ShardMemo: Masked MoEルーティングを用いたエージェント向け分散メモリ管理
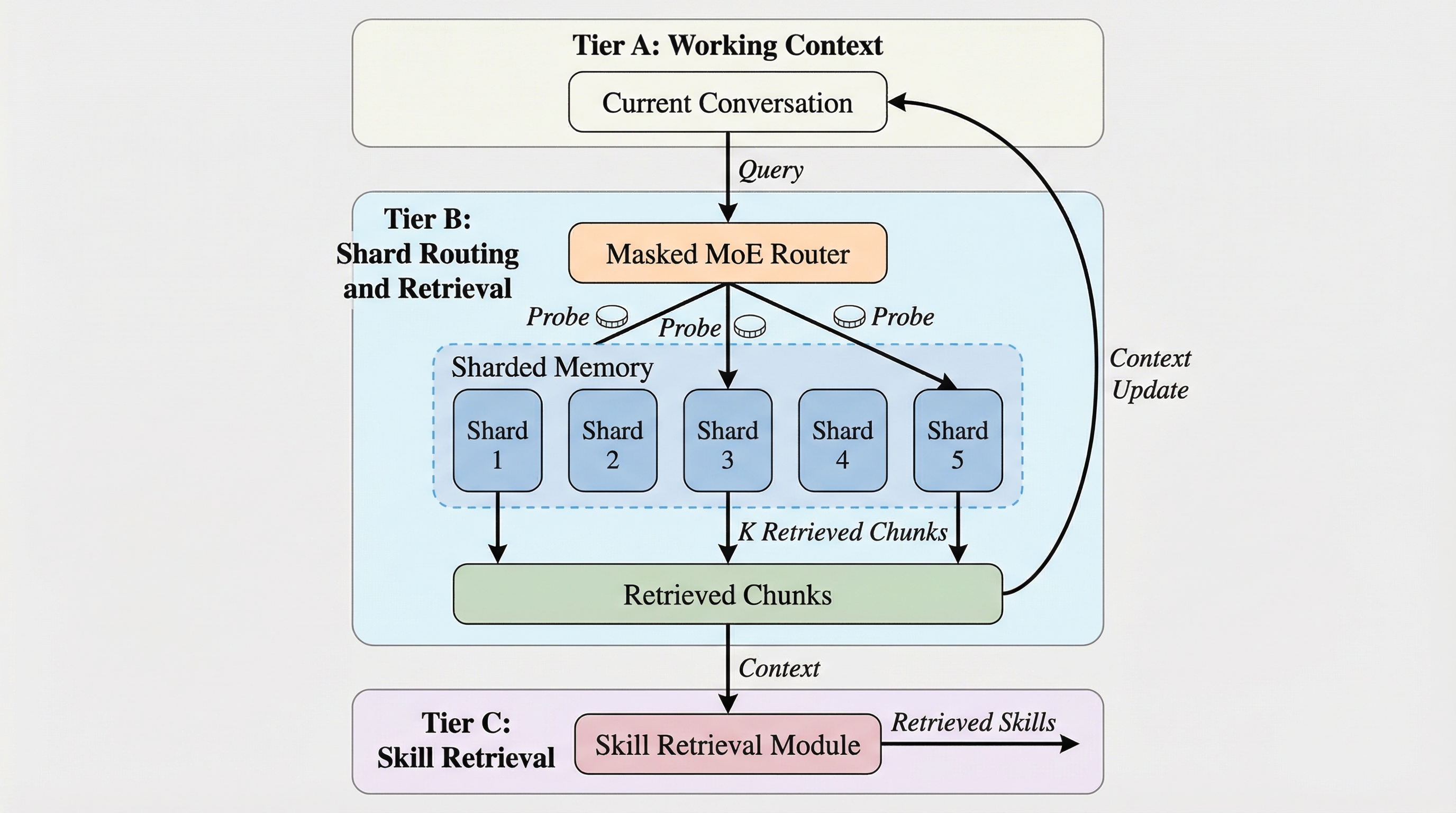
エージェント型LLMシステムにおいて、メモリ量の増大と並列アクセスの増加に伴う中央集権的なインデックスのボトルネックを解消するため、3層構造の予算制約付きメモリサービスであるShardMemoが提案されました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
