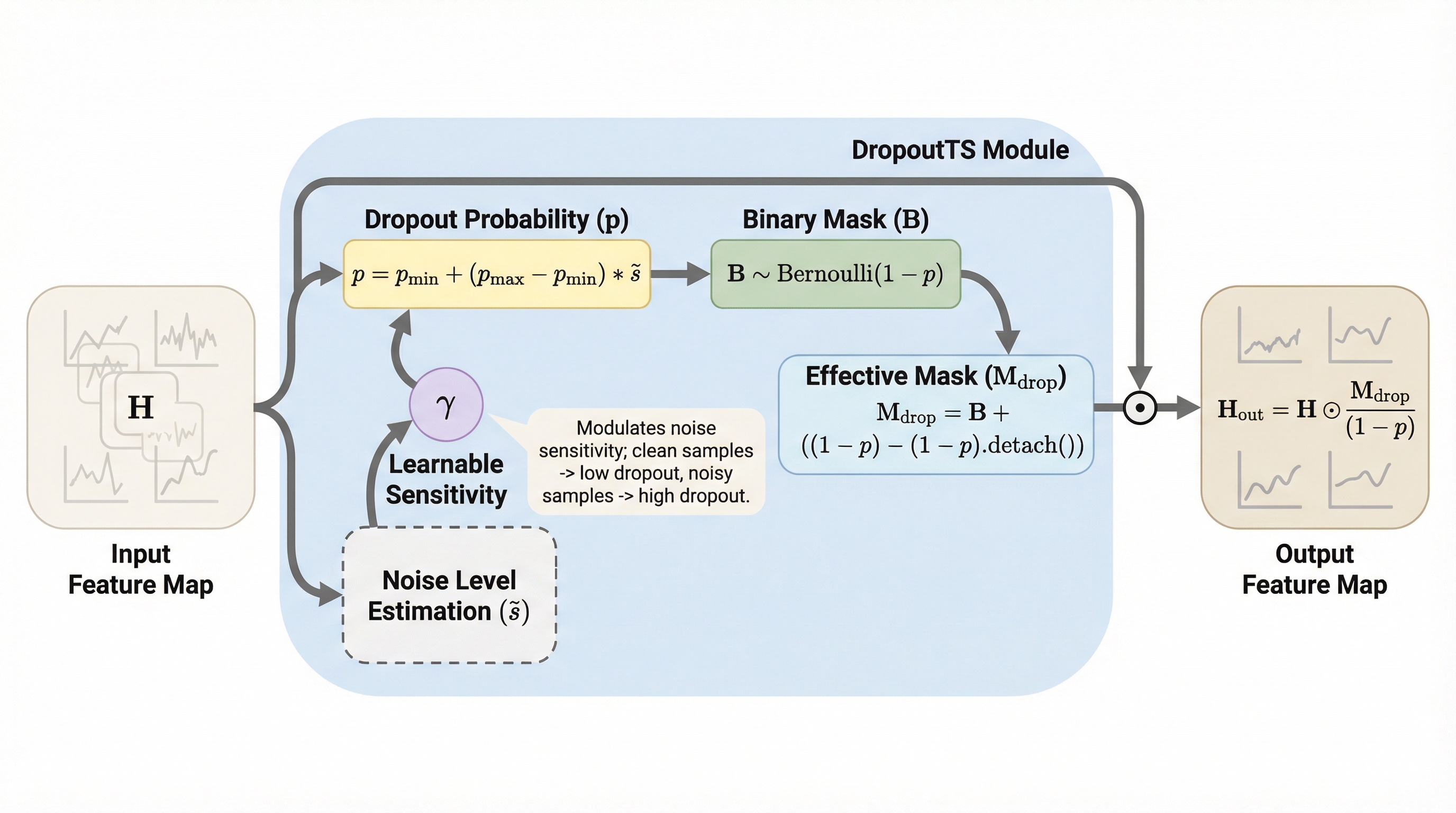
深層時系列予測モデルが実世界のノイズに対して脆弱であるという課題に対し、データの削除や複雑な事前分布の仮定に頼らず、モデルの学習容量をサンプルごとに動的に調整する新しいパラダイム「容量中心の変調(Capacity-Centric Modulation)」を提案した。
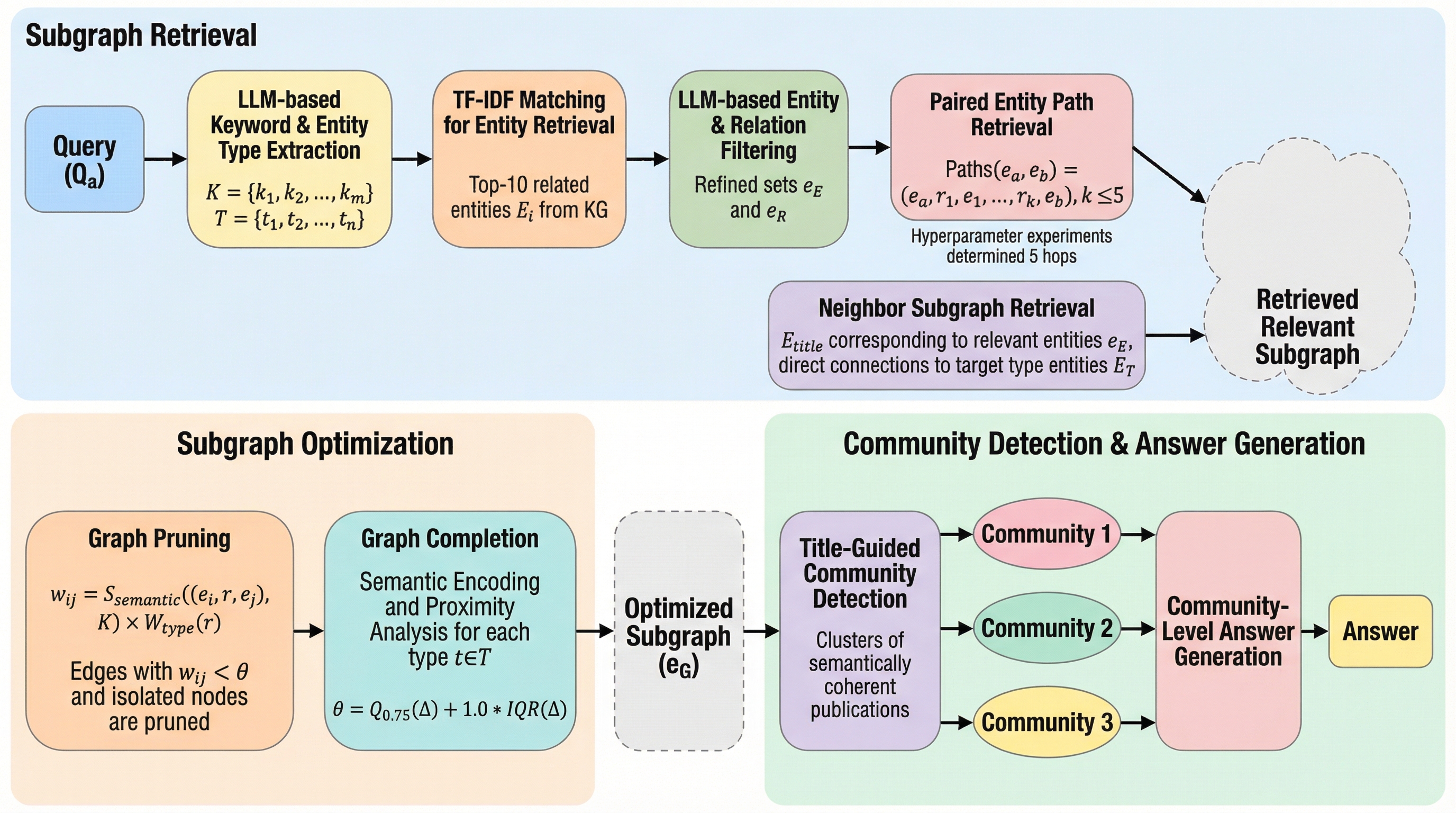
