ILRR: マスク型拡散言語モデルのための推論時ステアリング手法
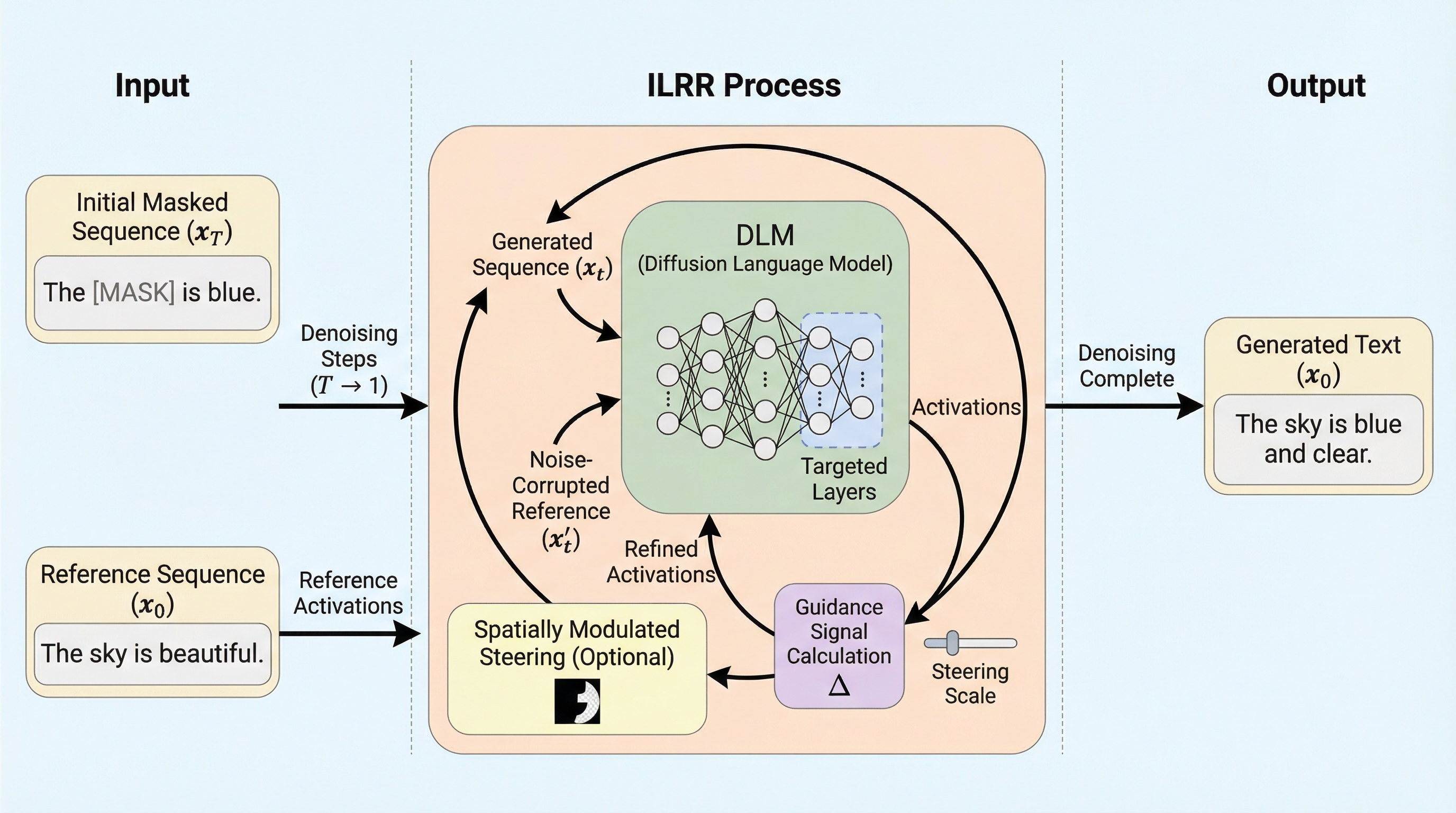
離散拡散言語モデル(DLM)の生成を制御するため、追加の学習や微調整を一切必要とせず、単一の参照シーケンスを用いてモデル内部の活性化状態を動的に調整する「反復的潜在表現洗練(ILRR)」という新しいフレームワークが提案されました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
離散拡散言語モデル(DLM)の生成を制御するため、追加の学習や微調整を一切必要とせず、単一の参照シーケンスを用いてモデル内部の活性化状態を動的に調整する「反復的潜在表現洗練(ILRR)」という新しいフレームワークが提案されました。
