SONIC-O1: 音声・動画理解におけるマルチモーダル大規模言語モデル評価のための実世界ベンチマーク
マルチモーダル大規模言語モデル(MLLM)の音声・動画理解能力を評価するため、13の実世界ドメインを網羅した4,958件の高品質な注釈付きデータセット「SONIC-O1」が提案されました。 このベンチマークは、要約、多肢選択問題、時間的ローカライゼーションの3つのタスクを通じて、モデルが音声と映像の両方を統合的に理解できているかを厳密に検証し、特に社会的公平性の観点から人口統計学的なメタデータを付与している点が特徴です。 検証の結果、クローズドソースモデルがオープンソースモデルを圧倒し、特に時間的推論において22.6%もの大きな性能差があることや、人種や性別などの属性によってモデルの精度に偏りが生じることが明らかになりました。
TL;DR(結論)
マルチモーダル大規模言語モデル(MLLM)の音声・動画理解能力を評価するため、13の実世界ドメインを網羅した4,958件の高品質な注釈付きデータセット「SONIC-O1」が提案されました。 このベンチマークは、要約、多肢選択問題、時間的ローカライゼーションの3つのタスクを通じて、モデルが音声と映像の両方を統合的に理解できているかを厳密に検証し、特に社会的公平性の観点から人口統計学的なメタデータを付与している点が特徴です。 検証の結果、クローズドソースモデルがオープンソースモデルを圧倒し、特に時間的推論において22.6%もの大きな性能差があることや、人種や性別などの属性によってモデルの精度に偏りが生じることが明らかになりました。
なぜこの問題か
現在のマルチモーダル大規模言語モデル(MLLM)の研究は、主に静止画像の理解や単純な動画のキャプション生成に焦点が当てられており、連続的な音声と動画のデータを統合して処理する能力については十分に探索されていません。現実世界のコミュニケーションにおいては、音声に含まれる感情、強調、ためらい、社会的意図などのパラ言語情報が意味の理解に不可欠ですが、既存のベンチマークの多くは音声を無視したり、単なるテキストの書き起こしや字幕に置き換えたりしています。このようなアプローチでは、話者の感情状態や微妙なニュアンスを捉えることができず、真のオムニモーダルな理解とは言えません。 また、医療、教育、法律、公共安全といった高い信頼性が求められる領域でこれらのモデルを導入する場合、単に能力が高いだけでなく、正確で、透明性があり、かつ公平に動作するかを評価する必要があります。しかし、既存のデータセットには人口統計学的なメタデータが不足しており、ユーザーの属性によってモデルのパフォーマンスが系統的に変化するかどうかを分析することが困難でした。…
核心:何を提案したのか
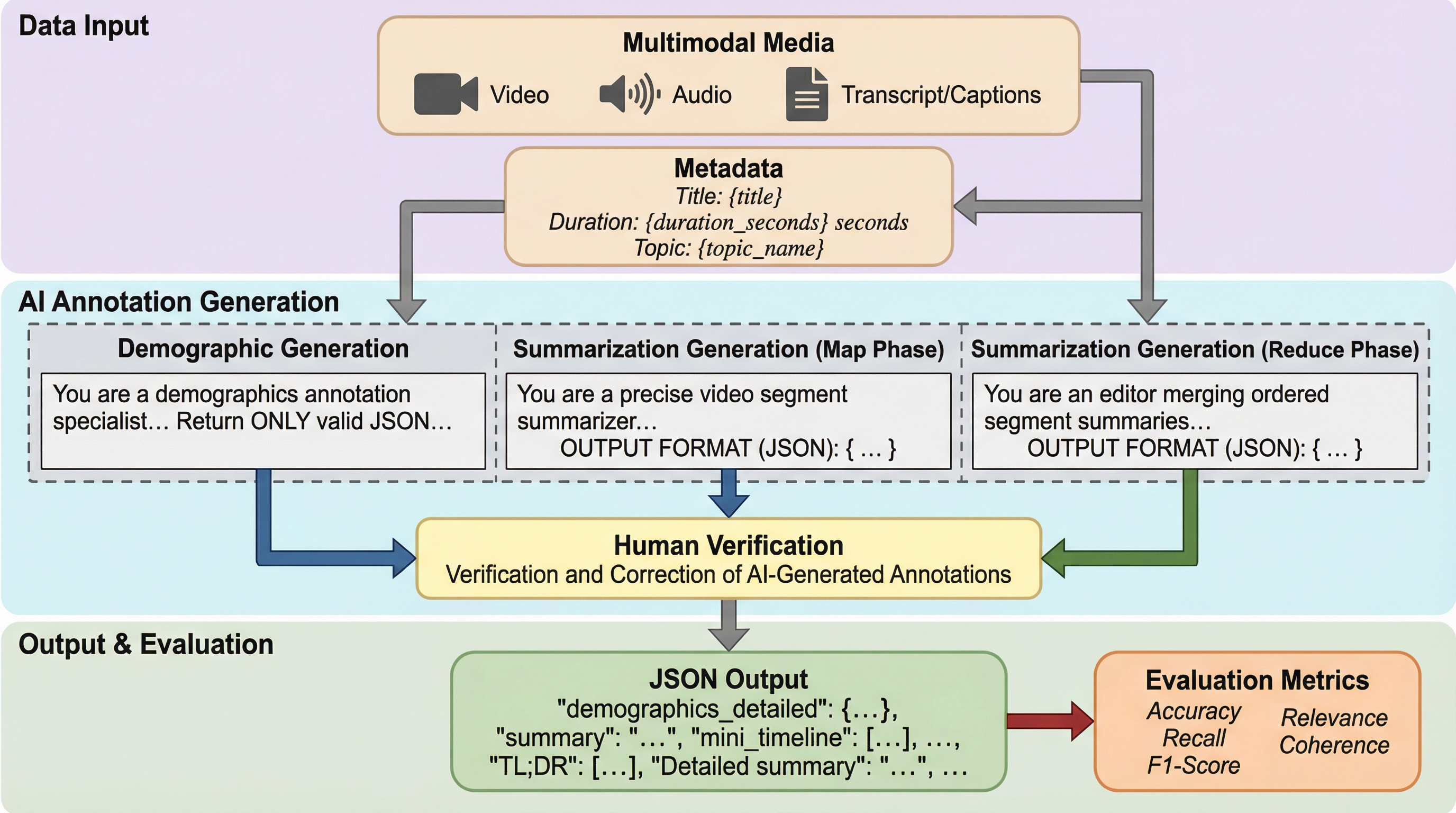
本研究では、実世界の音声・動画相互作用を評価するための新しいベンチマーク「SONIC-O1(Social Natural Interaction Corpus - Omnimodal v1)」を提案しました。このベンチマークは、約60時間に及ぶ実世界の動画から抽出された4,958件の質問と回答のペアで構成されており、そのすべてが人間によって検証されています。対象となる領域は、専門職、教育、法律・市民、サービス、公共・公衆衛生の5つの主要ドメインにわたり、さらに「就職面接」「法廷手続き」「緊急対応」「メンタルヘルス相談」「レストランでの接客」など13の具体的なトピックに細分化されています。 SONIC-O1の最大の特徴は、人種(6グループ)、性別、年齢層といった人口統計学的なメタデータが付与されている点にあり、これによりモデルの公平性をグループごとに分析することが可能です。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related