大規模言語モデル(LLM)を用いた科学文献の質問応答において、従来の検索手法では論文間の深い意味的つながりを見落とし、回答の包括性や具体性が損なわれるという課題がありました。 本研究が提案するCE-GOCDは、論文タイトルを中心エンティティとして定義し、グラフの枝刈りや補完による最適化とコミュニティ検出を組み合わせることで、文献間の潜在的な関係を明示的にモデル化します。 NLP分野の複数のデータセットを用いた検証の結果、提案手法は既存のグラフ活用型RAG手法を上回る精度を達成し、医学ドメインへの適応可能性や回答生成における高い網羅性と正確性が確認されました。
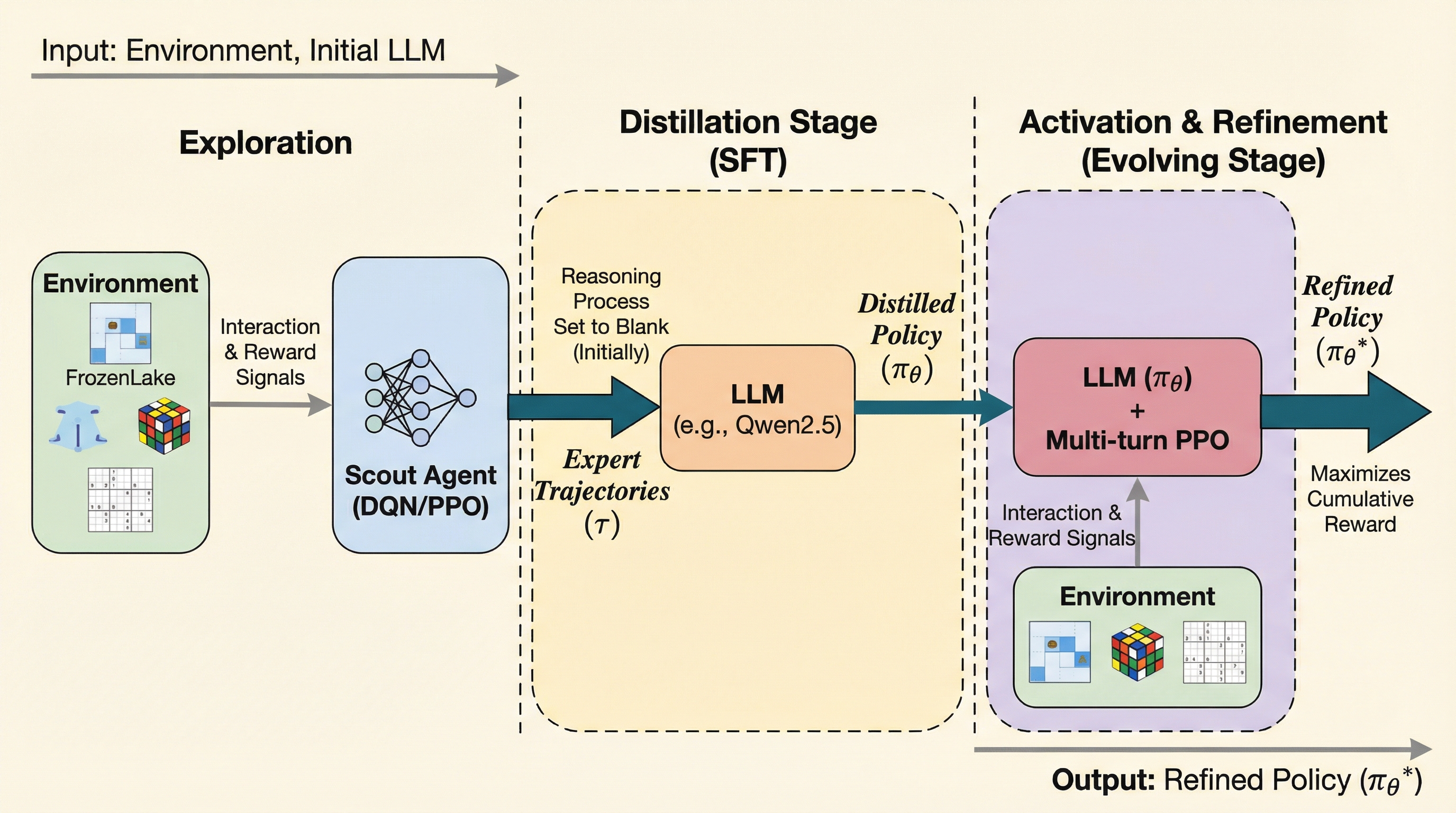
大規模言語モデル(LLM)は言語タスクには強いものの、記号的・空間的な未知のタスクでは膨大なパラメータによる探索コストが障壁となり、試行錯誤の効率が著しく低いという課題がある。 本研究が提案するSCOUTは、軽量なニューラルネットワーク(スカウト)に環境探索を任せて成功軌跡を生成し、それをテキスト化してLLMに蒸