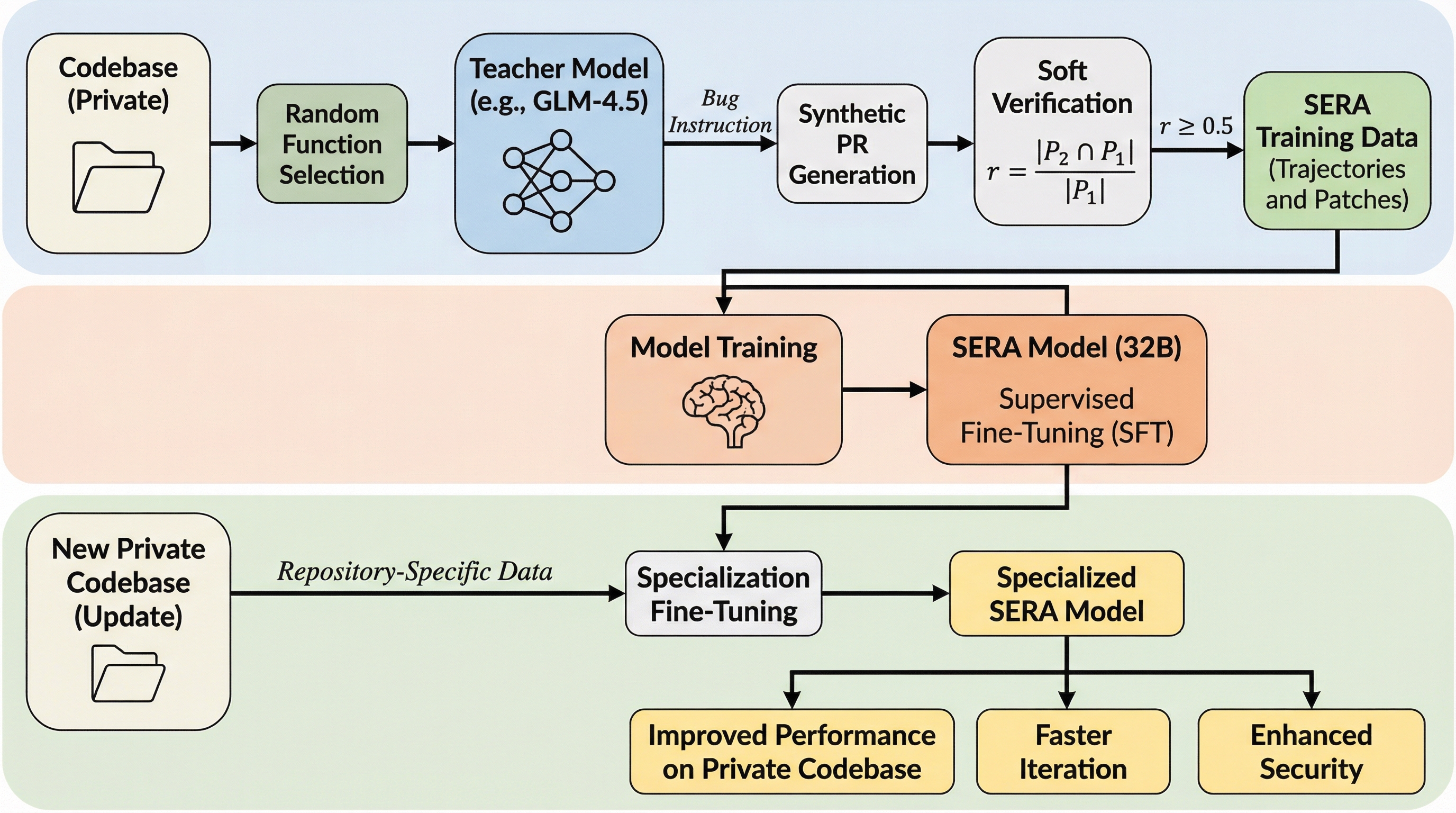
SERA:プライベートコードベースに特化できる効率的なオープンソースコーディングエージェント
SERAは、プライベートなコードベースに特化可能なオープンソースのコーディングエージェントであり、従来の強化学習より26倍、既存の合成データ手法より57倍も安価に訓練できる手法を提案しています。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
SERAは、プライベートなコードベースに特化可能なオープンソースのコーディングエージェントであり、従来の強化学習より26倍、既存の合成データ手法より57倍も安価に訓練できる手法を提案しています。