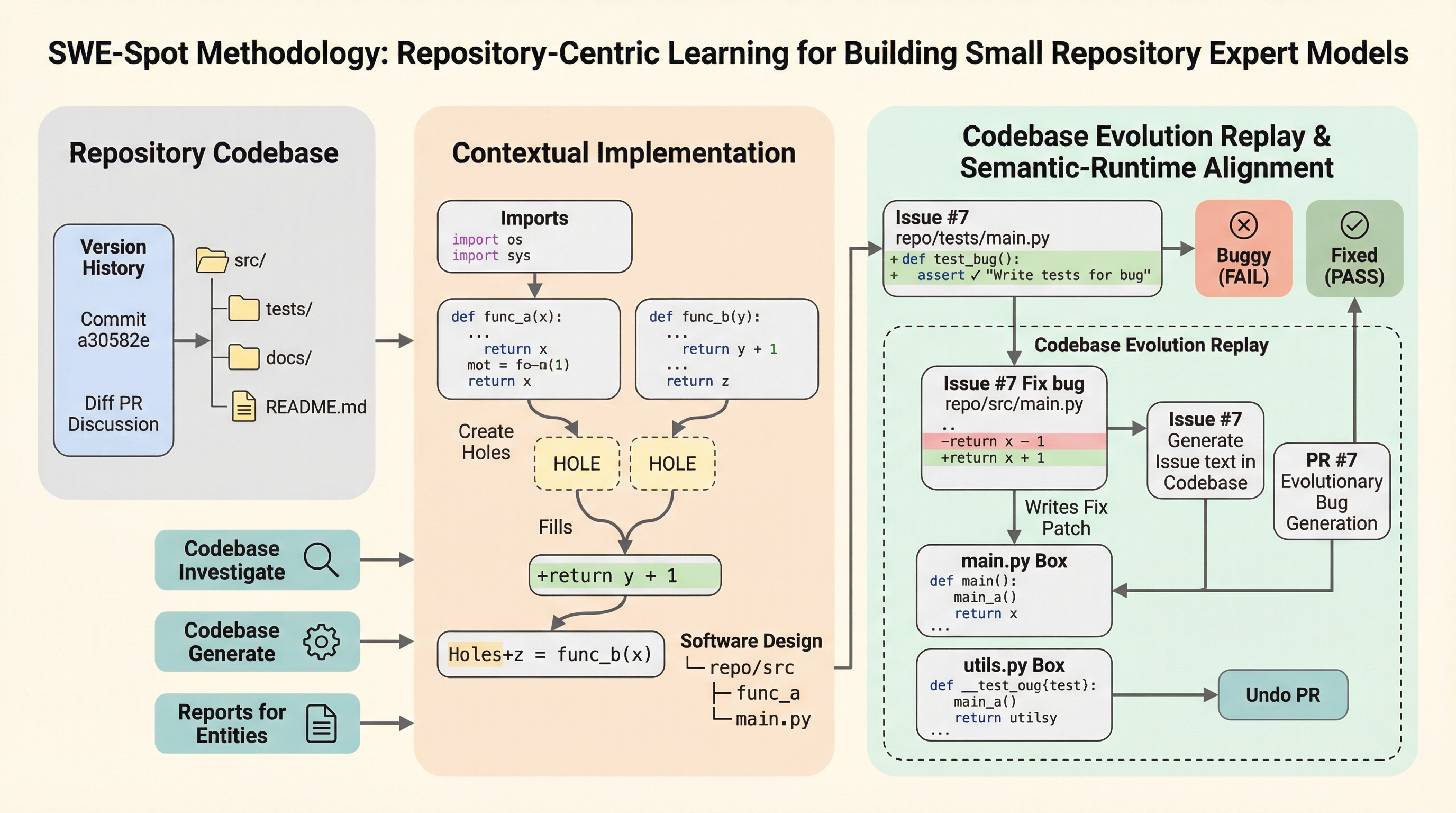
従来のタスク中心学習では、小規模言語モデルが複雑なコードベースの推論時に十分な汎化性能を発揮できず、表面的なパターンの学習に留まるという課題がありました。 本研究は、特定のコードベースに対する垂直的な深さを優先する「リポジトリ中心学習(RCL)」を提案し、静的なコードを対話的な学習信号に変換する4つの経験ユニットを設計しました。 この手法で構築された4BパラメータのSWE-SPOTは、8倍大きなオープンモデルや商用モデルに匹敵する性能を、高いサンプル効率と低い推論コストで実現することに成功しました。
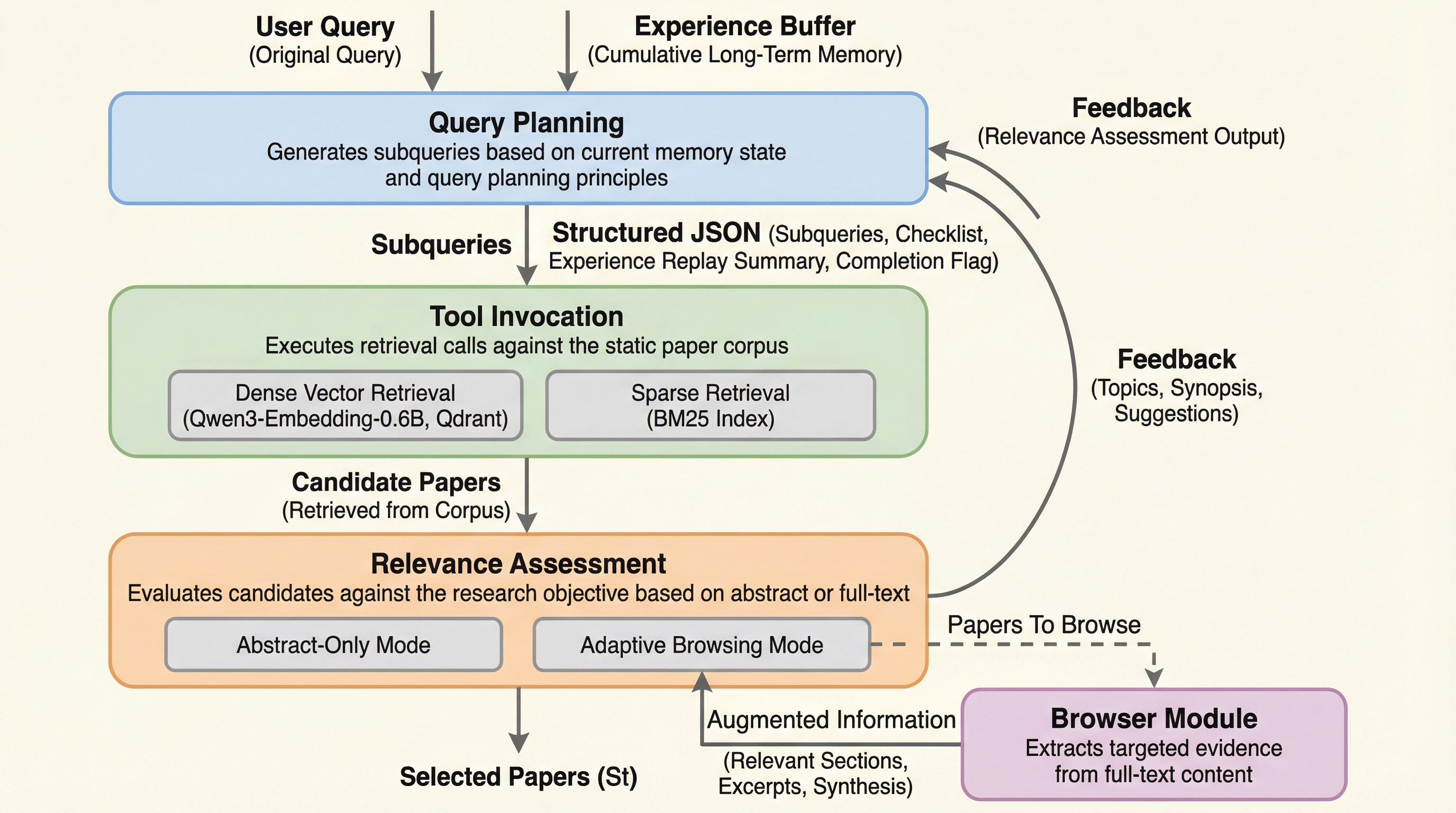