留した後、多ターン強化学習で能力を活性化させる新しいフレームワークである。 実証実験では、Qwen2.5-3Bモデルが平均スコア0.86を記録し、Gemini-2.5-Proなどの商用モデルを大幅に上回る性能を示しながら、計算リソースであるGPU時間を約60%削減することに成功した。
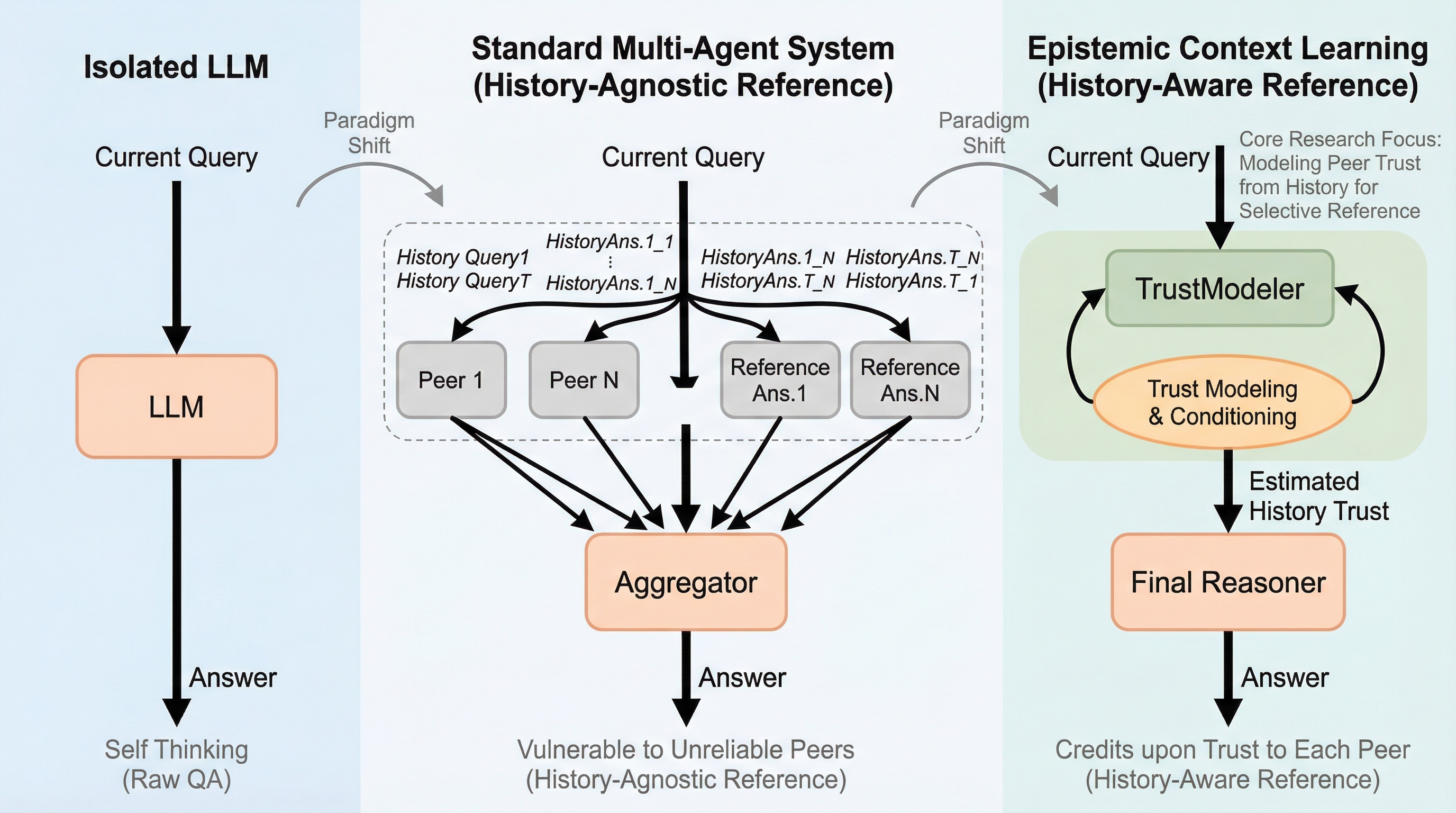
LLMベースのマルチエージェントシステムにおいて、エージェントが誤った情報を持つ他者に盲目的に同