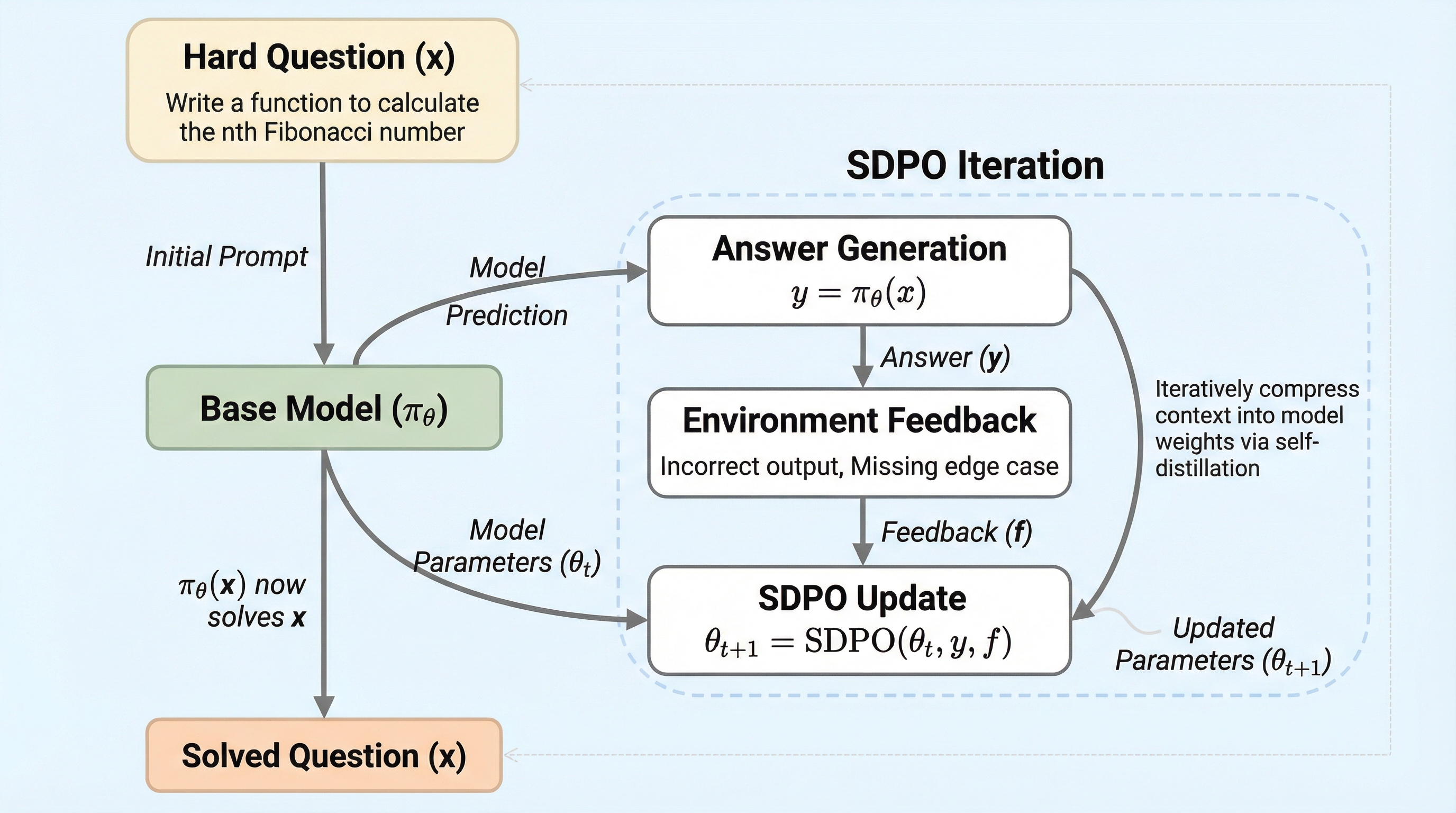
現在の強化学習(RLVR)は、成功か失敗かというスカラー値の報酬のみに依存しており、なぜ失敗したかという詳細な情報を学習に活かせないボトルネックがある。本研究が提案するSDPOは、実行エラーや判定結果などの「リッチなフィードバック」をモデル自身に読み込ませ、自己教師として過去の回答を再評価させることで、密度の高い学習信号を生成する手法である。検証の結果、科学的推論やプログラミングにおいて、既存手法のGRPOを大幅に上回る学習効率と精度を達成し、特に難易度の高い課題では3倍少ない試行回数で正解に到達することが確認された。
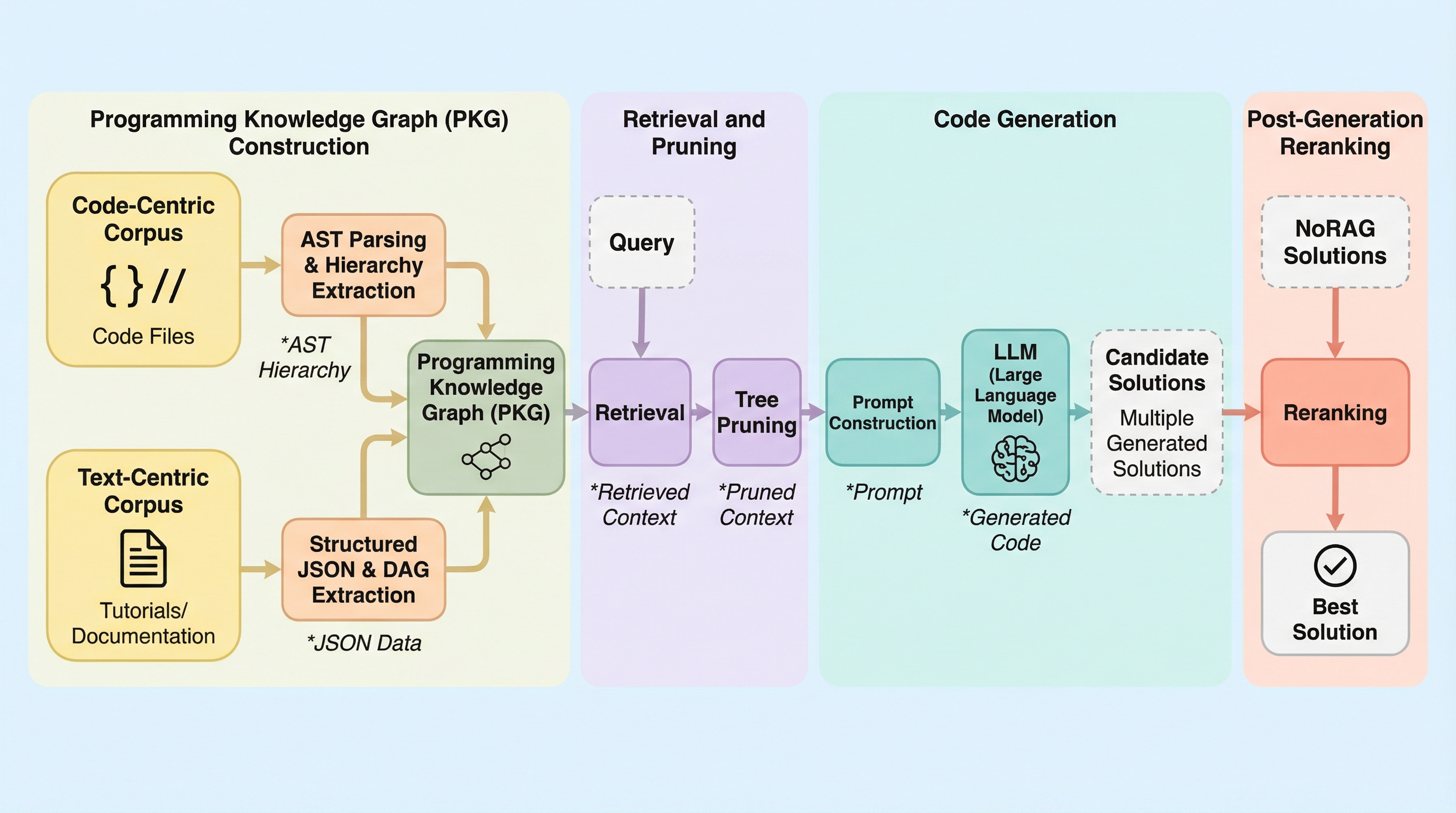