従来の深層リサーチワークフローの評価は、ライブAPIの非決定性や検索インデックスの時間的変動、レート制限などの環境的要因により再現性が困難であったが、本研究では57万件の固定コーパスと確定的な検索エンジンを用いたシミュレーション環境「ScholarGym」を開発した。
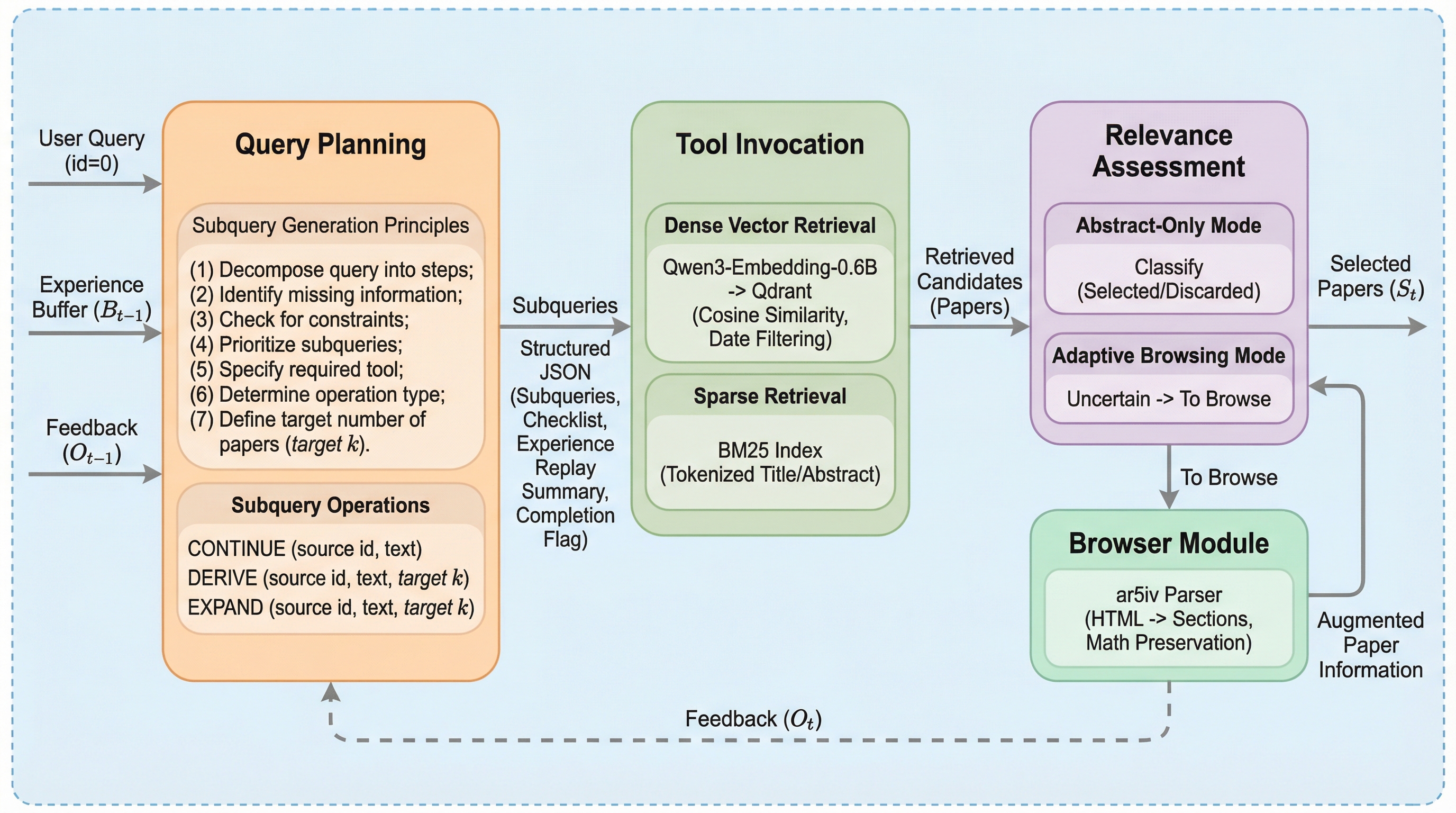
従来の学術文献検索の評価は、Google SearchなどのライブAPIに依存していたため、検索インデックスの更新やレート制限といった外部要因により結果が変動し、再現性が確保できないという根本的な課題がありました。
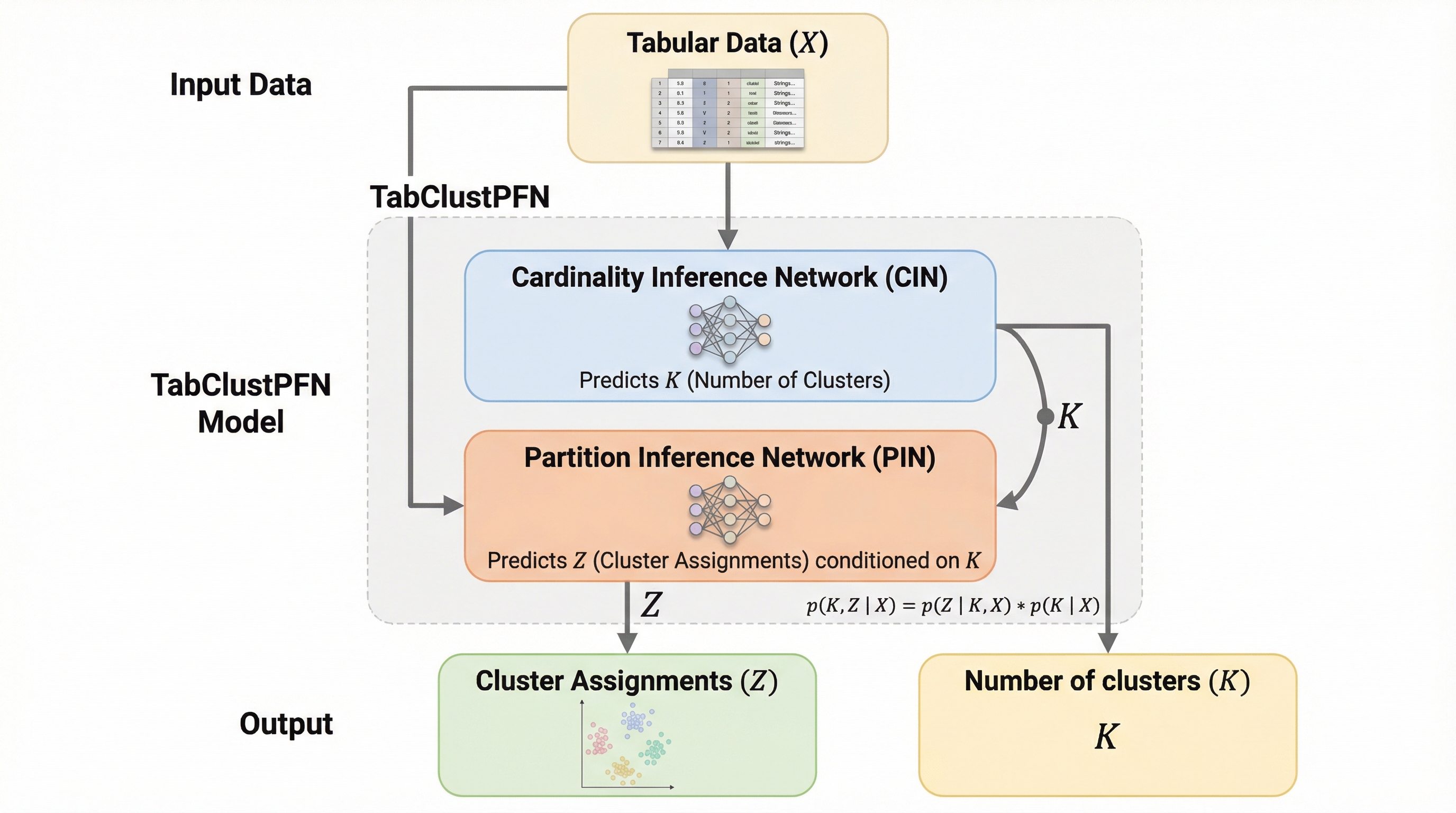