エージェント型LLMシステムにおいて、メモリ量の増大と並列アクセスの増加に伴う中央集権的なインデックスのボトルネックを解消するため、3層構造の予算制約付きメモリサービスであるShardMemoが提案されました。
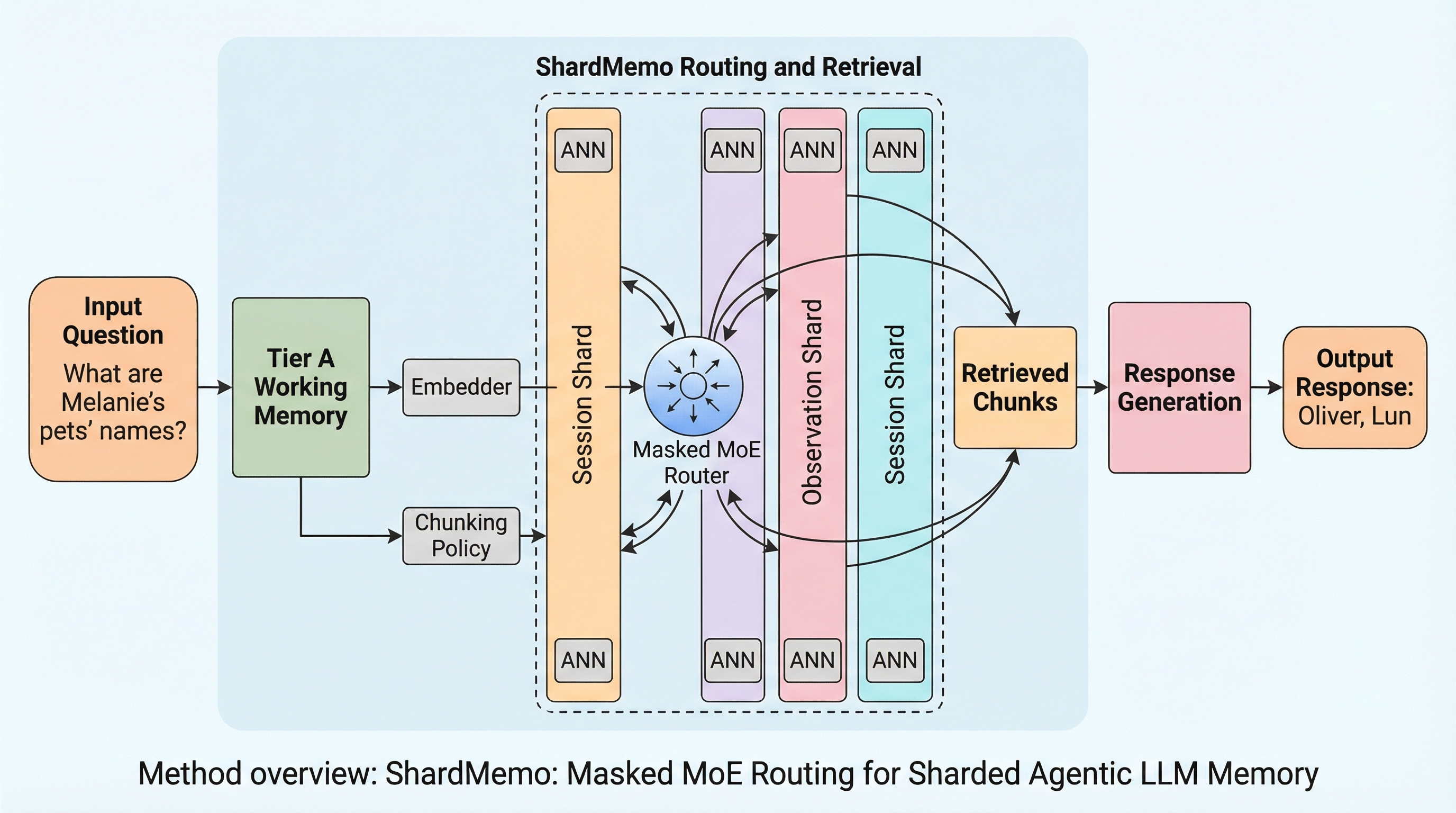
ShardMemoは、エージェント型LLMのために設計された階層型メモリサービスであり、作業状態(Tier A)、シャード化された証拠(Tier