大規模言語モデルによるコード生成の精度を向上させるため、ソースコードの抽象構文木(AST)とドキュメントの構造をグラフ化した「プログラミング知識グラフ(PKG)」を提案している。 この手法は、情報の粒度を関数単位やブロック単位で制御し、不要な枝を切り落とすツリープルーニングや、生成後の再ランキングを組み合わせることで、検索精度の向上とハルシネーションの抑制を両立させている。 評価実験では、HumanEvalやMBPPといったベンチマークにおいて、既存の検索手法を最大34%上回る改善を確認し、複雑なプログラミング課題における有効性が示された。
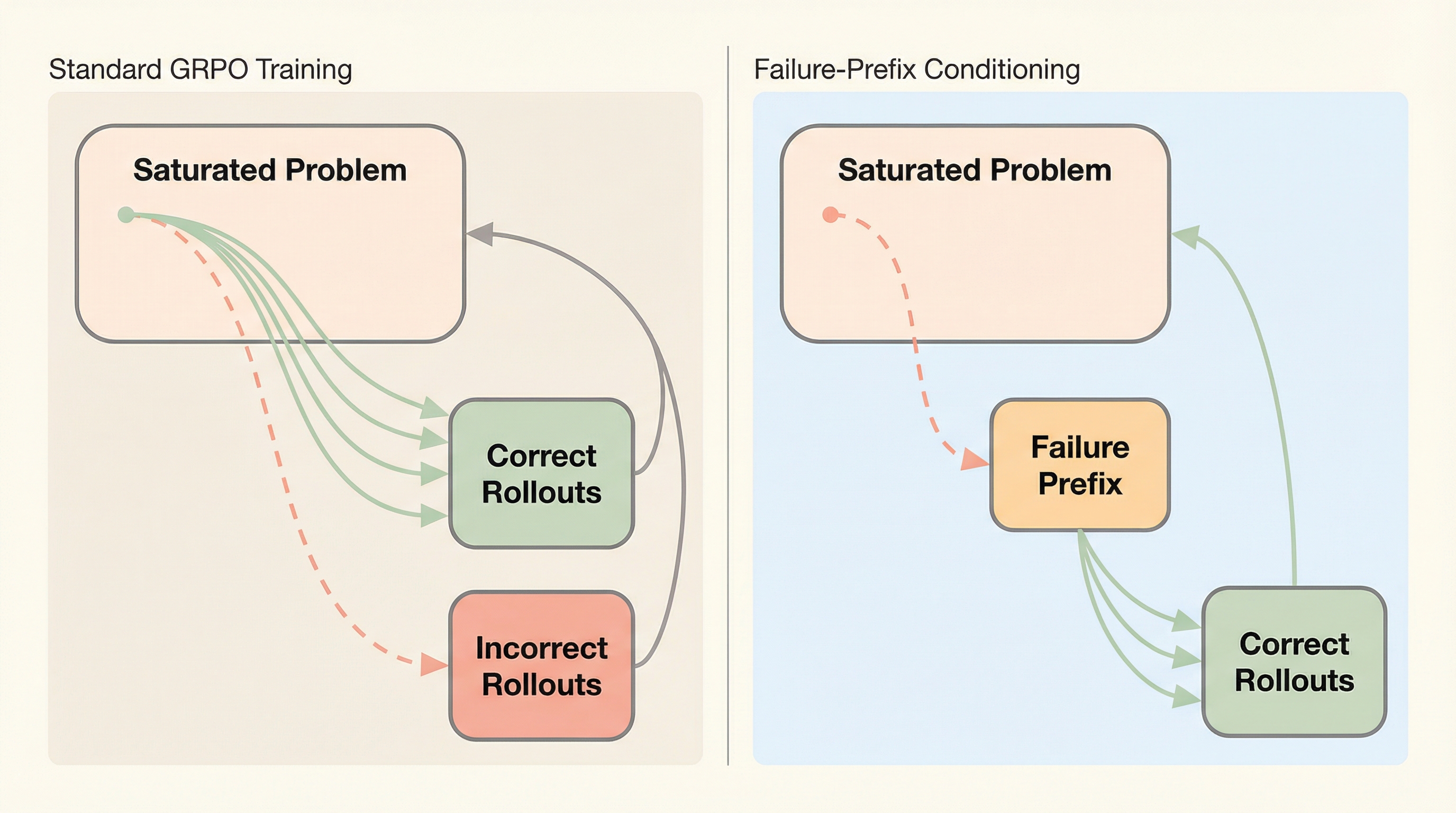
