ScholarGym:学術文献検索における深い研究ワークフローのベンチマーク
従来の深層リサーチワークフローの評価は、ライブAPIの非決定性や検索インデックスの時間的変動、レート制限などの環境的要因により再現性が困難であったが、本研究では57万件の固定コーパスと確定的な検索エンジンを用いたシミュレーション環境「ScholarGym」を開発した。
TL;DR(結論)
従来の深層リサーチワークフローの評価は、ライブAPIの非決定性や検索インデックスの時間的変動、レート制限などの環境的要因により再現性が困難であったが、本研究では57万件の固定コーパスと確定的な検索エンジンを用いたシミュレーション環境「ScholarGym」を開発した。この環境は、ワークフローをクエリ計画、ツール呼び出し、関連性評価の3段階に分離し、2,536件の専門家による注釈付きクエリを用いて、反復的な推論プロセスにおける各コンポーネントの性能を詳細かつ厳密に分析することを可能にしている。検証の結果、反復的な計画は直接検索よりF1スコアを最大3.3倍向上させ、特に「思考拡張型」モデルは適合率を重視する傾向がある一方で、オープンソースモデルには関連性評価の精度において商用モデルと大きな隔たりがあることが明らかになった。
なぜこの問題か
大規模言語モデル(LLM)の活用は、単発の質問応答から、複雑な情報ニーズに応えるためにクエリを反復的に計画し、外部ツールを呼び出し、得られた情報を統合する「深層リサーチワークフロー」へと進化を遂げている。しかし、このような高度なワークフローを評価する際には、解決すべき根本的な課題が存在する。既存の評価手法の多くはライブAPIに依存しているが、これは非決定性を導入する原因となる。具体的には、検索インデックスの時間的な変動(テンポラル・ドリフト)や、APIのレート制限による不完全な応答、さらにはバックエンドの状態変化によってランキング挙動が変わるため、同じツール呼び出しを行っても実行ごとに異なる結果が得られてしまう。このような分散は、研究の再現性を著しく損なわせ、異なるシステム間での公正な比較を不可能にする。 学術文献の検索においては、引用ネットワークの密度や専門用語の特殊性、領域専門知識を必要とする関連性判断など、特有の困難が伴う。既存のベンチマークでは、モデル自体の能力不足ではなく、スクレイピング防止機能やURLのタイムアウトといった環境的なノイズによって評価が失敗することも報告されている。…
核心:何を提案したのか
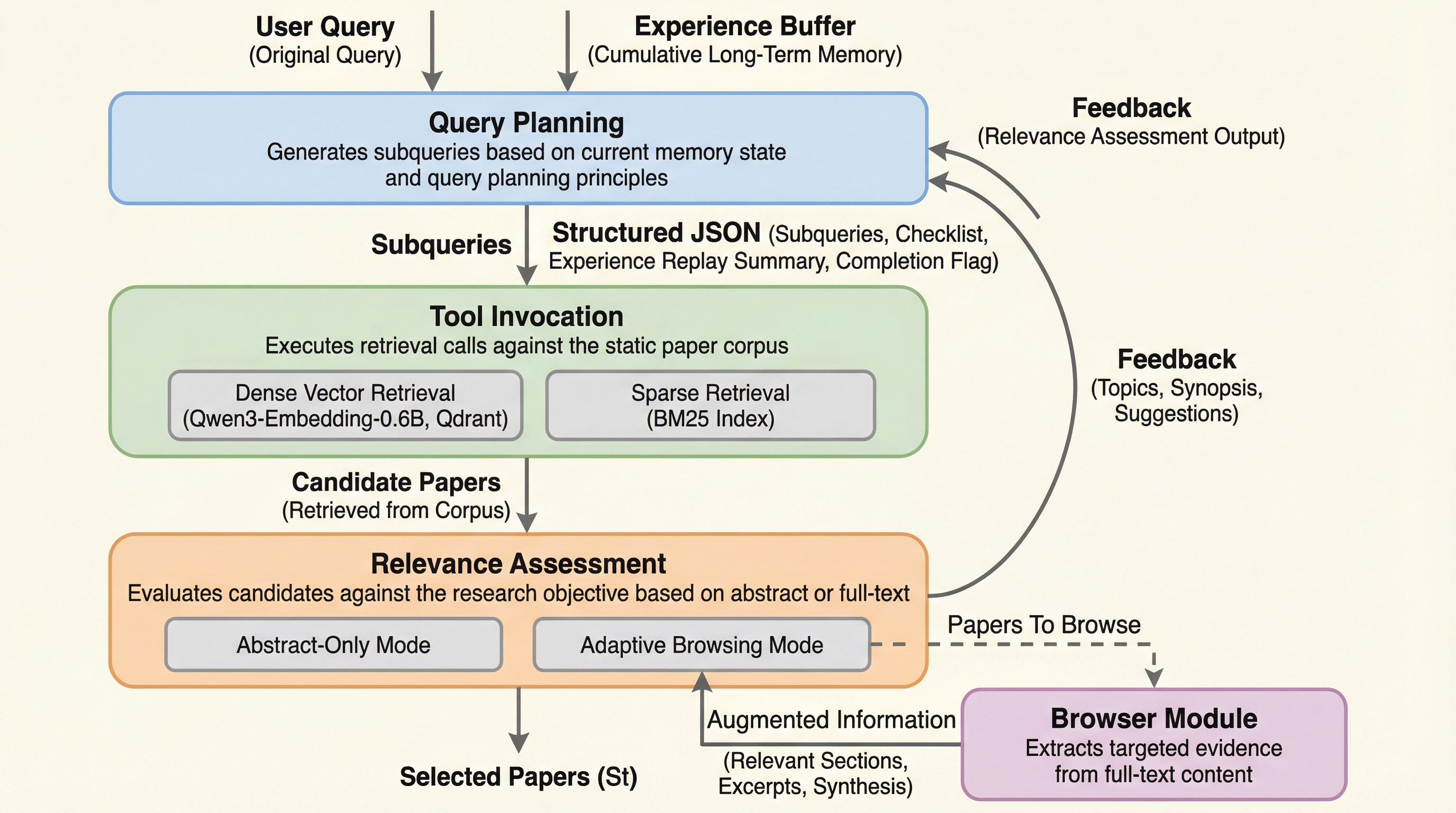
本研究では、学術文献を対象とした深層リサーチワークフローの再現可能な評価を可能にするシミュレーション環境「ScholarGym」を提案した。この環境の核心は、不安定なライブAPIを、57万件の論文からなる静的なコーパスと確定的な検索エンジンに置き換えることで、環境由来のノイズを完全に排除した点にある。ScholarGymは、ワークフローを「クエリ計画」「ツール呼び出し」「関連性評価」という3つの独立したモジュール段階に分離しており、各段階の性能を詳細な粒度で分析できる設計となっている。これにより、研究者はシステム全体の性能だけでなく、どのコンポーネントがボトルネックになっているかを正確に特定することが可能になった。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related