B)、スキルライブラリ(Tier C)の3層構造によって、大規模なメモリへの効率的なアクセスを実現します。
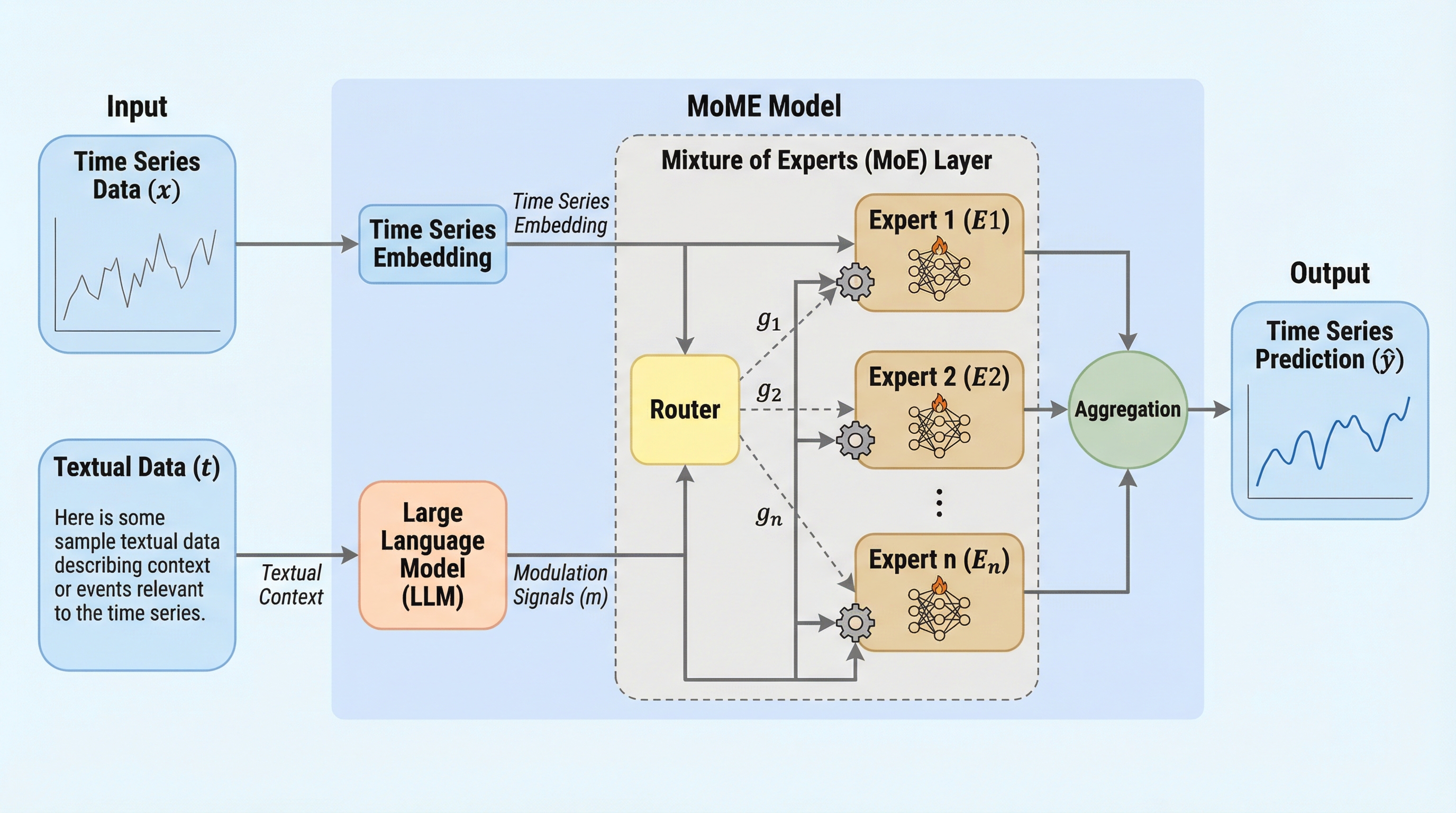
従来のマルチモーダル時系列予測で主流だった、数値データとテキストデータを共通の潜在空間で直接混ぜ合わせる「トークンレベルの融合」に代わり、テキスト情報を用いて時系列エキスパートの計算とルーティングを直接制御する「エキスパート変調(Expert Modulation)」という新しいパラダイムを提案した。