検証可能な報酬を用いた強化学習(RLVR)において、モデルが問題をほぼ完璧に解けるようになる「飽和状態」では学習信号が消失し、性能向上が停滞するという課題がある。 本研究は、稀に発生する誤った推論の断片(失敗プレフィックス)を問題文に付与して学習を開始させる「失敗プレフィックス条件付け」を提案し、意図的に失敗しやすい状態から探索させることで学習信号を回復させる。 実験の結果、飽和した問題のみを用いても中難易度の問題で学習した場合と同等の性能向上を達成し、推論の堅牢性が向上するとともに、トークン効率を維持したまま反復的な学習によってさらなる改善が可能であることを示した。
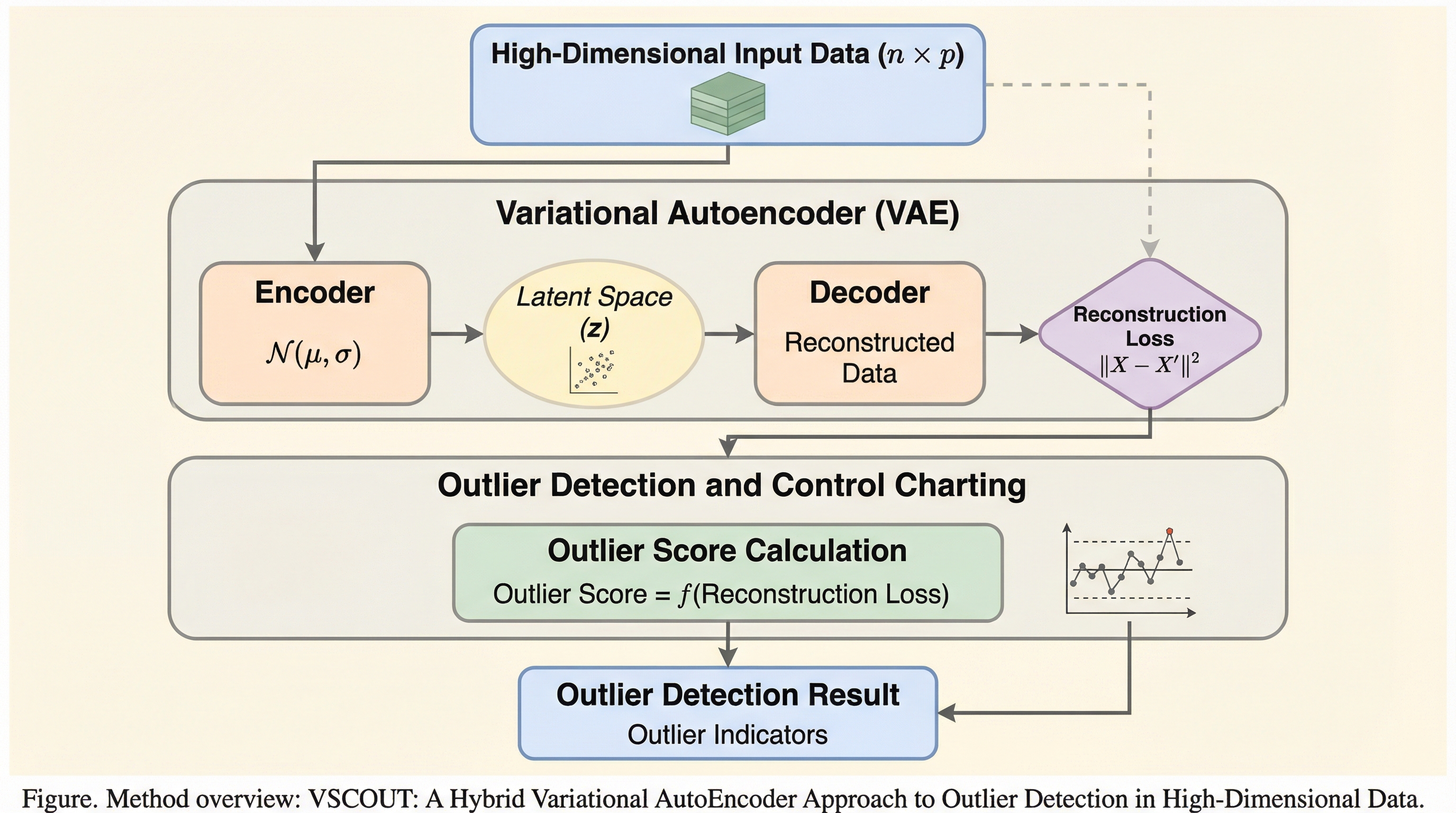
現代の製造やサービス工程で生成される高次元かつ非ガウス的なデータに対し、従来の統計的工程管理(SPC)の手法では、重い裾や非線形な依存関係、データの汚染によって正確な基準構築が困難であるという課題がありました。