調してしまう脆弱性を解決するため、過去の対話履歴から他者の信頼性を評価して情報を選択的に参照する「履歴を考慮した参照」という新しいパラダイムを提案した。
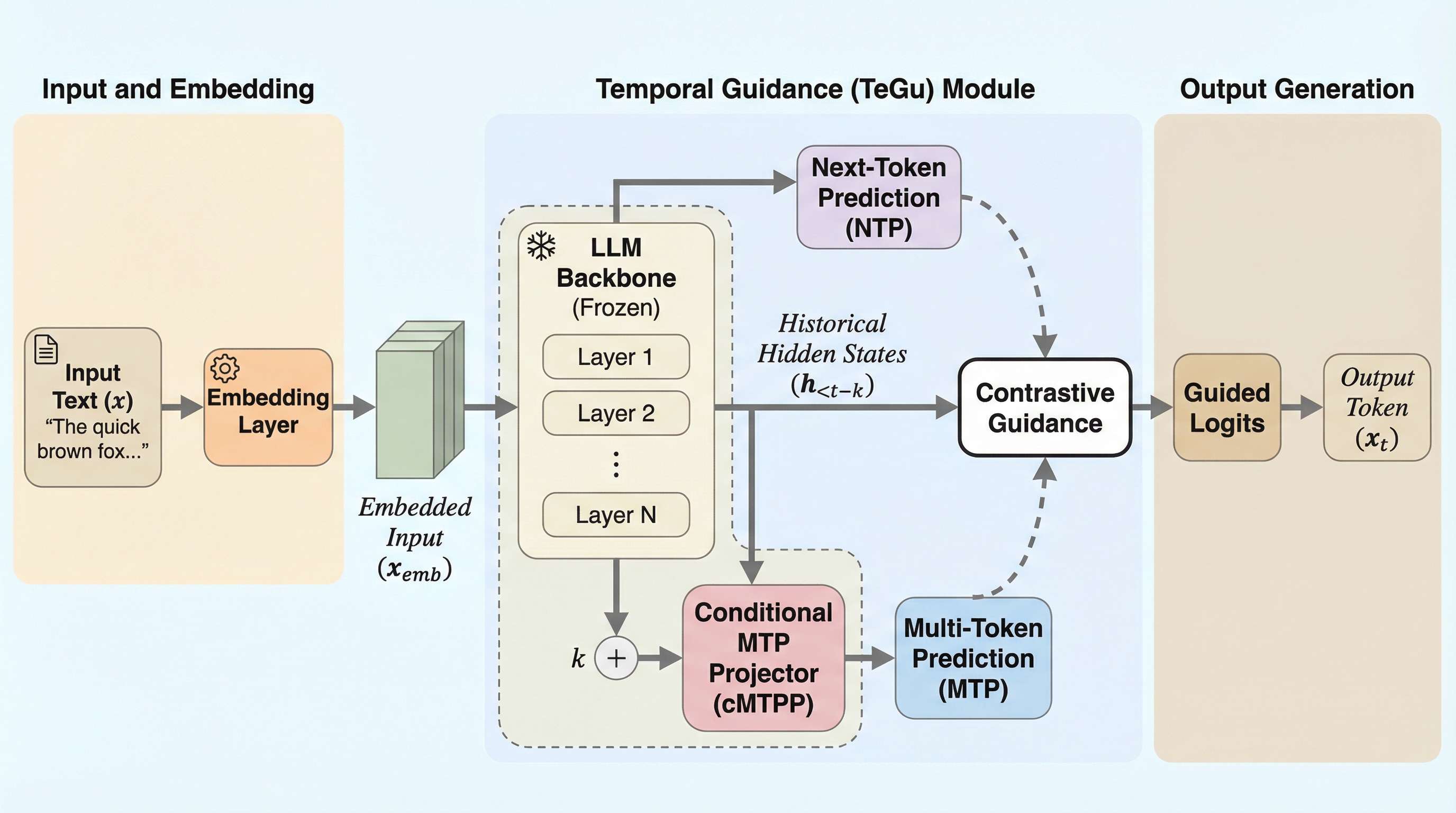
大規模言語モデル(LLM)の生成品質を向上させるため、モデル自身の過去の不完全な予測を「アマチュア」として利用し、現在の予測と対比させる新しいデコーディング戦略「TeGu(Temporal Guidance)」が提案されました。