TabClustPFNは、表形式データのクラスタリングを高速かつ高精度に実行するために開発された、新しい事前適合ネットワーク(PFN)である。このモデルは、クラスタの割り当てを推論するネットワーク(PIN)とクラスタの数自体を推定するネットワーク(CIN)の2つで構成されており、事前のデータセットごとの再学習やハイパーパラメータの調整を一切必要としない。合成データを用いた大規模な事前学習により、未知のデータセットに対しても1回のフォワードパスで即座に結果を出力し、従来の古典的手法や深層学習手法を上回る性能を達成している。さらに、数値データとカテゴリデータが混在する不均一なデータ構造を自然に扱うことができ、サンプル数が1,000個程度のデータセットであれば、クラスタ数が不明な状態でもスペクトラルクラスタリングと比較して最大500倍高速に動作するという驚異的な効率性を備えている。これにより、データサイエンティストは新しいデータに対して即座に深い洞察を得ることが可能となる。
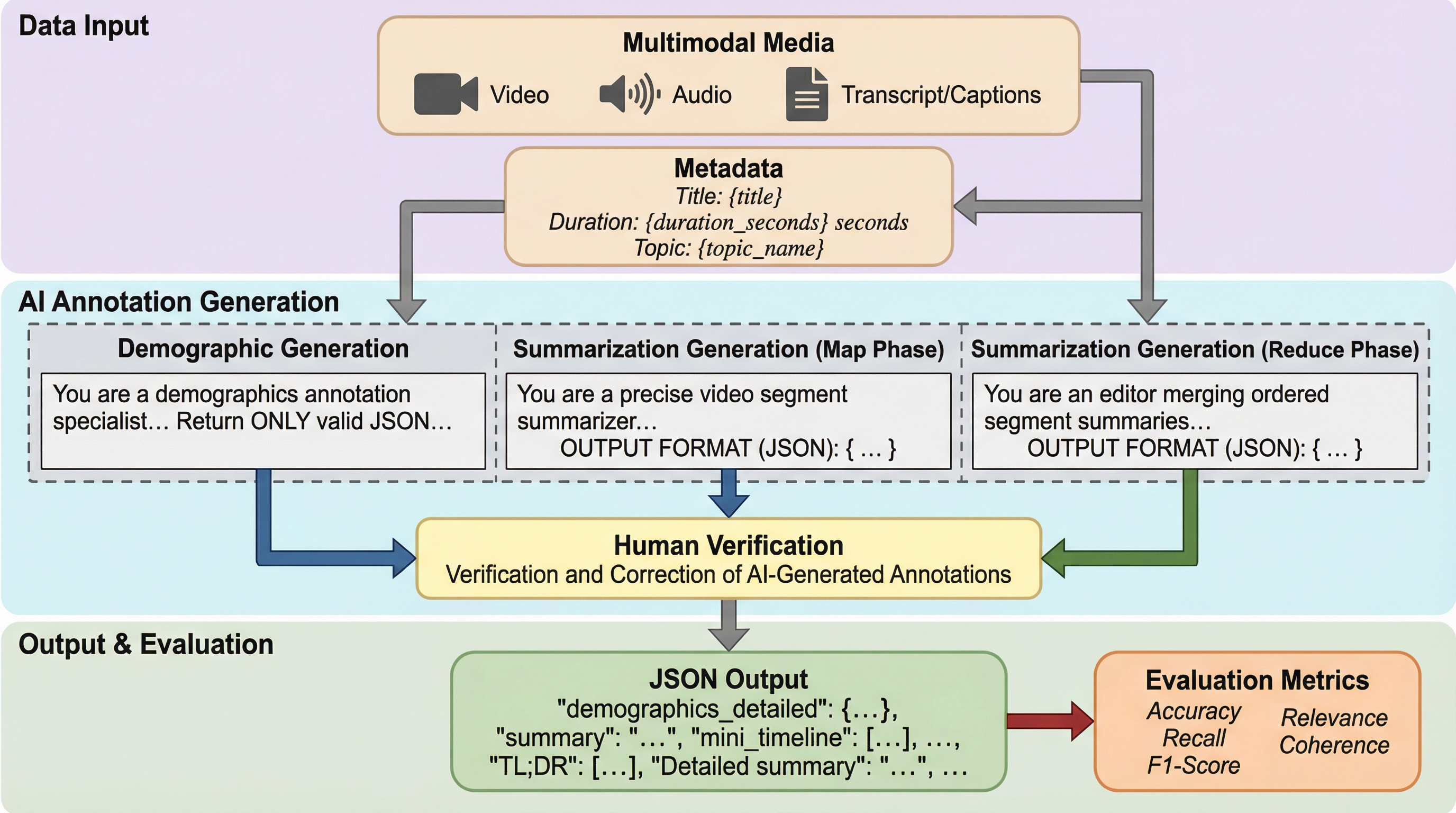
マルチモーダル大規模言語モデル(MLLM)の音声・動画理解能力を評価するため、13の実世界ドメインを網羅した4,958件の高品質な注釈付きデータセット「SONIC-O1」が提案されました。 このベンチマークは、要約、多肢選択問題、時間的ローカライゼーションの3つのタスクを通じて、モデルが音声と映像の両方を統合的に理解できているかを厳密に検証し、特に社会的公平性の観点から人口統計学的なメタデータを付与している点が特徴です。 