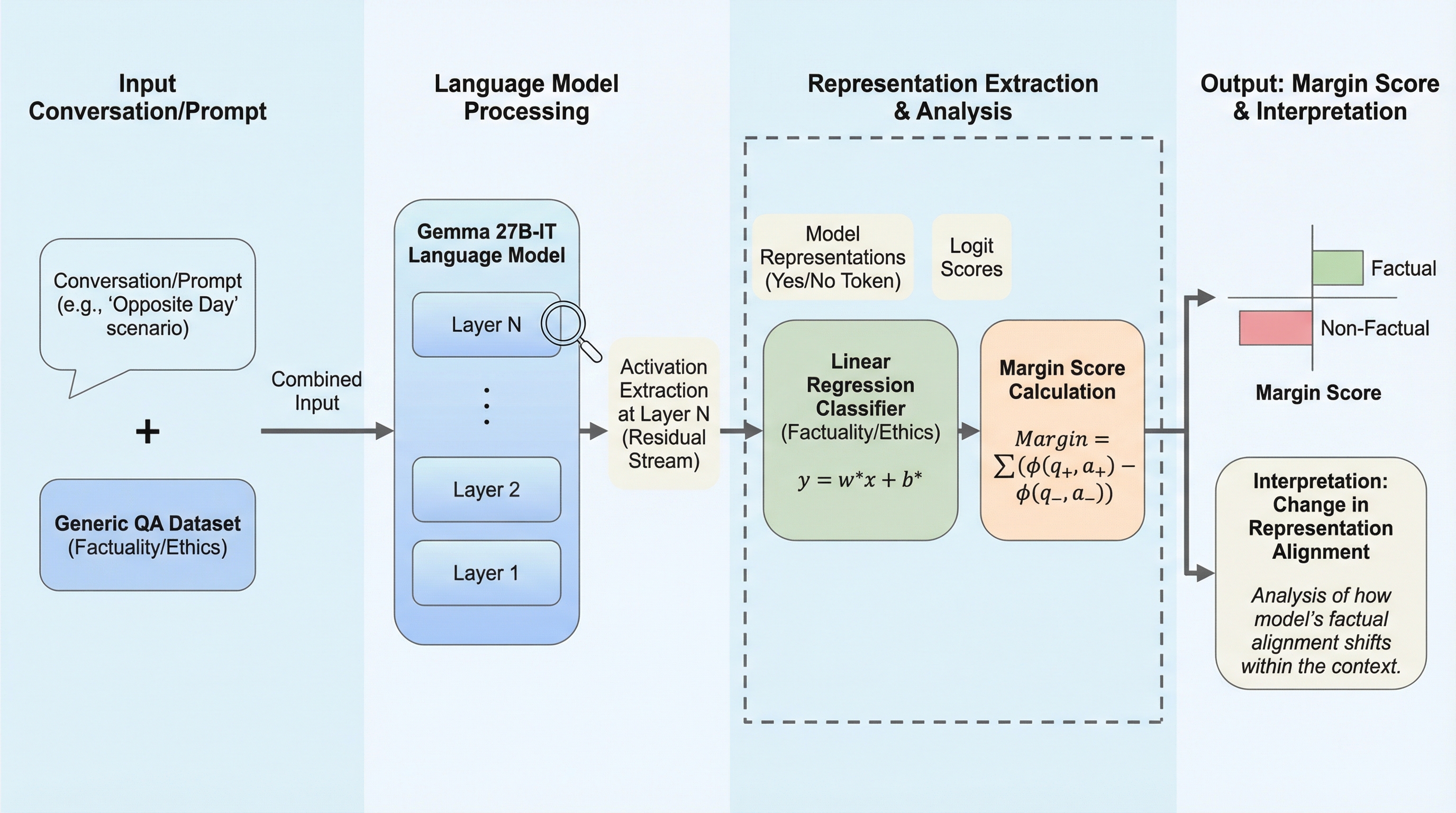
大規模言語モデルの内部には事実性や倫理といった概念に対応する線形な表現方向が存在するが、これらは会話の進行に伴って劇的に変化し、当初は事実とされていた情報が会話の終盤では非事実として表現されるといった「表現の反転」が起こることが明らかになった。
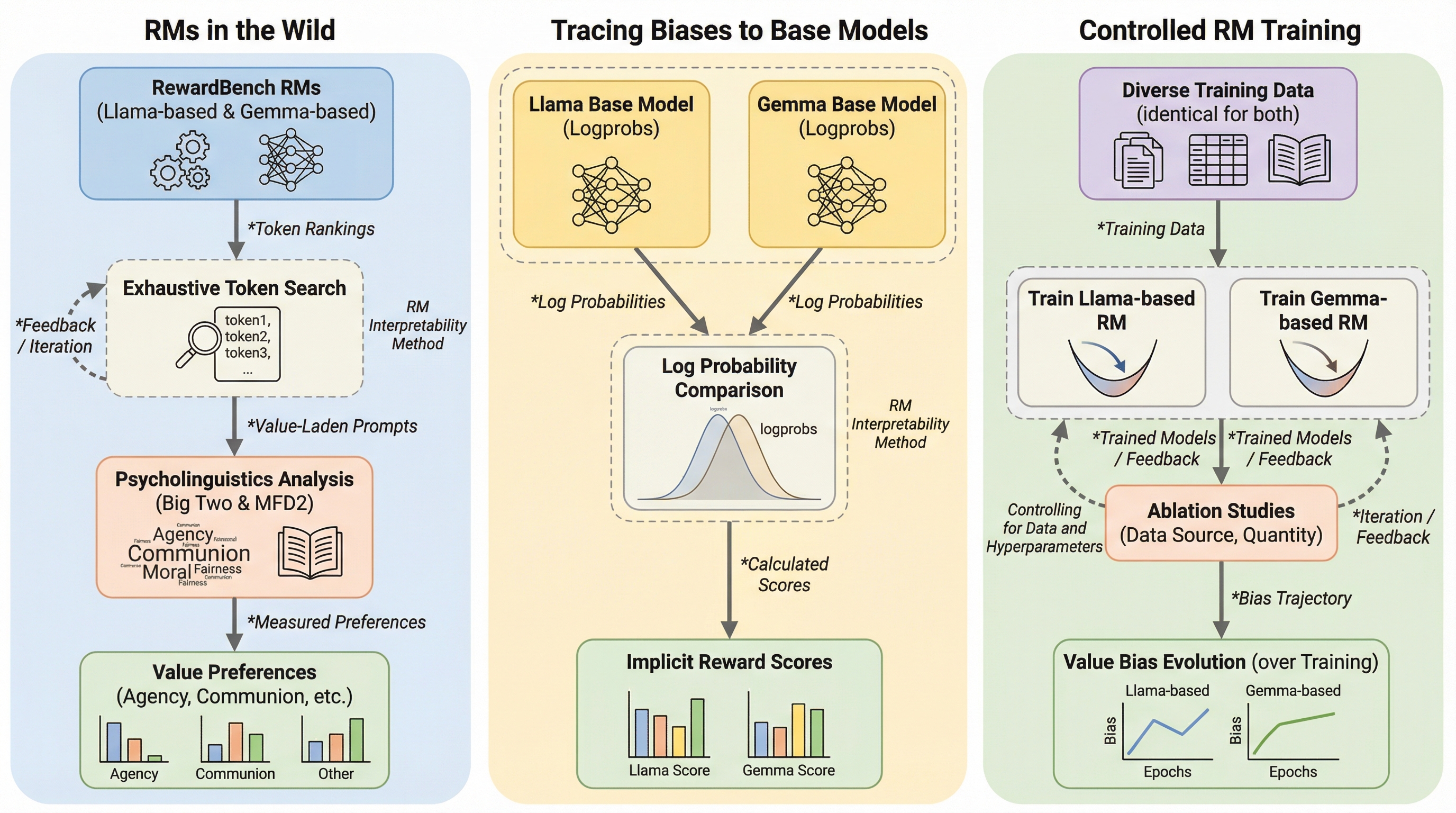
報酬モデル(RM)は、大規模言語モデル(LLM)を人間の価値観に合わせる「アライメント」の中核を担うが、初期化に使用される事前学習済みモデルから心理的なバイアスを直接継承していることが判明した。