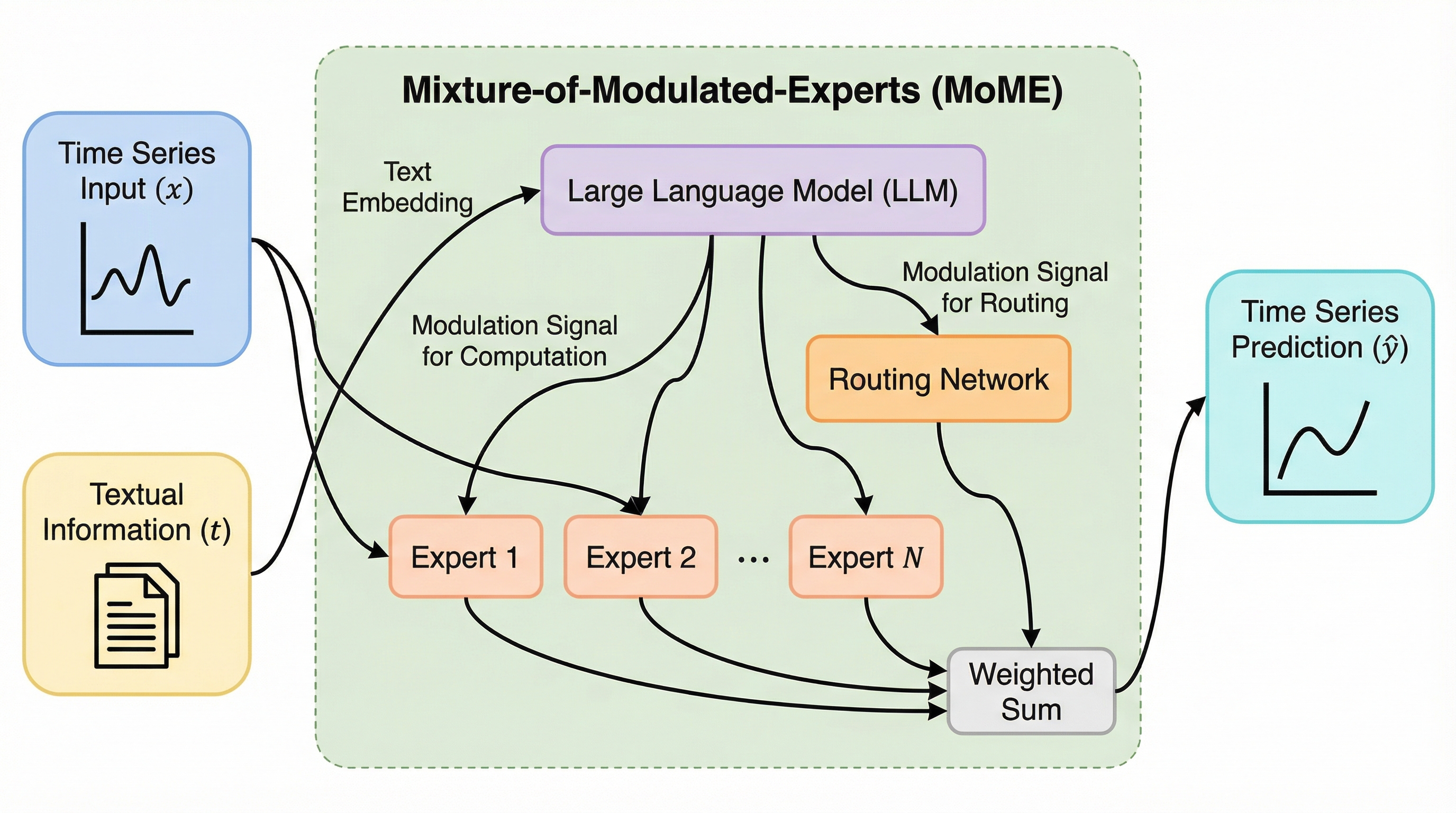
現実世界の時系列予測において、数値データとニュース等のテキスト情報を統合する際、従来のトークンレベルの融合ではノイズやデータの異質性が課題となっていたが、本研究ではテキスト信号が専門家(エキスパート)の選択と計算を直接制御する「Expert Modulation」という新しい枠組みを提案した。