検証の結果、クローズドソースモデルがオープンソースモデルを圧倒し、特に時間的推論において22.6%もの大きな性能差があることや、人種や性別などの属性によってモデルの精度に偏りが生じることが明らかになりました。
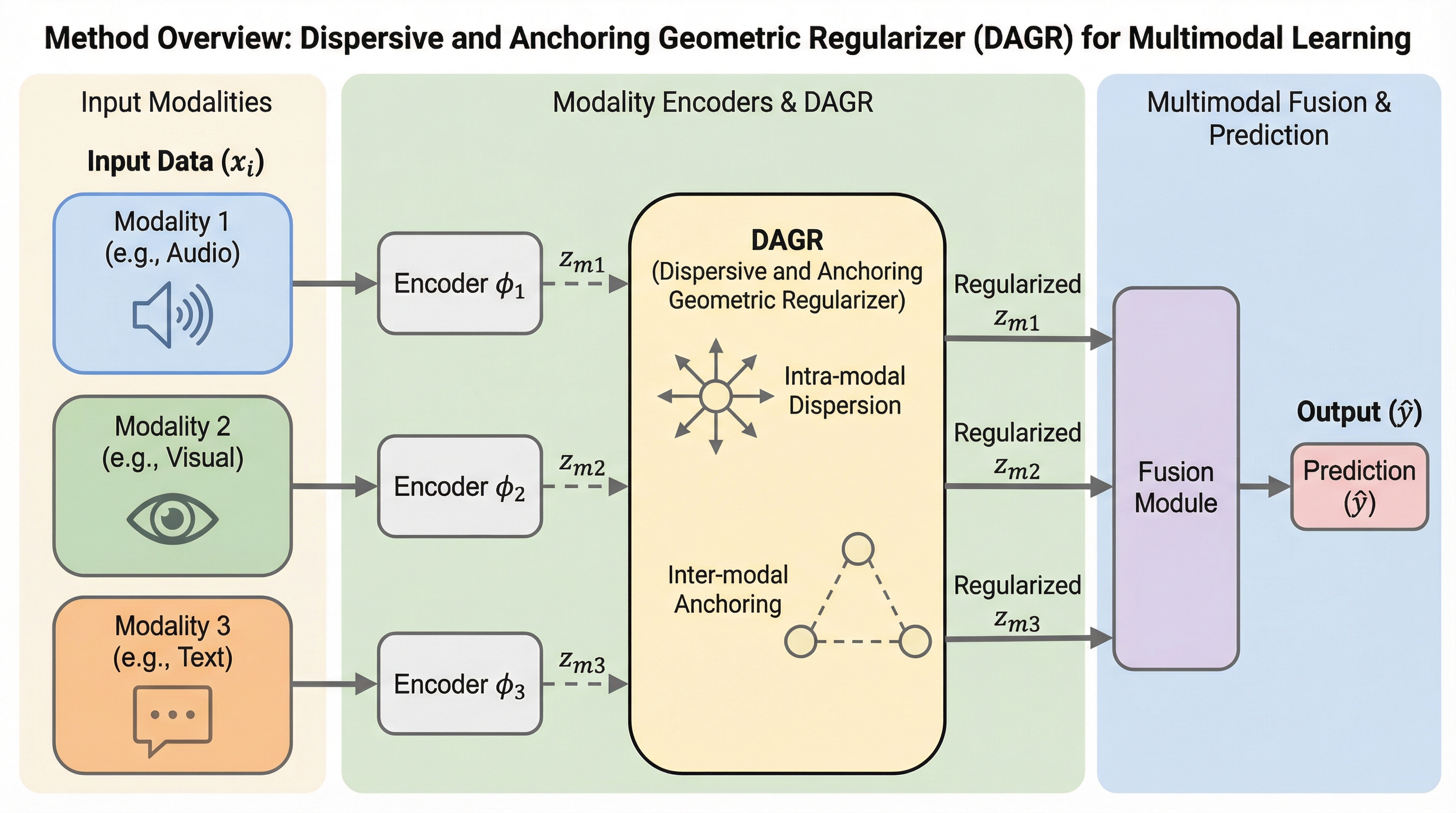
マルチモーダル学習において、強力な勾配最適化を行っても表現空間が特定の領域に固まる「幾何学的崩壊」やモダリティ間の不整合が生じ、特定の情報が他方を抑制するトレードオフが発生することを特定しました。
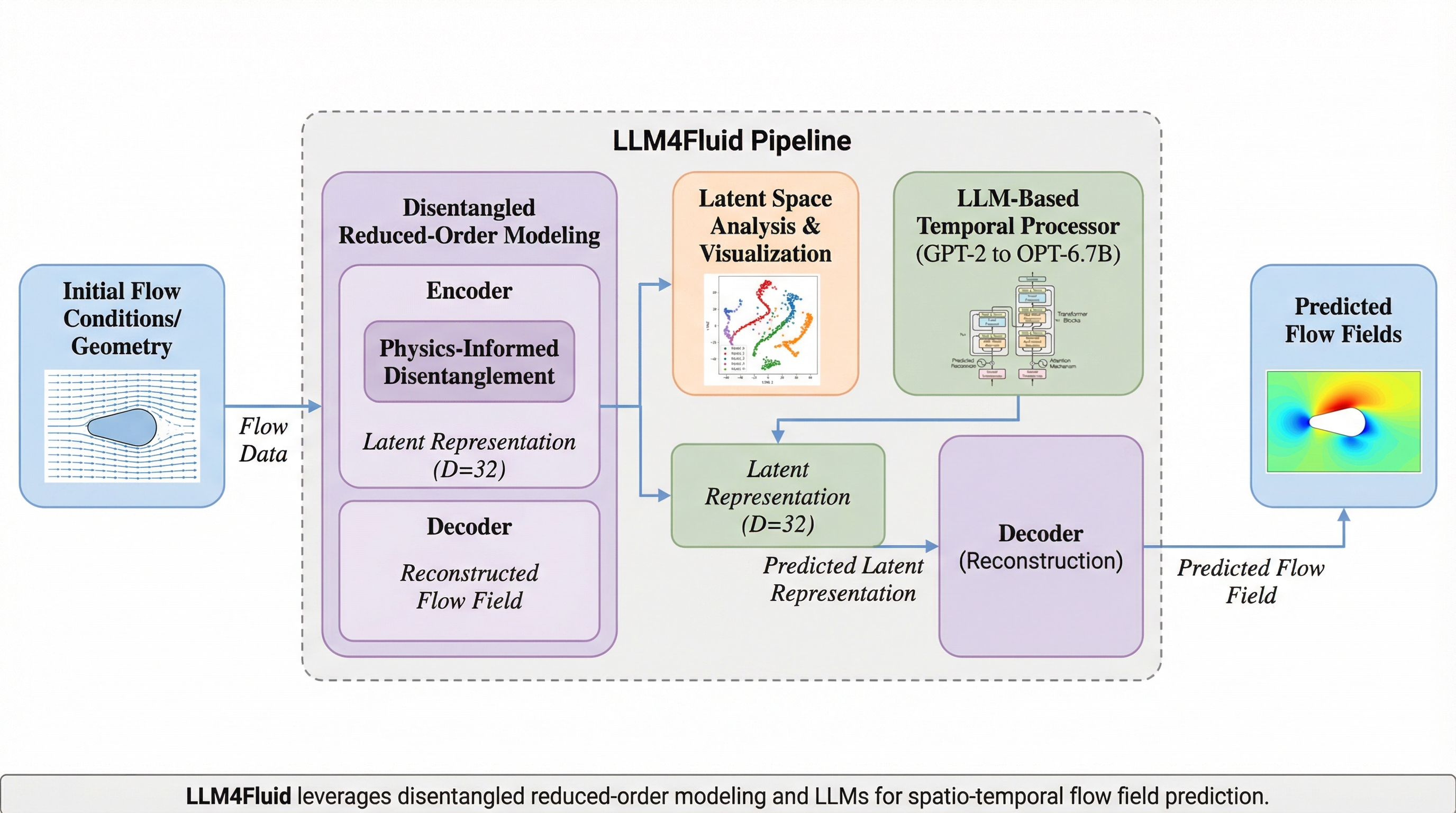
本研究では、大規模言語モデル(LLM)を流体力学の汎用的なニューラルソルバーとして活用する「LLM4Fluid」という革新的な時空間予測フレームワークを提案しました。