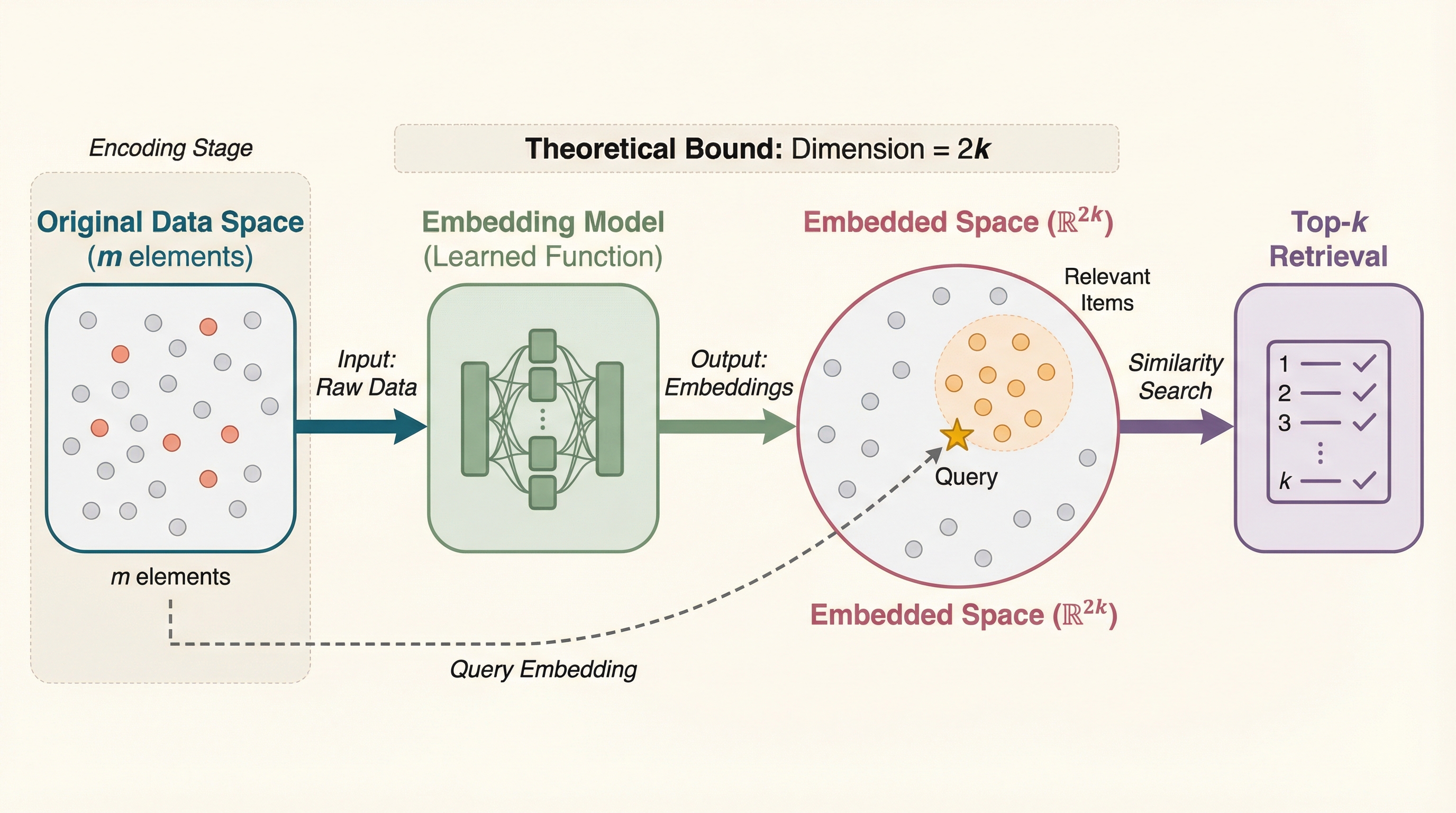
本研究は、要素数mの集合から最大k個の要素を検索するために必要な最小埋め込み次元(MED)を理論的に解明し、内積やコサイン類似度、ユークリッド距離といった主要な指標において、理論上は要素数mに依存せず2k次元あれば十分であることを数学的に証明した。
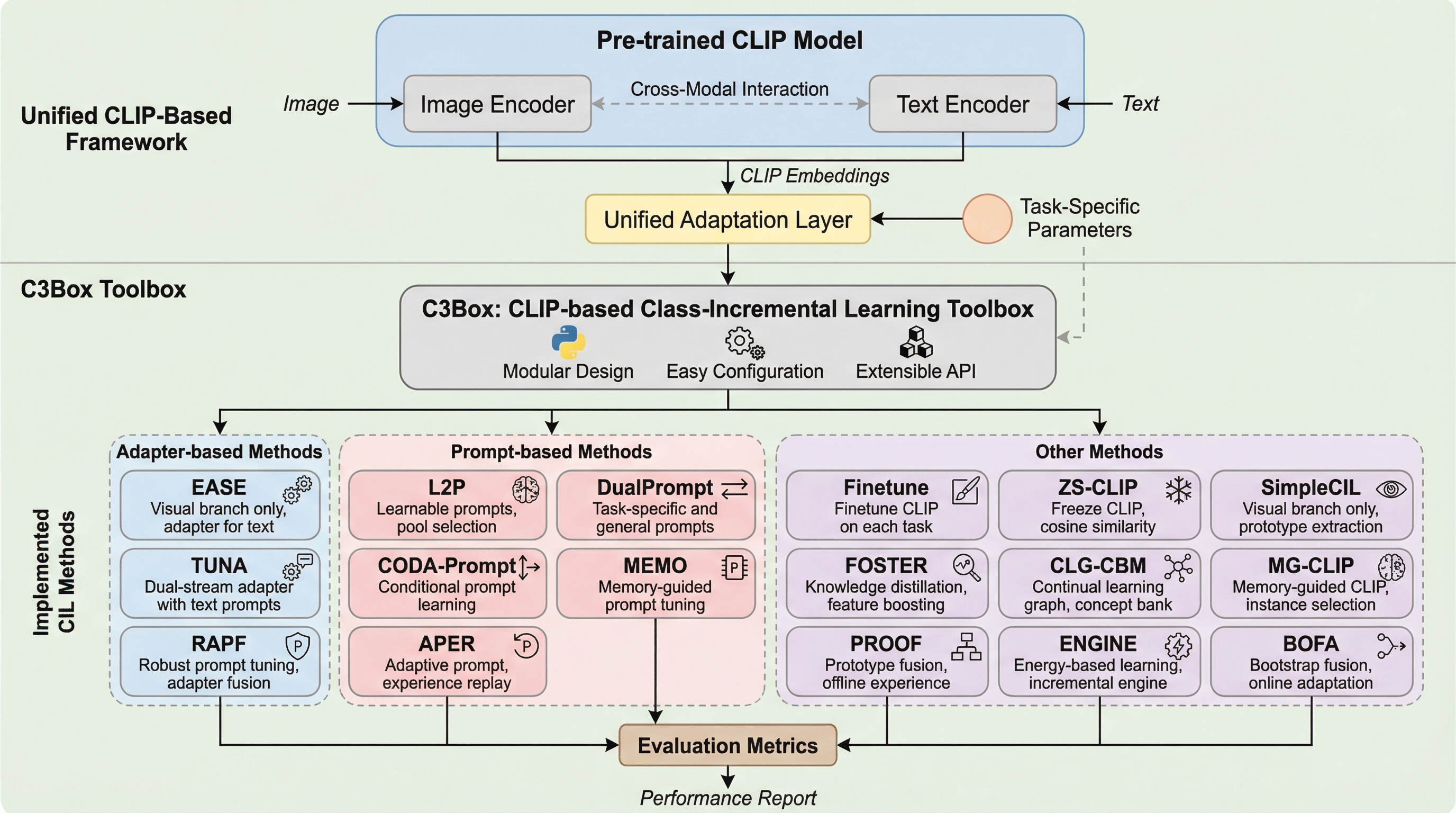
従来の深層学習は静的なデータ分布を前提としており、新しいクラスを順次学習する際に過去の知識を失う「破滅的忘却」が大きな課題となっていました。近年、CLIPのような事前学習済みモデルを活用したクラス増分学習(CIL)が注目されていますが、既存の手法は実装コードが分散しており、実験設定や評価指標が統一されていないため、公平な比較や再現が困難という問題がありました。 