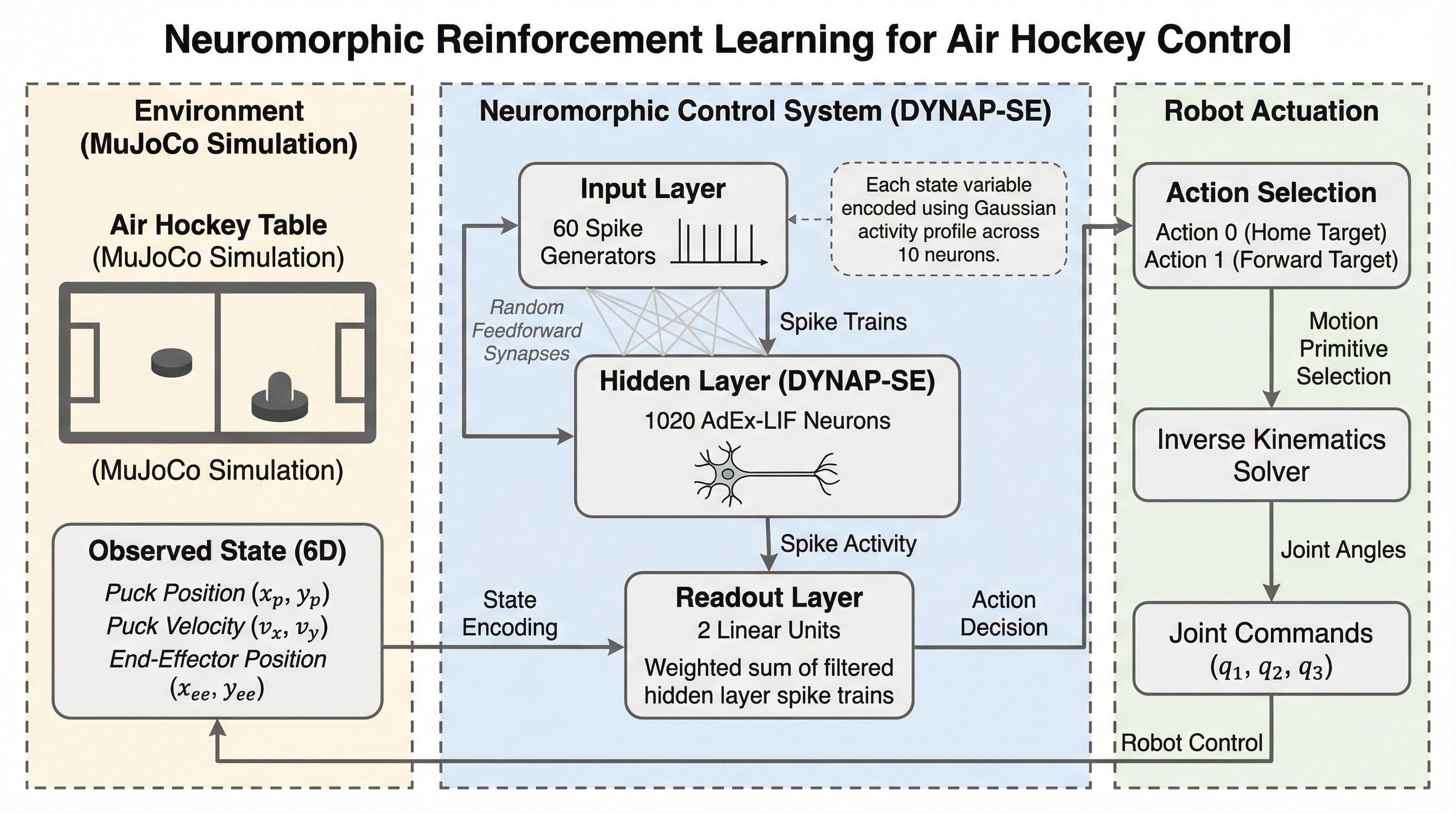
本研究は、ミリ秒単位の判断が求められる高速なエアホッケー競技において、アナログとデジタルの混合信号を扱う「DYNAP-SE」ニューロモーフィック・プロセッサを用いたスパイキングニューラルネットワーク(SNN)による制御を実現しました。
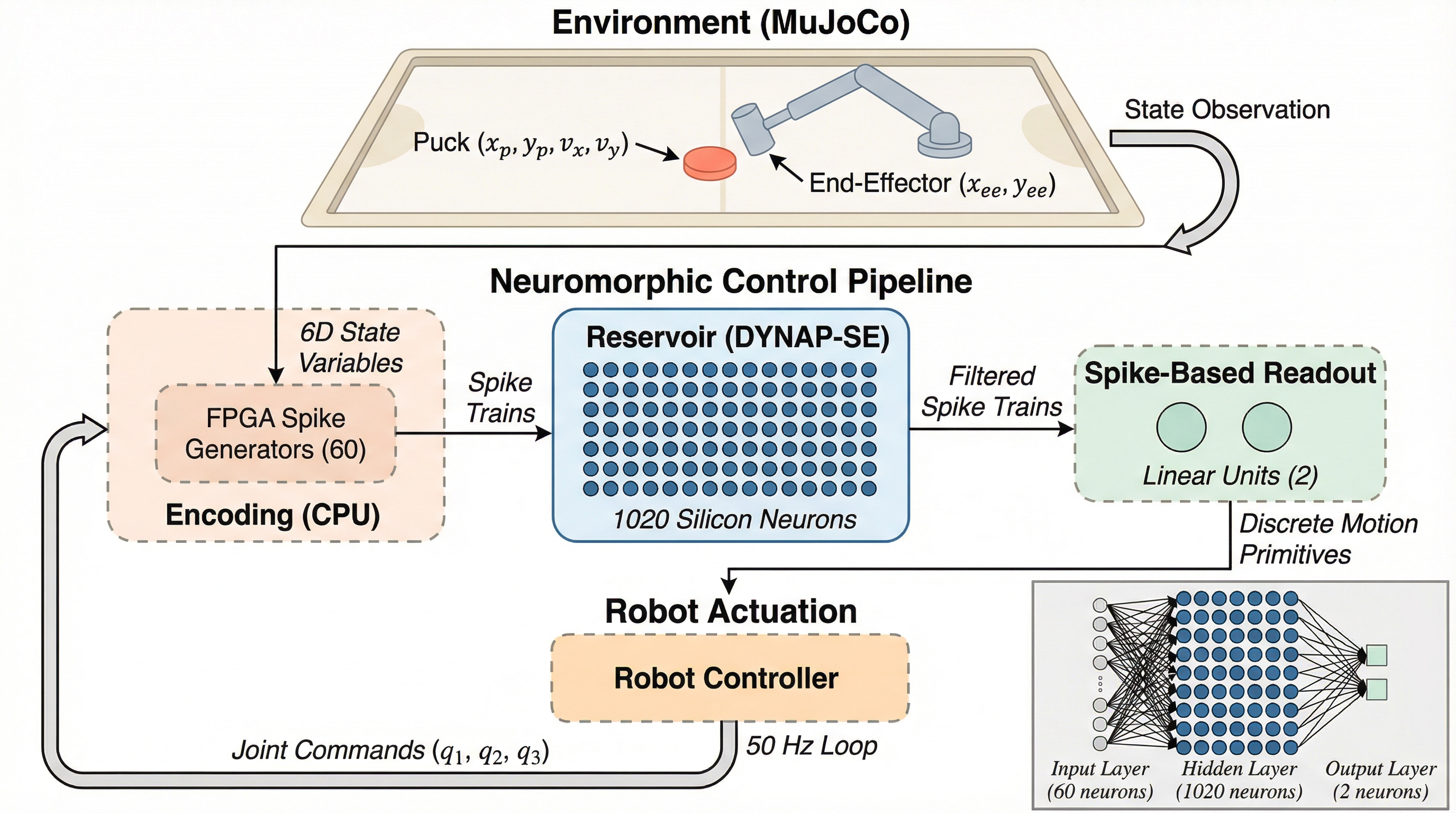
本研究は、低消費電力なアナログ・デジタル混在型ニューロモーフィック・プロセッサであるDYNAP-SEを活用し、極めて高速な意思決定が要求されるエアホッケー・ロボットの制御をスパイク強化学習によって実現した。
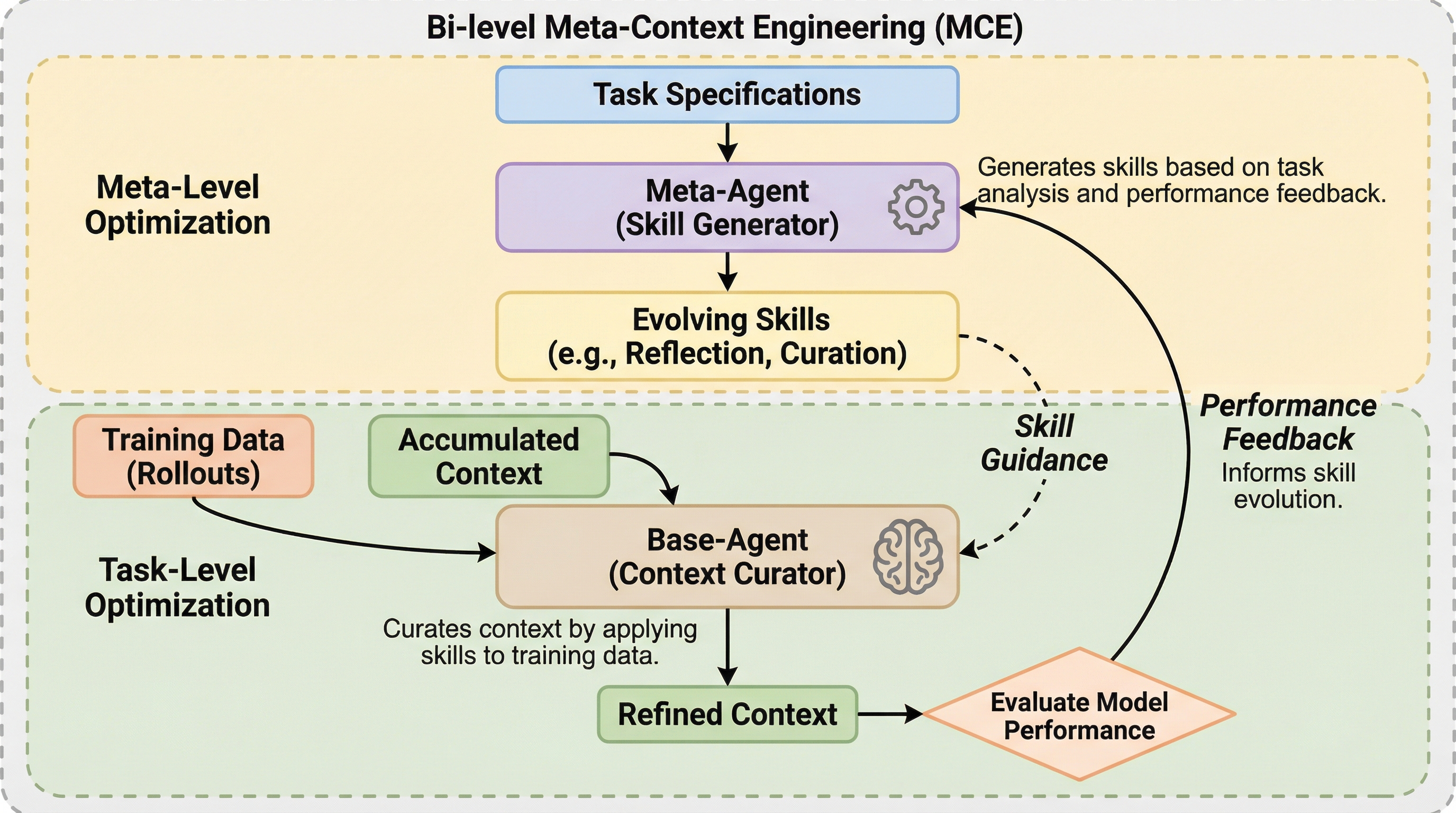
大規模言語モデル(LLM)の推論性能を最大化するため、文脈(コンテキスト)の構成方法そのものをAIエージェントに自律進化させる二段階の最適化フレームワーク「Meta Context Engineering(MCE)」が提案されました。