このシステムは、物理情報を考慮した解きほぐしメカニズムによって高次元の流場をコンパクトで直交性の高い潜在空間に圧縮し、事前学習済みLLMを時間プロセッサとして用いることで、再学習なしで未知の流動条件に対応できる高い汎用性を実現しています。さらに、テキストプロンプトを位置エンコーディングとして統合する独自のモダリティ整合戦略を導入することで、セマンティックな情報と物理データのギャップを埋め、長期的な予測における安定性と最先端の精度を達成することに成功しました。
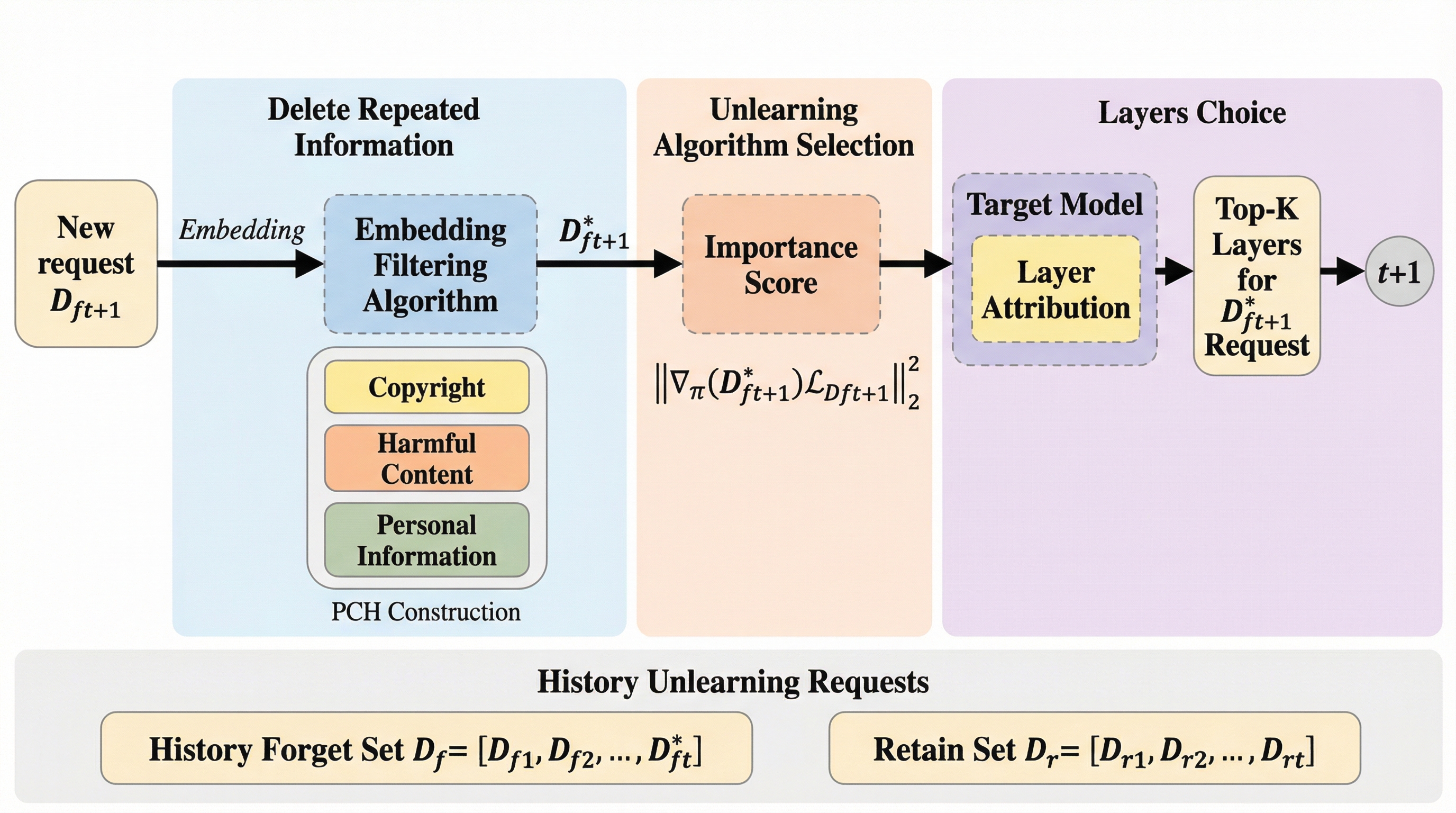
FITは、大規模言語モデル(LLM)が連続的なデータ削除要求を受けた際に発生する「破滅的忘却」を防ぐための新しい学習フレームワークである。 