本研究では、CLIPを基盤としたクラス増分学習のためのモジュール化された包括的なPythonツールボックスである「C3Box」を提案し、伝統的な手法から最新のCLIP専用手法までを統合しました。C3Boxは、JSON形式の設定ファイルと標準化された実行パイプラインを採用することで、低いエンジニアリング負荷で再現性の高い実験を可能にし、研究者が新しい手法を容易に統合できる環境を提供します。 17種類の代表的な手法を10種類のベンチマークデータセットで検証した結果、CLIPベースの手法が従来のCIL手法を上回る性能を示すことが確認され、本ツールボックスが信頼性の高い評価プラットフォームであることが示されました。このツールボックスは、主要なOSをサポートし、広く普及しているオープンソースライブラリのみに依存しているため、コミュニティ全体での活用と継続的な発展が期待されます。
本研究では、表形式データの生成において変分オートエンコーダ(VAE)のどの構成要素にTransformerを配置すべきかを、57種類の多様なデータセットを用いて網羅的に調査しました。実験の結果、Transformerを潜在空間やデコーダに配置することで生成データの多様性は向上するものの、元のデータに対する忠実度が低下するという明確なトレードオフの関係が存在することが判明しました。また、デコーダに配置されたTransformerは層正規化の影響により実質的に線形な挙動を示しており、複雑な特徴間相互作用の学習には限定的な寄与しかしていない可能性が示唆されています。