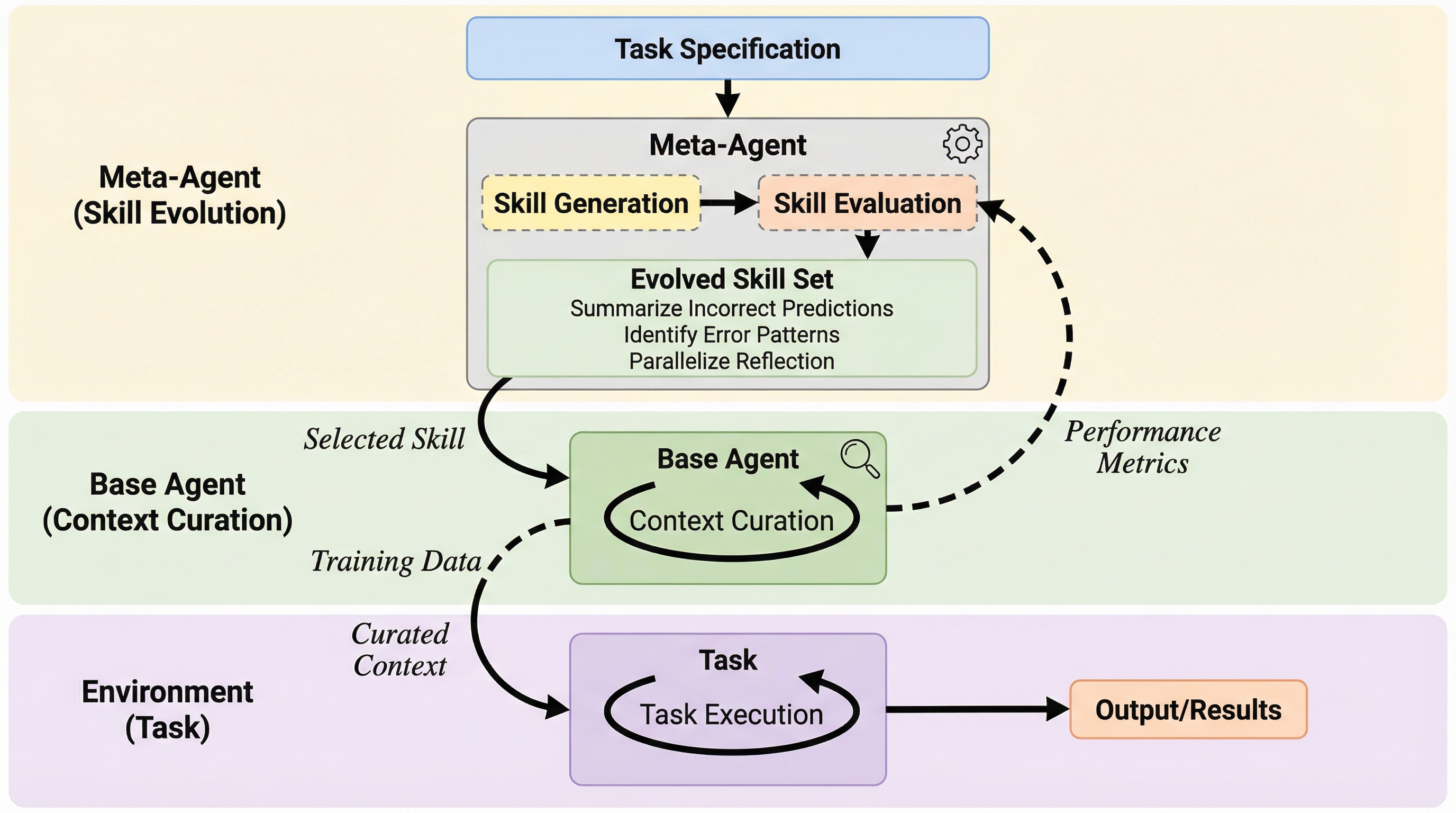
従来のコンテキストエンジニアリングは人間が設計した固定的なワークフローやスキーマに依存しており、構造的な偏りや設計空間の制限が課題であったが、本研究ではエンジニアリングスキルと成果物を共に進化させる「メタコンテキストエンジニアリング(MCE)」を提案した。
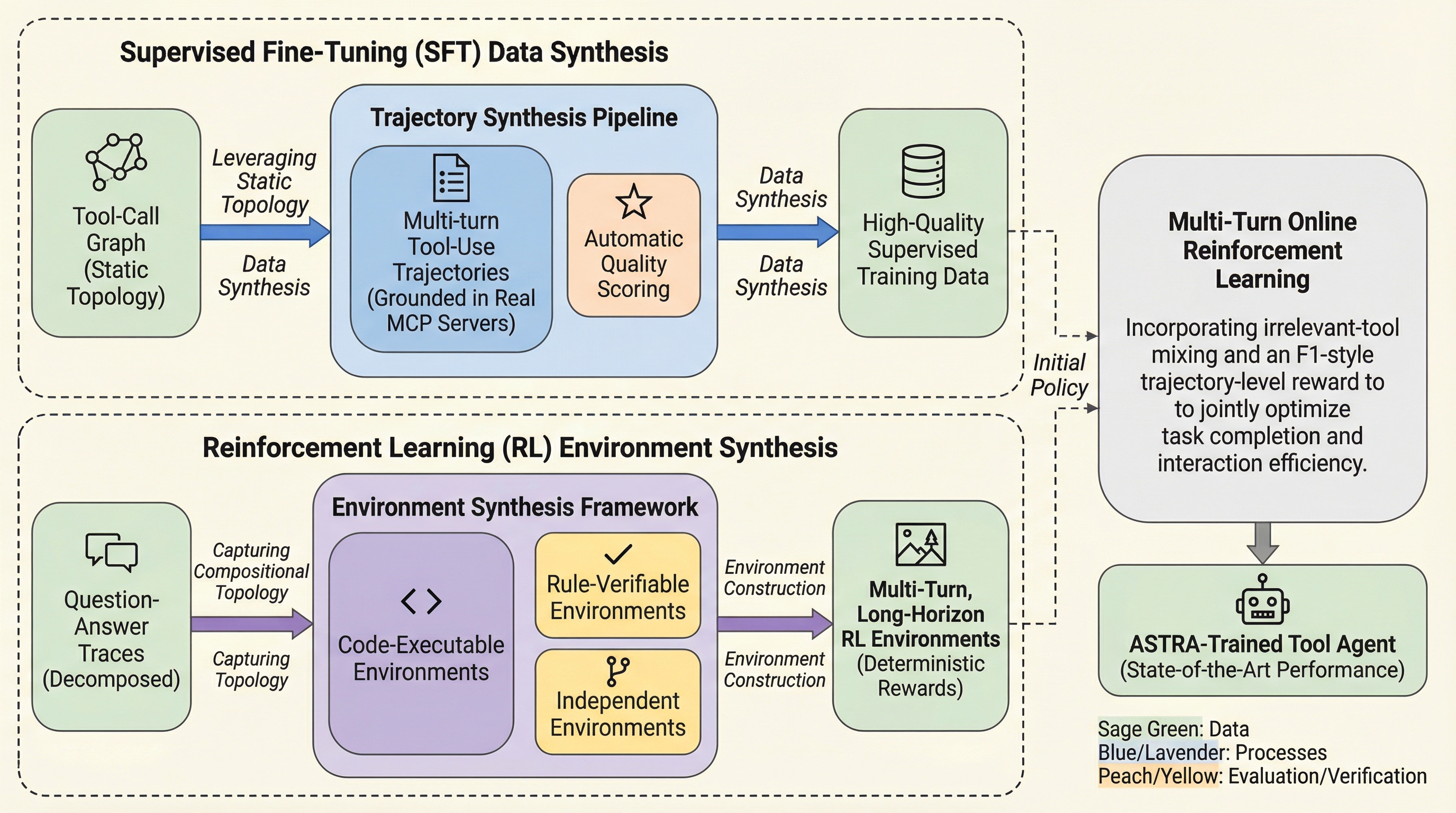
ASTRAは、ツールを利用する言語モデルエージェントの訓練を完全に自動化するエンドツーエンドのフレームワークであり、大規模なデータ合成とルール検証可能な強化学習を統合することで、人間の介入を排除した効率的な学習を実現しました。
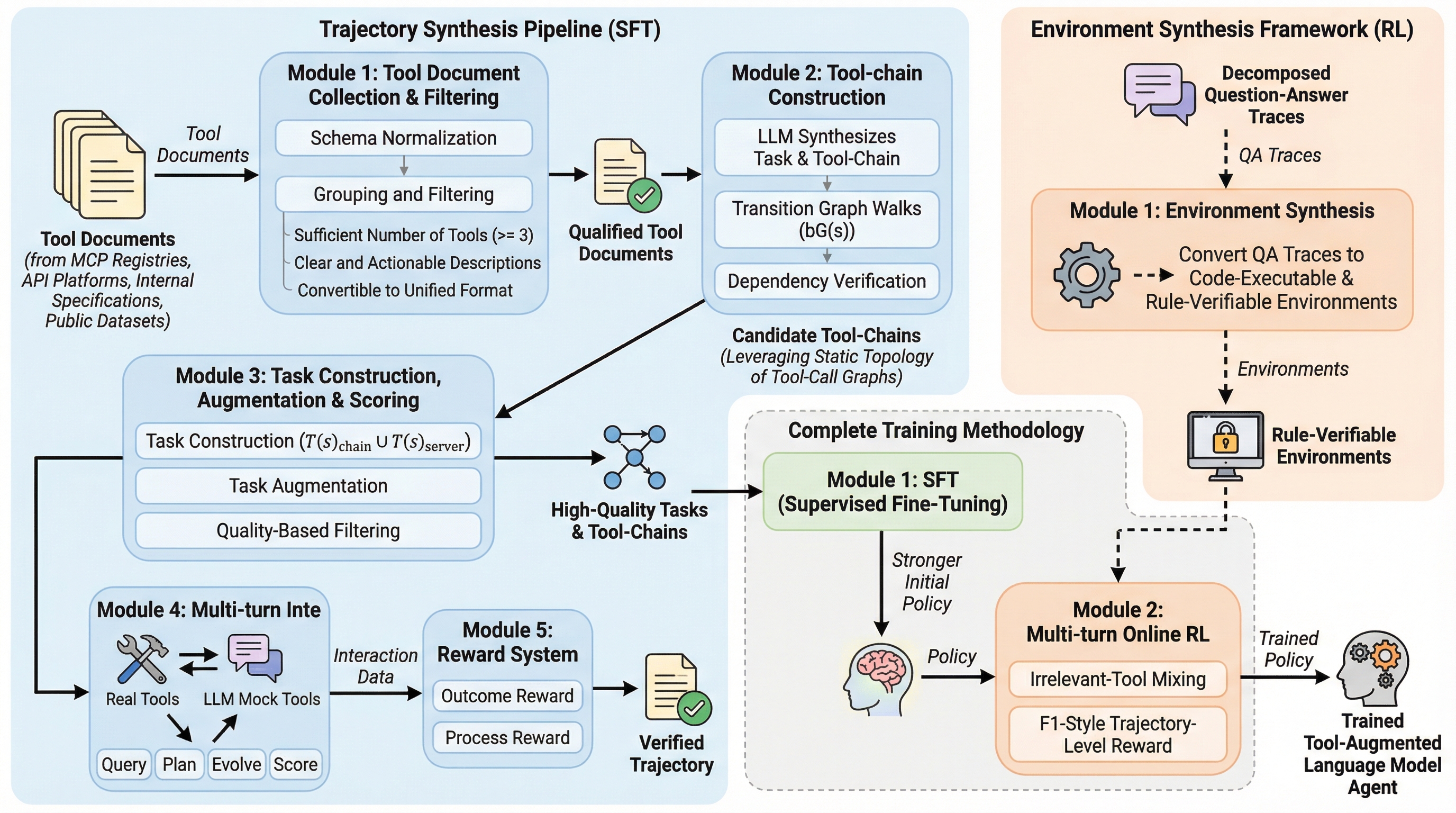
ASTRAは、ツール利用エージェントの訓練を完全に自動化するエンドツーエンドのフレームワークであり、大規模なデータ合成と検証可能な強化学習を統合することで、従来の手動介入や不確実なシミュレーション環境への依存を排除している。