この手法は、重複情報のフィルタリング、重要度に応じたアルゴリズムの適応的選択、そして影響の大きい層に限定した更新という3つの戦略を統合することで、モデルの性能維持と確実な情報消去を両立させている。 また、個人情報や著作権、有害コンテンツを網羅した評価ベンチマーク「PCH」と、消去の度合いと性能維持を統合的に測る新指標を提案し、300件もの連続的な要求に対しても既存手法を凌駕する堅牢性を実証した。
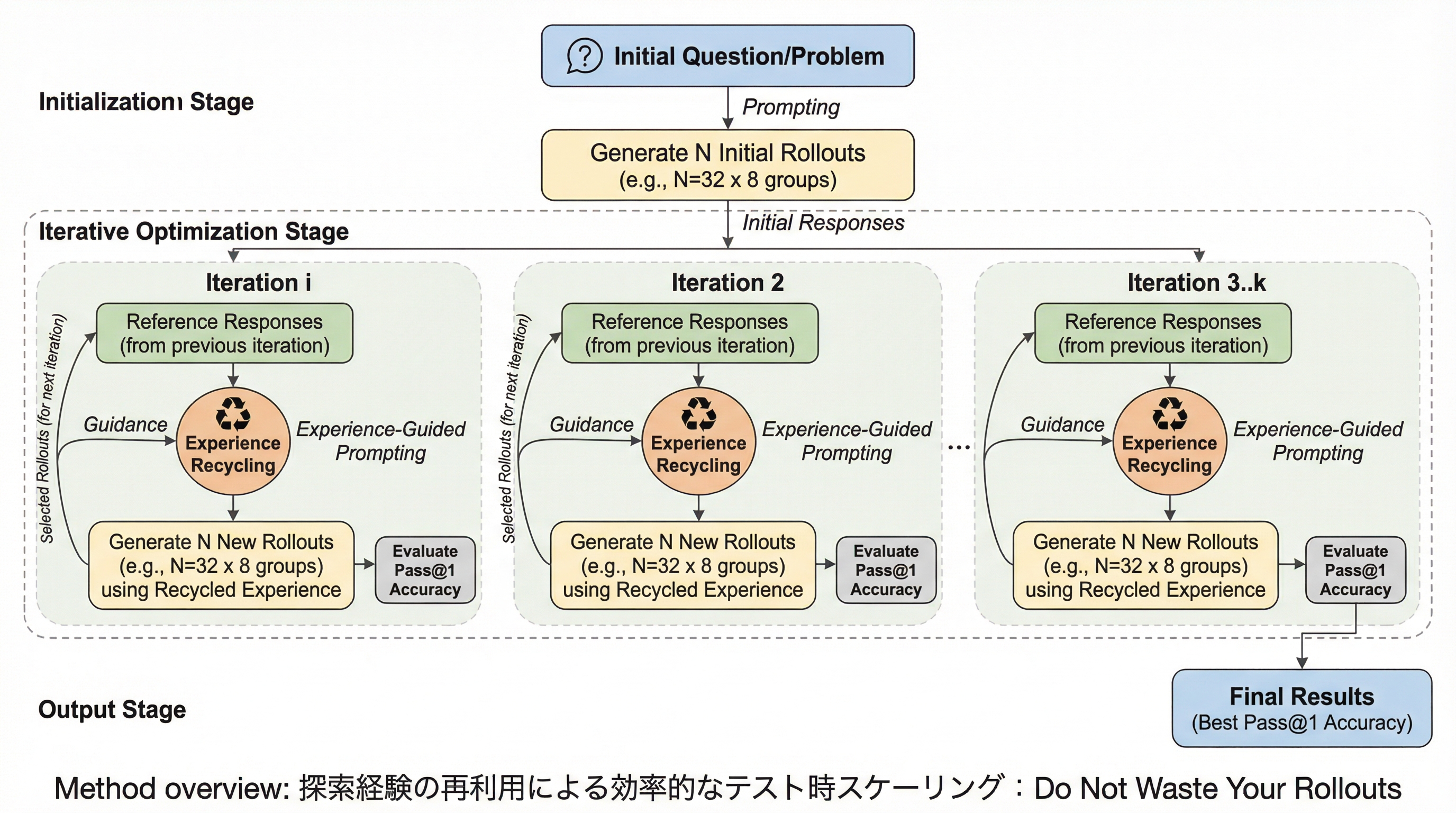
大規模言語モデルの推論能力を高めるテスト時スケーリングにおいて、従来の探索手法が各試行(ロールアウト)を使い捨てにしていた非効率性を指摘し、中間的な洞察を蓄積して再利用する「Recycling Search Experience(RSE)」を提案している。